 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepStochLog: Neural Stochastic Logic Programming
Jun 23, 2021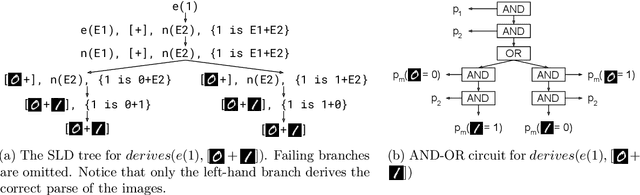

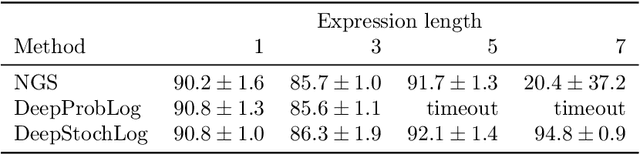
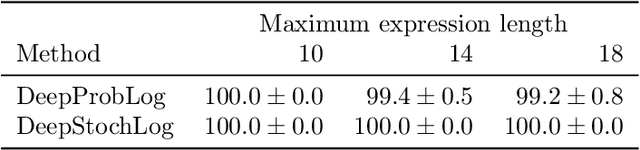
Recent advances in neural symbolic learning, such as DeepProbLog, extend probabilistic logic programs with neural predicates. Like graphical models, these probabilistic logic programs define a probability distribution over possible worlds, for which inference is computationally hard. We propose DeepStochLog, an alternative neural symbolic framework based on stochastic definite clause grammars, a type of stochastic logic program, which defines a probability distribution over possible derivations. More specifically, we introduce neural grammar rules into stochastic definite clause grammars to create a framework that can be trained end-to-end. We show that inference and learning in neural stochastic logic programming scale much better than for neural probabilistic logic programs. Furthermore, the experimental evaluation shows that DeepStochLog achieves state-of-the-art results on challenging neural symbolic learning tasks.
Learning Representations for Sub-Symbolic Reasoning
Jun 01, 2021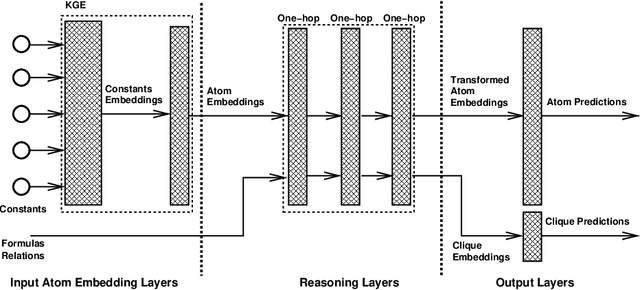

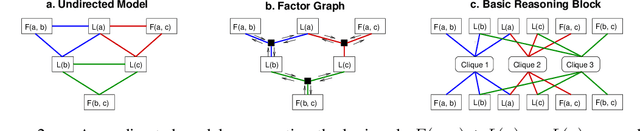
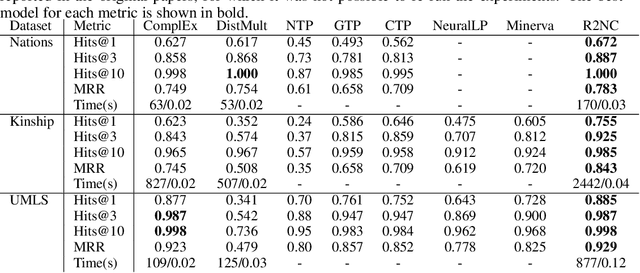
Neuro-symbolic methods integrate neural architectures, knowledge representation and reasoning. However, they have been struggling at both dealing with the intrinsic uncertainty of the observations and scaling to real world applications. This paper presents Relational Reasoning Networks (R2N), a novel end-to-end model that performs relational reasoning in the latent space of a deep learner architecture, where the representations of constants, ground atoms and their manipulations are learned in an integrated fashion. Unlike flat architectures like Knowledge Graph Embedders, which can only represent relations between entities, R2Ns define an additional computational structure, accounting for higher-level relations among the ground atoms. The considered relations can be explicitly known, like the ones defined by logic formulas, or defined as unconstrained correlations among groups of ground atoms. R2Ns can be applied to purely symbolic tasks or as a neuro-symbolic platform to integrate learning and reasoning in heterogeneous problems with both symbolic and feature-based represented entities. The proposed model bridges the gap between previous neuro-symbolic methods that have been either limited in terms of scalability or expressivity. The proposed methodology is shown to achieve state-of-the-art results in different experimental settings.
