 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioTrain: Sub-MB, Sub-50mW On-Device Fine-Tuning for Edge-AI on Biosignals
Apr 14, 2026Biosignals exhibit substantial cross-subject and cross-session variability, inducing severe domain shifts that degrade post-deployment performance for small, edge-oriented AI models. On-device adaptation is therefore essential to both preserve user privacy and ensure system reliability. However, existing sub-100 mW MCU-based wearable platforms can only support shallow or sparse adaptation schemes due to the prohibitive memory footprint and computational cost of full backpropagation (BP). In this paper, we propose BioTrain, a framework enabling full-network fine-tuning of state-of-the-art biosignal models under milliwatt-scale power and sub-megabyte memory constraints. We validate BioTrain using both offline and on-device benchmarks on EEG and EOG datasets, covering Day-1 new-subject calibration and longitudinal adaptation to signal drift. Experimental results show that full-network fine-tuning achieves accuracy improvements of up to 35% over non-adapted baselines and outperforms last-layer updates by approximately 7% during new-subject calibration. On the GAP9 MCU platform, BioTrain enables efficient on-device training throughput of 17 samples/s for EEG and 85 samples/s for EOG models within a power envelope below 50 mW. In addition, BioTrain's efficient memory allocator and network topology optimization enable the use of a large batch size, reducing peak memory usage. For fully on-chip BP on GAP9, BioTrain reduces the memory footprint by 8.1x, from 5.4 MB to 0.67 MB, compared to conventional full-network fine-tuning using batch normalization with batch size 8.
SilentWear: an Ultra-Low Power Wearable System for EMG-based Silent Speech Recognition
Mar 04, 2026Detecting speech from biosignals is gaining increasing attention due to the potential to develop human-computer interfaces that are noise-robust, privacy-preserving, and scalable for both clinical applications and daily use. However, most existing approaches remain limited by insufficient wearability and the lack of edge-processing capabilities, which are essential for minimally obtrusive, responsive, and private assistive technologies. In this work, we present SilentWear, a fully wearable, textile-based neck interface for EMG signal acquisition and processing. Powered by BioGAP-Ultra, the system enables end-to-end data acquisition from 14 differential channels and on-device speech recognition. SilentWear is coupled with SpeechNet, a lightweight 15k-parameter CNN architecture specifically tailored for EMG-based speech decoding, achieving an average cross-validated accuracy of 84.8$\pm$4.6% and 77.5$\pm$6.6% for vocalized and silent speech, respectively, over eight representative human-machine interaction commands collected over multiple days. We evaluate robustness to repositioning induced by multi-day use. In an inter-session setting, the system achieves average accuracies of 71.1$\pm$8.3% and 59.3\pm2.2% for vocalized and silent speech, respectively. To mitigate performance degradation due to repositioning, we propose an incremental fine-tuning strategy, demonstrating more than 10% accuracy recovery with less than 10 minutes of additional user data. Finally, we demonstrate end-to-end real-time on-device speech recognition on a commercial multi-core microcontroller unit (MCU), achieving an energy consumption of 63.9$μ$J per inference with a latency of 2.47 ms. With a total power consumption of 20.5mW for acquisition, inference, and wireless transmission of results, SilentWear enables continuous operation for more than 27 hours.
Wearable and Ultra-Low-Power Fusion of EMG and A-Mode US for Hand-Wrist Kinematic Tracking
Oct 02, 2025



Hand gesture recognition based on biosignals has shown strong potential for developing intuitive human-machine interaction strategies that closely mimic natural human behavior. In particular, sensor fusion approaches have gained attention for combining complementary information and overcoming the limitations of individual sensing modalities, thereby enabling more robust and reliable systems. Among them, the fusion of surface electromyography (EMG) and A-mode ultrasound (US) is very promising. However, prior solutions rely on power-hungry platforms unsuitable for multi-day use and are limited to discrete gesture classification. In this work, we present an ultra-low-power (sub-50 mW) system for concurrent acquisition of 8-channel EMG and 4-channel A-mode US signals, integrating two state-of-the-art platforms into fully wearable, dry-contact armbands. We propose a framework for continuous tracking of 23 degrees of freedom (DoFs), 20 for the hand and 3 for the wrist, using a kinematic glove for ground-truth labeling. Our method employs lightweight encoder-decoder architectures with multi-task learning to simultaneously estimate hand and wrist joint angles. Experimental results under realistic sensor repositioning conditions demonstrate that EMG-US fusion achieves a root mean squared error of $10.6^\circ\pm2.0^\circ$, compared to $12.0^\circ\pm1^\circ$ for EMG and $13.1^\circ\pm2.6^\circ$ for US, and a R$^2$ score of $0.61\pm0.1$, with $0.54\pm0.03$ for EMG and $0.38\pm0.20$ for US.
