 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models at the Frontier of Compression: A Survey on Generative Face Video Coding
Jun 09, 2025The rise of deep generative models has greatly advanced video compression, reshaping the paradigm of face video coding through their powerful capability for semantic-aware representation and lifelike synthesis. Generative Face Video Coding (GFVC) stands at the forefront of this revolution, which could characterize complex facial dynamics into compact latent codes for bitstream compactness at the encoder side and leverages powerful deep generative models to reconstruct high-fidelity face signal from the compressed latent codes at the decoder side. As such, this well-designed GFVC paradigm could enable high-fidelity face video communication at ultra-low bitrate ranges, far surpassing the capabilities of the latest Versatile Video Coding (VVC) standard. To pioneer foundational research and accelerate the evolution of GFVC, this paper presents the first comprehensive survey of GFVC technologies, systematically bridging critical gaps between theoretical innovation and industrial standardization. In particular, we first review a broad range of existing GFVC methods with different feature representations and optimization strategies, and conduct a thorough benchmarking analysis. In addition, we construct a large-scale GFVC-compressed face video database with subjective Mean Opinion Scores (MOSs) based on human perception, aiming to identify the most appropriate quality metrics tailored to GFVC. Moreover, we summarize the GFVC standardization potentials with a unified high-level syntax and develop a low-complexity GFVC system which are both expected to push forward future practical deployments and applications. Finally, we envision the potential of GFVC in industrial applications and deliberate on the current challenges and future opportunities.
Predictive Coding For Animation-Based Video Compression
Jul 09, 2023



We address the problem of efficiently compressing video for conferencing-type applications. We build on recent approaches based on image animation, which can achieve good reconstruction quality at very low bitrate by representing face motions with a compact set of sparse keypoints. However, these methods encode video in a frame-by-frame fashion, i.e. each frame is reconstructed from a reference frame, which limits the reconstruction quality when the bandwidth is larger. Instead, we propose a predictive coding scheme which uses image animation as a predictor, and codes the residual with respect to the actual target frame. The residuals can be in turn coded in a predictive manner, thus removing efficiently temporal dependencies. Our experiments indicate a significant bitrate gain, in excess of 70% compared to the HEVC video standard and over 30% compared to VVC, on a datasetof talking-head videos
A Hybrid Deep Animation Codec for Low-bitrate Video Conferencing
Jul 27, 2022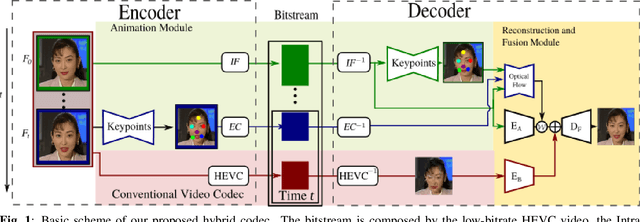
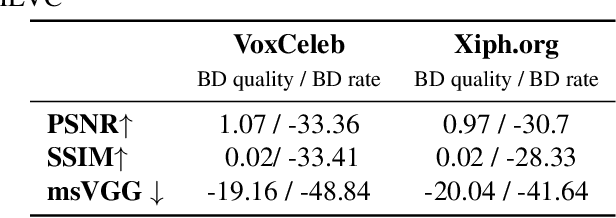

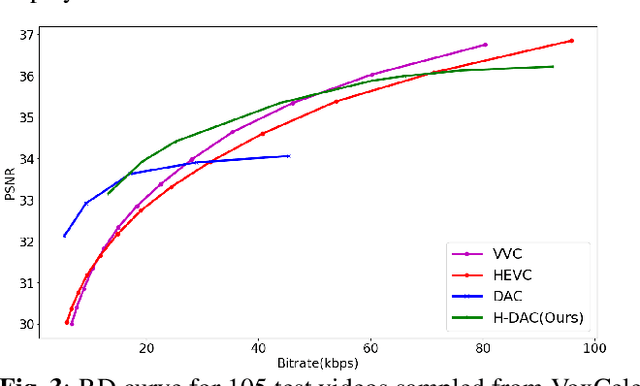
Deep generative models, and particularly facial animation schemes, can be used in video conferencing applications to efficiently compress a video through a sparse set of keypoints, without the need to transmit dense motion vectors. While these schemes bring significant coding gains over conventional video codecs at low bitrates, their performance saturates quickly when the available bandwidth increases. In this paper, we propose a layered, hybrid coding scheme to overcome this limitation. Specifically, we extend a codec based on facial animation by adding an auxiliary stream consisting of a very low bitrate version of the video, obtained through a conventional video codec (e.g., HEVC). The animated and auxiliary videos are combined through a novel fusion module. Our results show consistent average BD-Rate gains in excess of -30% on a large dataset of video conferencing sequences, extending the operational range of bitrates of a facial animation codec alone
Ultra-low bitrate video conferencing using deep image animation
Dec 01, 2020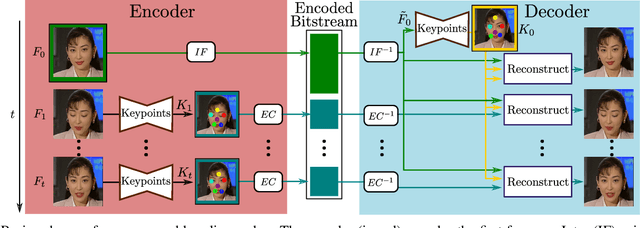
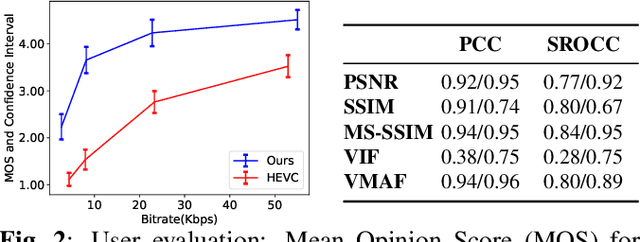
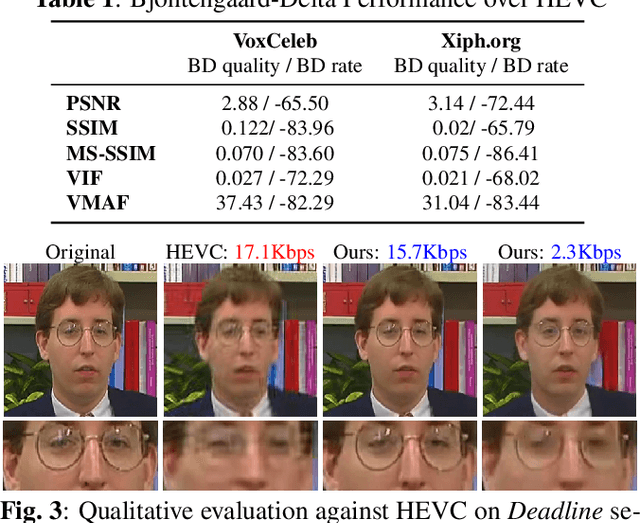
In this work we propose a novel deep learning approach for ultra-low bitrate video compression for video conferencing applications. To address the shortcomings of current video compression paradigms when the available bandwidth is extremely limited, we adopt a model-based approach that employs deep neural networks to encode motion information as keypoint displacement and reconstruct the video signal at the decoder side. The overall system is trained in an end-to-end fashion minimizing a reconstruction error on the encoder output. Objective and subjective quality evaluation experiments demonstrate that the proposed approach provides an average bitrate reduction for the same visual quality of more than 80% compared to HEVC.