Online Learning of Non-Markovian Reward Models
Sep 30, 2020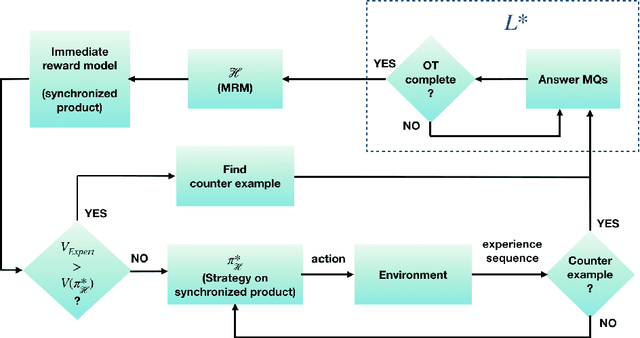
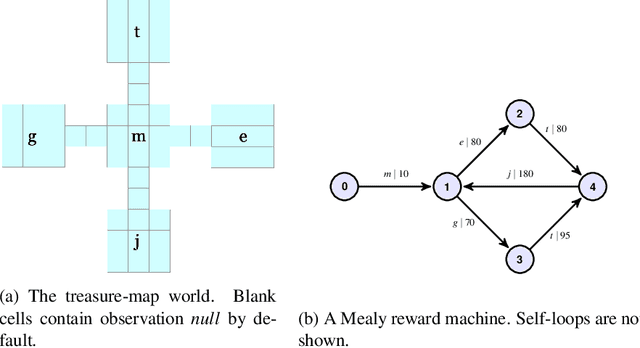
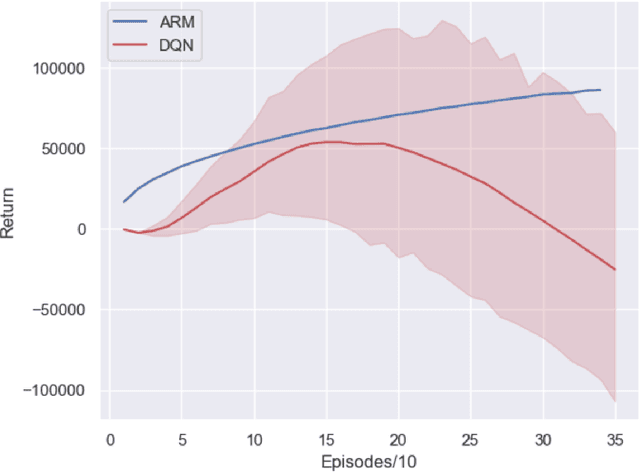
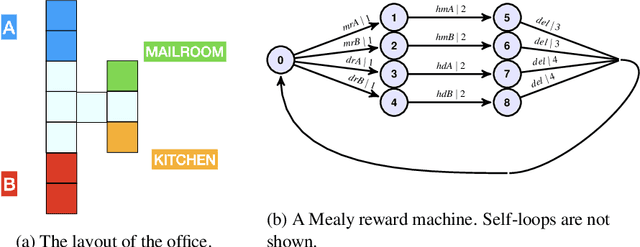
There are situations in which an agent should receive rewards only after having accomplished a series of previous tasks, that is, rewards are non-Markovian. One natural and quite general way to represent history-dependent rewards is via a Mealy machine, a finite state automaton that produces output sequences from input sequences. In our formal setting, we consider a Markov decision process (MDP) that models the dynamics of the environment in which the agent evolves and a Mealy machine synchronized with this MDP to formalize the non-Markovian reward function. While the MDP is known by the agent, the reward function is unknown to the agent and must be learned. Our approach to overcome this challenge is to use Angluin's $L^*$ active learning algorithm to learn a Mealy machine representing the underlying non-Markovian reward machine (MRM). Formal methods are used to determine the optimal strategy for answering so-called membership queries posed by $L^*$. Moreover, we prove that the expected reward achieved will eventually be at least as much as a given, reasonable value provided by a domain expert. We evaluate our framework on three problems. The results show that using $L^*$ to learn an MRM in a non-Markovian reward decision process is effective.
