 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFArMARe: a Furniture-Aware Multi-task methodology for Recommending Apartments based on the user interests
Sep 06, 2023



Nowadays, many people frequently have to search for new accommodation options. Searching for a suitable apartment is a time-consuming process, especially because visiting them is often mandatory to assess the truthfulness of the advertisements found on the Web. While this process could be alleviated by visiting the apartments in the metaverse, the Web-based recommendation platforms are not suitable for the task. To address this shortcoming, in this paper, we define a new problem called text-to-apartment recommendation, which requires ranking the apartments based on their relevance to a textual query expressing the user's interests. To tackle this problem, we introduce FArMARe, a multi-task approach that supports cross-modal contrastive training with a furniture-aware objective. Since public datasets related to indoor scenes do not contain detailed descriptions of the furniture, we collect and annotate a dataset comprising more than 6000 apartments. A thorough experimentation with three different methods and two raw feature extraction procedures reveals the effectiveness of FArMARe in dealing with the problem at hand.
UniUD Submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2023
Jul 16, 2023
In this report, we present the technical details of our submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2023. To participate in the challenge, we ensembled two models trained with two different loss functions on 25% of the training data. Our submission, visible on the public leaderboard, obtains an average score of 56.81% nDCG and 42.63% mAP.
Extensive Evaluation of Transformer-based Architectures for Adverse Drug Events Extraction
Jun 08, 2023



Adverse Event (ADE) extraction is one of the core tasks in digital pharmacovigilance, especially when applied to informal texts. This task has been addressed by the Natural Language Processing community using large pre-trained language models, such as BERT. Despite the great number of Transformer-based architectures used in the literature, it is unclear which of them has better performances and why. Therefore, in this paper we perform an extensive evaluation and analysis of 19 Transformer-based models for ADE extraction on informal texts. We compare the performance of all the considered models on two datasets with increasing levels of informality (forums posts and tweets). We also combine the purely Transformer-based models with two commonly-used additional processing layers (CRF and LSTM), and analyze their effect on the models performance. Furthermore, we use a well-established feature importance technique (SHAP) to correlate the performance of the models with a set of features that describe them: model category (AutoEncoding, AutoRegressive, Text-to-Text), pretraining domain, training from scratch, and model size in number of parameters. At the end of our analyses, we identify a list of take-home messages that can be derived from the experimental data.
Learning Sparsity of Representations with Discrete Latent Variables
Apr 03, 2023Deep latent generative models have attracted increasing attention due to the capacity of combining the strengths of deep learning and probabilistic models in an elegant way. The data representations learned with the models are often continuous and dense. However in many applications, sparse representations are expected, such as learning sparse high dimensional embedding of data in an unsupervised setting, and learning multi-labels from thousands of candidate tags in a supervised setting. In some scenarios, there could be further restriction on degree of sparsity: the number of non-zero features of a representation cannot be larger than a pre-defined threshold $L_0$. In this paper we propose a sparse deep latent generative model SDLGM to explicitly model degree of sparsity and thus enable to learn the sparse structure of the data with the quantified sparsity constraint. The resulting sparsity of a representation is not fixed, but fits to the observation itself under the pre-defined restriction. In particular, we introduce to each observation $i$ an auxiliary random variable $L_i$, which models the sparsity of its representation. The sparse representations are then generated with a two-step sampling process via two Gumbel-Softmax distributions. For inference and learning, we develop an amortized variational method based on MC gradient estimator. The resulting sparse representations are differentiable with backpropagation. The experimental evaluation on multiple datasets for unsupervised and supervised learning problems shows the benefits of the proposed method.