A Parallel Ultra-Low Power Silent Speech Interface based on a Wearable, Fully-dry EMG Neckband
Sep 26, 2025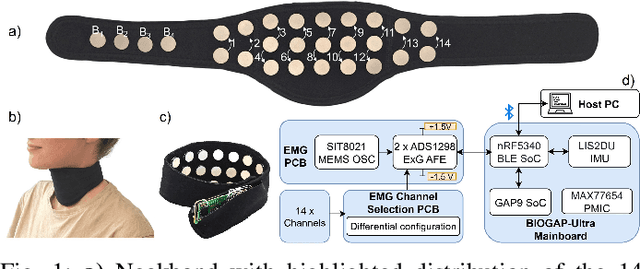
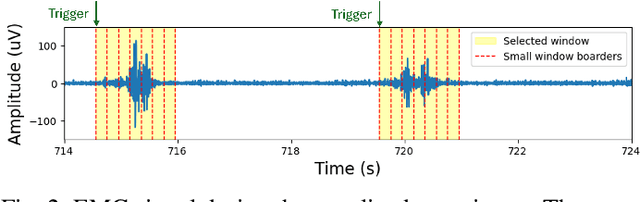
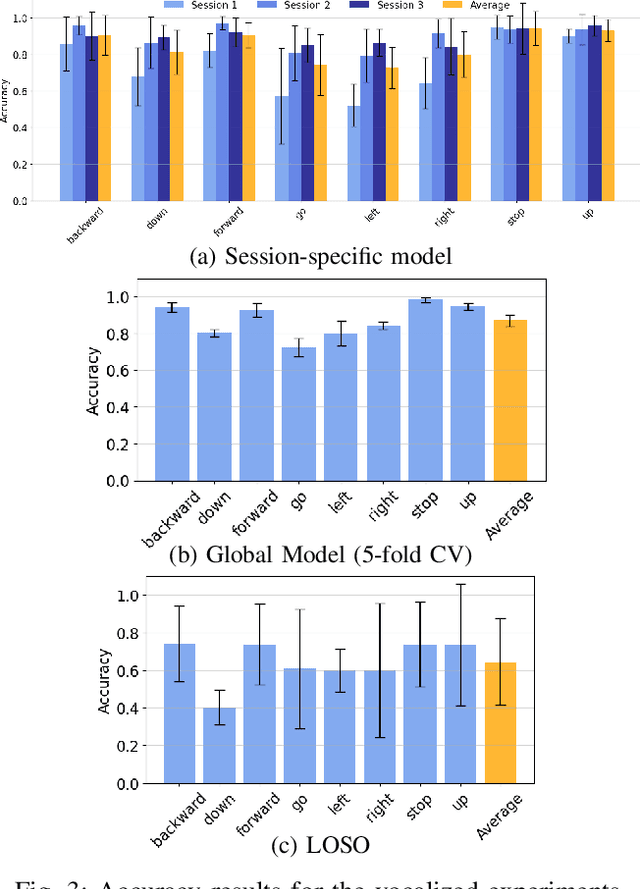
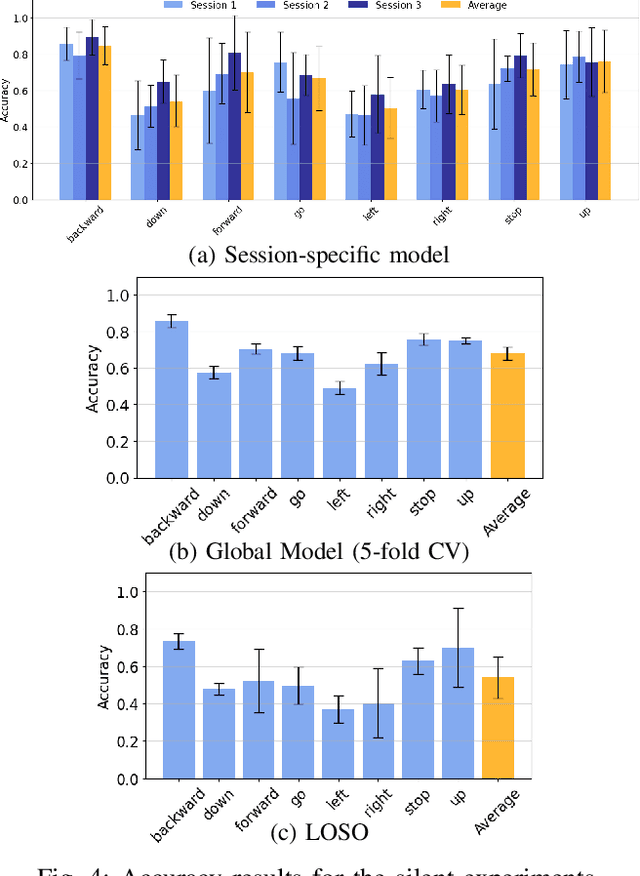
We present a wearable, fully-dry, and ultra-low power EMG system for silent speech recognition, integrated into a textile neckband to enable comfortable, non-intrusive use. The system features 14 fully-differential EMG channels and is based on the BioGAP-Ultra platform for ultra-low power (22 mW) biosignal acquisition and wireless transmission. We evaluate its performance on eight speech commands under both vocalized and silent articulation, achieving average classification accuracies of 87$\pm$3% and 68$\pm$3% respectively, with a 5-fold CV approach. To mimic everyday-life conditions, we introduce session-to-session variability by repositioning the neckband between sessions, achieving leave-one-session-out accuracies of 64$\pm$18% and 54$\pm$7% for the vocalized and silent experiments, respectively. These results highlight the robustness of the proposed approach and the promise of energy-efficient silent-speech decoding.