Deep Lagrangian Constraint-based Propagation in Graph Neural Networks
May 27, 2020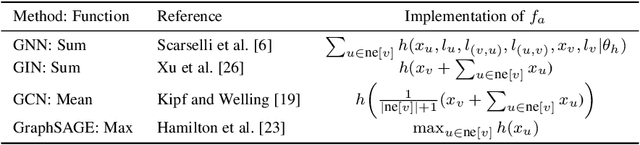
Several real-world applications are characterized by data that exhibit a complex structure that can be represented using graphs. The popularity of deep learning techniques renewed the interest in neural architectures able to process these patterns, inspired by the Graph Neural Network (GNN) model. GNNs encode the state of the nodes of the graph by means of an iterative diffusion procedure that, during the learning stage, must be computed at every epoch, until the fixed point of a learnable state transition function is reached, propagating the information among the neighbouring nodes. We propose a novel approach to learning in GNNs, based on constrained optimization in the Lagrangian framework. Learning both the transition function and the node states is the outcome of a joint process, in which the state convergence procedure is implicitly expressed by a constraint satisfaction mechanism, avoiding iterative epoch-wise procedures and the network unfolding. Our computational structure searches for saddle points of the Lagrangian in the adjoint space composed of weights, nodes state variables and Lagrange multipliers. This process is further enhanced by multiple layers of constraints that accelerate the diffusion process. An experimental analysis shows that the proposed approach compares favourably with popular models on several benchmarks.
From Statistical Relational to Neuro-Symbolic Artificial Intelligence
Mar 24, 2020
Neuro-symbolic and statistical relational artificial intelligence both integrate frameworks for learning with logical reasoning. This survey identifies several parallels across seven different dimensions between these two fields. These cannot only be used to characterize and position neuro-symbolic artificial intelligence approaches but also to identify a number of directions for further research.
A Lagrangian Approach to Information Propagation in Graph Neural Networks
Feb 19, 2020
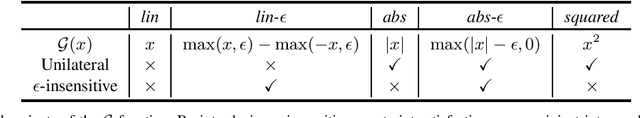
In many real world applications, data are characterized by a complex structure, that can be naturally encoded as a graph. In the last years, the popularity of deep learning techniques has renewed the interest in neural models able to process complex patterns. In particular, inspired by the Graph Neural Network (GNN) model, different architectures have been proposed to extend the original GNN scheme. GNNs exploit a set of state variables, each assigned to a graph node, and a diffusion mechanism of the states among neighbor nodes, to implement an iterative procedure to compute the fixed point of the (learnable) state transition function. In this paper, we propose a novel approach to the state computation and the learning algorithm for GNNs, based on a constraint optimisation task solved in the Lagrangian framework. The state convergence procedure is implicitly expressed by the constraint satisfaction mechanism and does not require a separate iterative phase for each epoch of the learning procedure. In fact, the computational structure is based on the search for saddle points of the Lagrangian in the adjoint space composed of weights, neural outputs (node states), and Lagrange multipliers. The proposed approach is compared experimentally with other popular models for processing graphs.