Learning to Explain Graph Neural Networks
Sep 28, 2022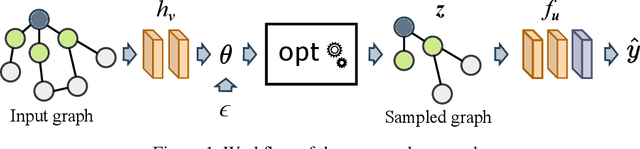
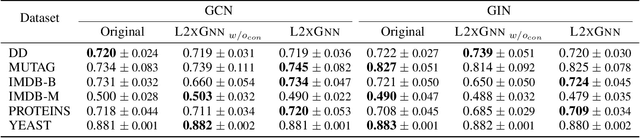
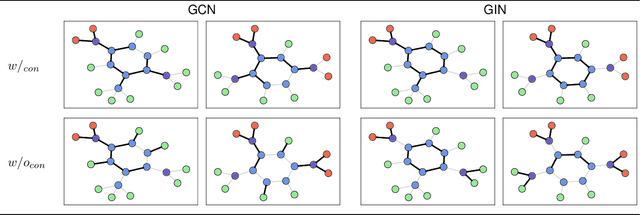
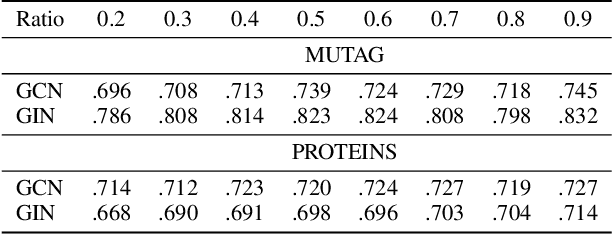
Graph Neural Networks (GNNs) are a popular class of machine learning models. Inspired by the learning to explain (L2X) paradigm, we propose L2XGNN, a framework for explainable GNNs which provides faithful explanations by design. L2XGNN learns a mechanism for selecting explanatory subgraphs (motifs) which are exclusively used in the GNNs message-passing operations. L2XGNN is able to select, for each input graph, a subgraph with specific properties such as being sparse and connected. Imposing such constraints on the motifs often leads to more interpretable and effective explanations. Experiments on several datasets suggest that L2XGNN achieves the same classification accuracy as baseline methods using the entire input graph while ensuring that only the provided explanations are used to make predictions. Moreover, we show that L2XGNN is able to identify motifs responsible for the graph's properties it is intended to predict.
AILAB-Udine@SMM4H 22: Limits of Transformers and BERT Ensembles
Sep 07, 2022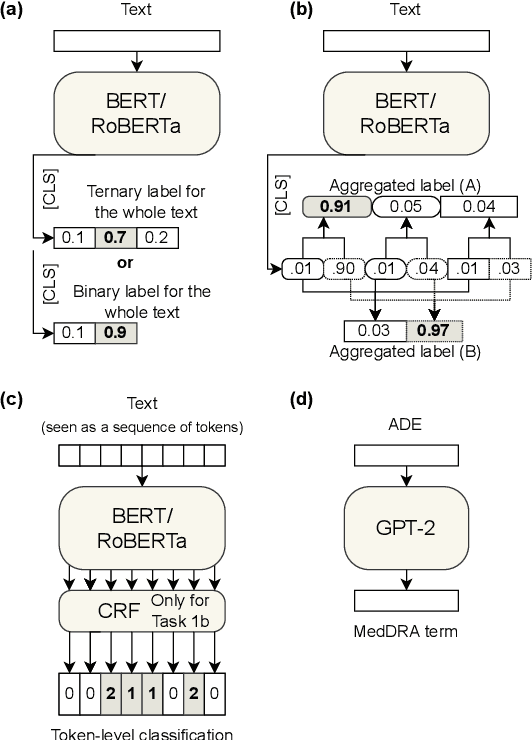

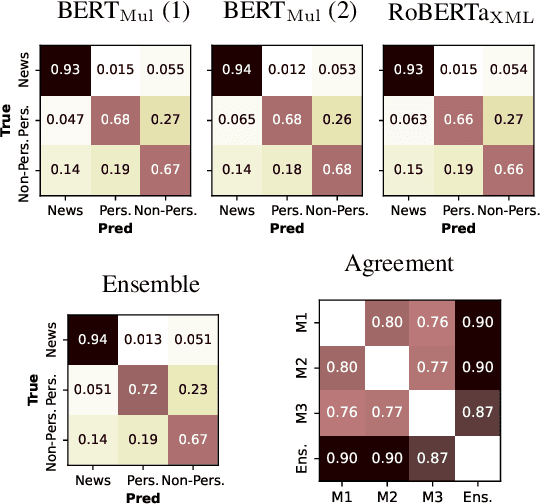

This paper describes the models developed by the AILAB-Udine team for the SMM4H 22 Shared Task. We explored the limits of Transformer based models on text classification, entity extraction and entity normalization, tackling Tasks 1, 2, 5, 6 and 10. The main take-aways we got from participating in different tasks are: the overwhelming positive effects of combining different architectures when using ensemble learning, and the great potential of generative models for term normalization.