Local Propagation in Constraint-based Neural Network
Feb 18, 2020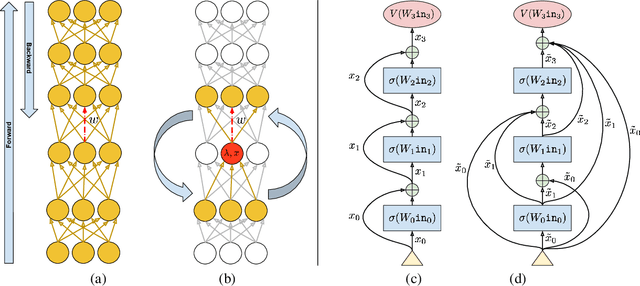
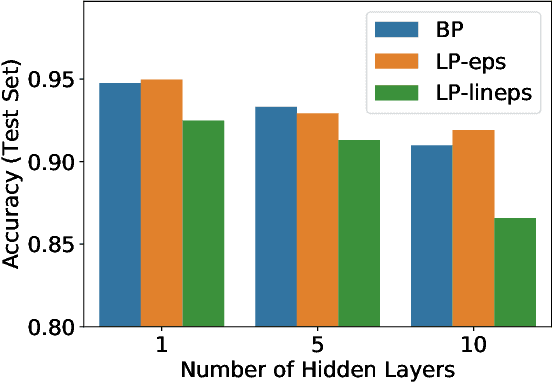
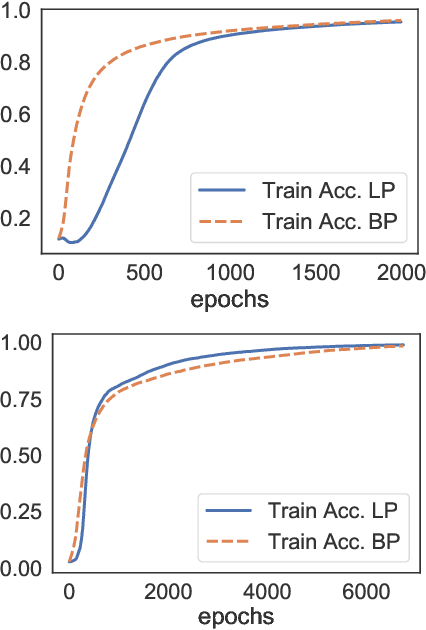
In this paper we study a constraint-based representation of neural network architectures. We cast the learning problem in the Lagrangian framework and we investigate a simple optimization procedure that is well suited to fulfil the so-called architectural constraints, learning from the available supervisions. The computational structure of the proposed Local Propagation (LP) algorithm is based on the search for saddle points in the adjoint space composed of weights, neural outputs, and Lagrange multipliers. All the updates of the model variables are locally performed, so that LP is fully parallelizable over the neural units, circumventing the classic problem of gradient vanishing in deep networks. The implementation of popular neural models is described in the context of LP, together with those conditions that trace a natural connection with Backpropagation. We also investigate the setting in which we tolerate bounded violations of the architectural constraints, and we provide experimental evidence that LP is a feasible approach to train shallow and deep networks, opening the road to further investigations on more complex architectures, easily describable by constraints.
Relational Neural Machines
Feb 06, 2020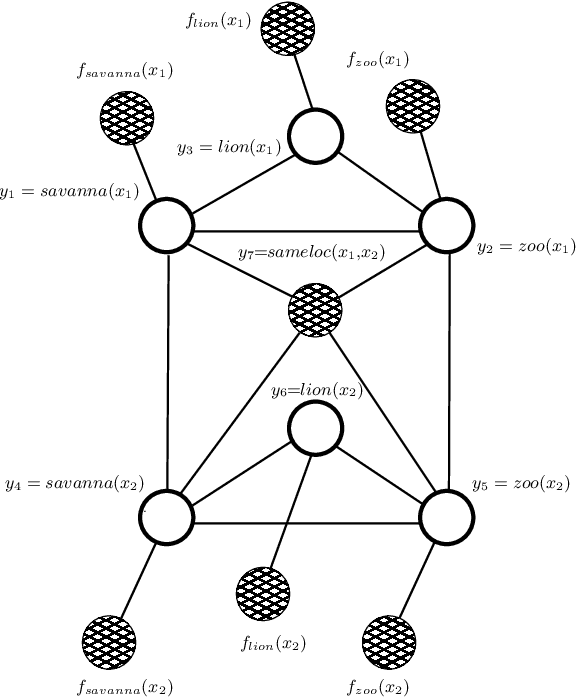


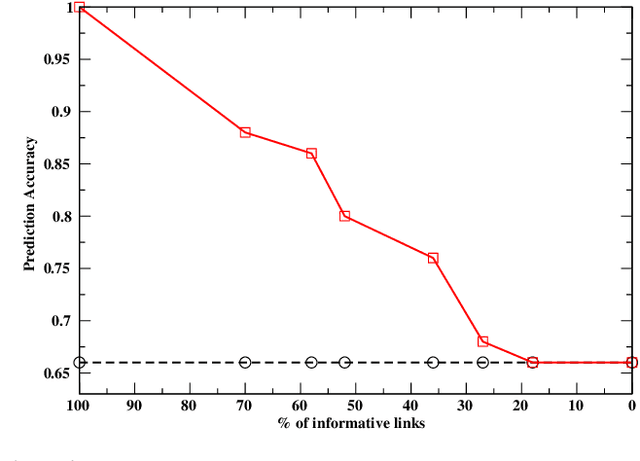
Deep learning has been shown to achieve impressive results in several tasks where a large amount of training data is available. However, deep learning solely focuses on the accuracy of the predictions, neglecting the reasoning process leading to a decision, which is a major issue in life-critical applications. Probabilistic logic reasoning allows to exploit both statistical regularities and specific domain expertise to perform reasoning under uncertainty, but its scalability and brittle integration with the layers processing the sensory data have greatly limited its applications. For these reasons, combining deep architectures and probabilistic logic reasoning is a fundamental goal towards the development of intelligent agents operating in complex environments. This paper presents Relational Neural Machines, a novel framework allowing to jointly train the parameters of the learners and of a First--Order Logic based reasoner. A Relational Neural Machine is able to recover both classical learning from supervised data in case of pure sub-symbolic learning, and Markov Logic Networks in case of pure symbolic reasoning, while allowing to jointly train and perform inference in hybrid learning tasks. Proper algorithmic solutions are devised to make learning and inference tractable in large-scale problems. The experiments show promising results in different relational tasks.
Learning in Text Streams: Discovery and Disambiguation of Entity and Relation Instances
Sep 06, 2019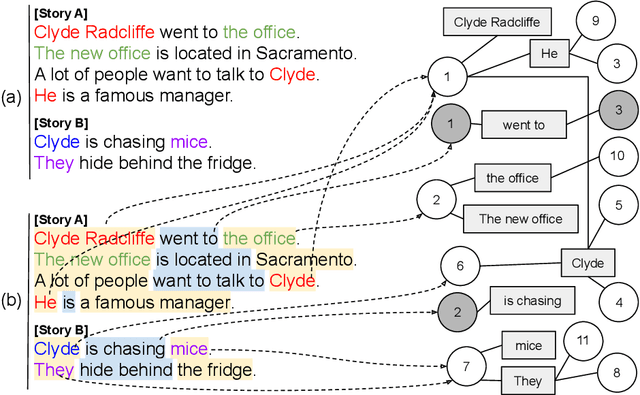
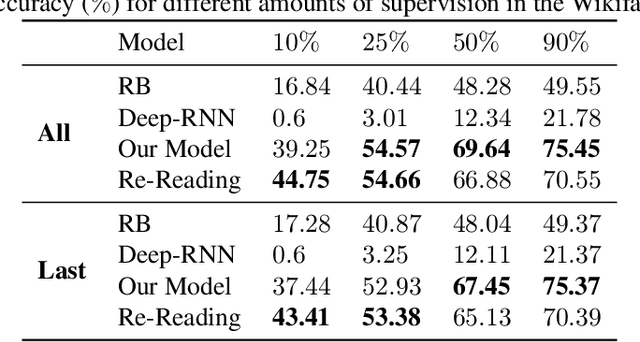
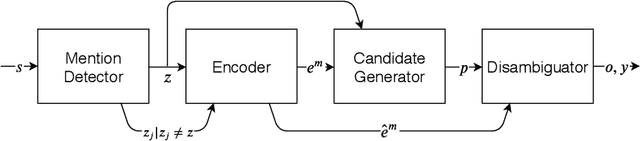

We consider a scenario where an artificial agent is reading a stream of text composed of a set of narrations, and it is informed about the identity of some of the individuals that are mentioned in the text portion that is currently being read. The agent is expected to learn to follow the narrations, thus disambiguating mentions and discovering new individuals. We focus on the case in which individuals are entities and relations, and we propose an end-to-end trainable memory network that learns