Increasing Adverse Drug Events extraction robustness on social media: case study on negation and speculation
Sep 06, 2022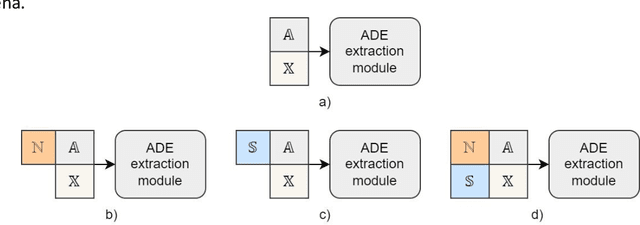
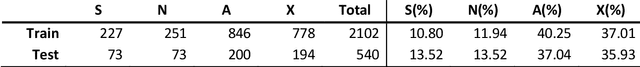
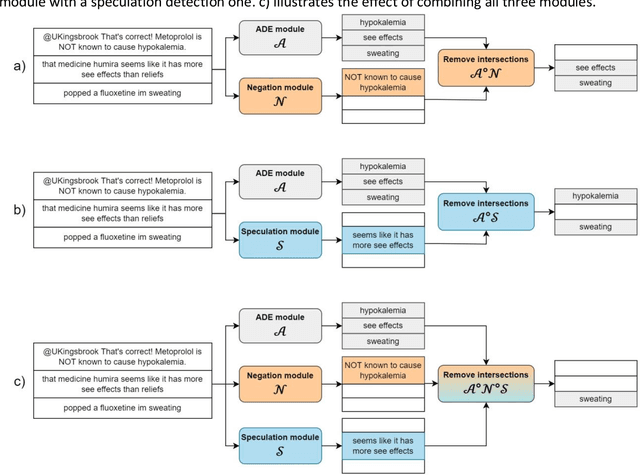
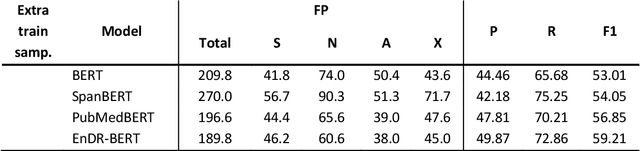
In the last decade, an increasing number of users have started reporting Adverse Drug Events (ADE) on social media platforms, blogs, and health forums. Given the large volume of reports, pharmacovigilance has focused on ways to use Natural Language Processing (NLP) techniques to rapidly examine these large collections of text, detecting mentions of drug-related adverse reactions to trigger medical investigations. However, despite the growing interest in the task and the advances in NLP, the robustness of these models in face of linguistic phenomena such as negations and speculations is an open research question. Negations and speculations are pervasive phenomena in natural language, and can severely hamper the ability of an automated system to discriminate between factual and nonfactual statements in text. In this paper we take into consideration four state-of-the-art systems for ADE detection on social media texts. We introduce SNAX, a benchmark to test their performance against samples containing negated and speculated ADEs, showing their fragility against these phenomena. We then introduce two possible strategies to increase the robustness of these models, showing that both of them bring significant increases in performance, lowering the number of spurious entities predicted by the models by 60% for negation and 80% for speculations.
A Feature-space Multimodal Data Augmentation Technique for Text-video Retrieval
Aug 03, 2022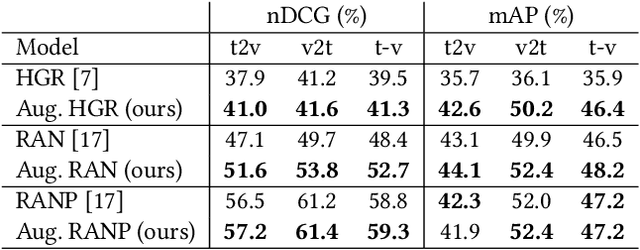

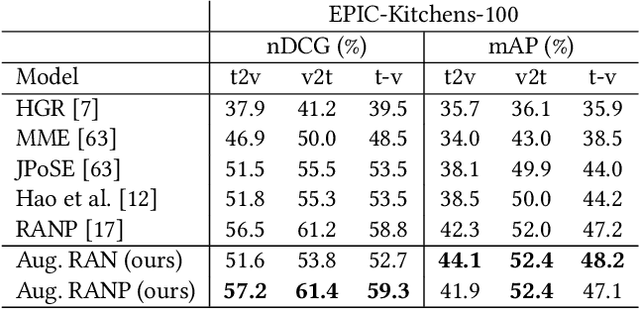
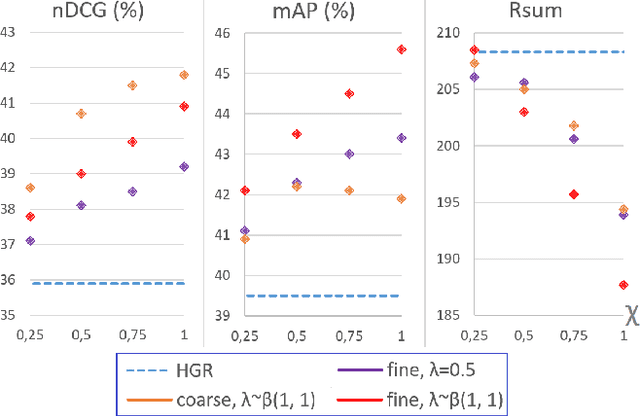
Every hour, huge amounts of visual contents are posted on social media and user-generated content platforms. To find relevant videos by means of a natural language query, text-video retrieval methods have received increased attention over the past few years. Data augmentation techniques were introduced to increase the performance on unseen test examples by creating new training samples with the application of semantics-preserving techniques, such as color space or geometric transformations on images. Yet, these techniques are usually applied on raw data, leading to more resource-demanding solutions and also requiring the shareability of the raw data, which may not always be true, e.g. copyright issues with clips from movies or TV series. To address this shortcoming, we propose a multimodal data augmentation technique which works in the feature space and creates new videos and captions by mixing semantically similar samples. We experiment our solution on a large scale public dataset, EPIC-Kitchens-100, and achieve considerable improvements over a baseline method, improved state-of-the-art performance, while at the same time performing multiple ablation studies. We release code and pretrained models on Github at https://github.com/aranciokov/FSMMDA_VideoRetrieval.