to discover and disambiguate them in an online manner, performing one-shot learning, and dealing with a small number of sparse supervisions. Our system builds a not-given-in-advance knowledge base, and it improves its skills while reading unsupervised text. The model deals with abrupt changes in the narration, taking into account their effects when resolving co-references. We showcase the strong disambiguation and discovery skills of our model on a corpus of Wikipedia documents and on a newly introduced dataset, that we make publicly available.
Learning and T-Norms Theory
Jul 26, 2019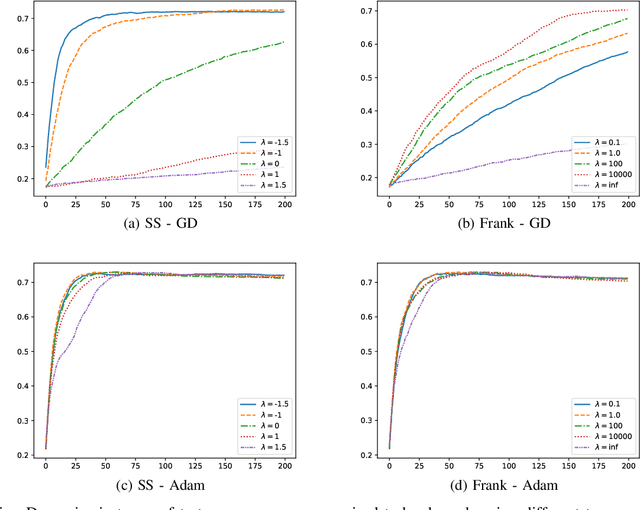


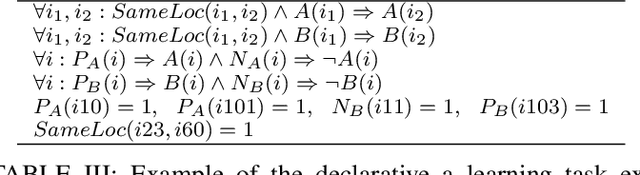
Deep learning has been shown to achieve impressive results in several domains like computer vision and natural language processing. Deep architectures are typically trained following a supervised scheme and, therefore, they rely on the availability of a large amount of labeled training data to effectively learn their parameters. Neuro-symbolic approaches have recently gained popularity to inject prior knowledge into a deep learner without requiring it to induce this knowledge from data. These approaches can potentially learn competitive solutions with a significant reduction of the amount of supervised data. A large class of neuro-symbolic approaches is based on First-Order Logic to represent prior knowledge, that is relaxed to a differentiable form using fuzzy logic. This paper shows that the loss function expressing these neuro-symbolic learning tasks can be unambiguously determined given the selection of a t-norm generator. When restricted to simple supervised learning, the presented theoretical apparatus provides a clean justification to the popular cross-entropy loss, that has been shown to provide faster convergence and to reduce the vanishing gradient problem in very deep structures. One advantage of the proposed learning formulation is that it can be extended to all the knowledge that can be represented by a neuro-symbolic method, and it allows the development of a novel class of loss functions, that the experimental results show to lead to faster convergence rates than other approaches previously proposed in the literature.