Human-Centric Research for NLP: Towards a Definition and Guiding Questions
Jul 10, 2022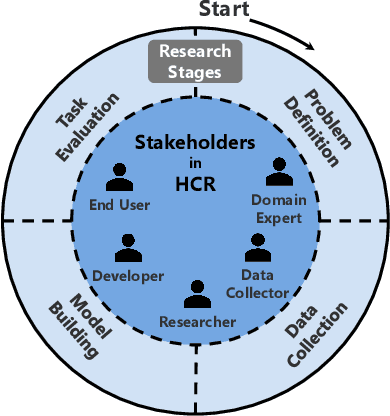

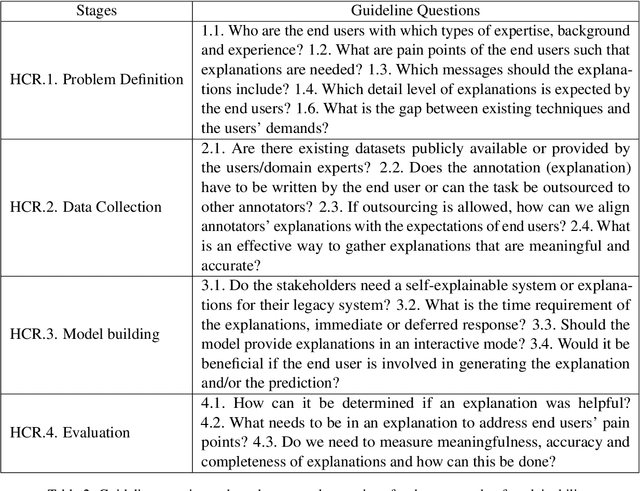
With Human-Centric Research (HCR) we can steer research activities so that the research outcome is beneficial for human stakeholders, such as end users. But what exactly makes research human-centric? We address this question by providing a working definition and define how a research pipeline can be split into different stages in which human-centric components can be added. Additionally, we discuss existing NLP with HCR components and define a series of guiding questions, which can serve as starting points for researchers interested in exploring human-centric research approaches. We hope that this work would inspire researchers to refine the proposed definition and to pose other questions that might be meaningful for achieving HCR.
UniUD-FBK-UB-UniBZ Submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022
Jun 22, 2022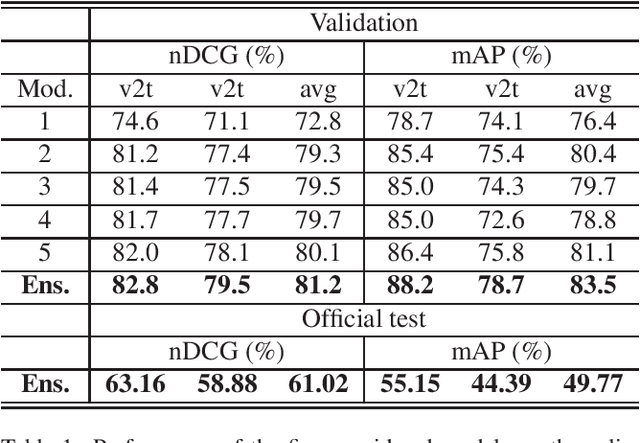
This report presents the technical details of our submission to the EPIC-Kitchens-100 Multi-Instance Retrieval Challenge 2022. To participate in the challenge, we designed an ensemble consisting of different models trained with two recently developed relevance-augmented versions of the widely used triplet loss. Our submission, visible on the public leaderboard, obtains an average score of 61.02% nDCG and 49.77% mAP.