 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a fully declarative neuro-symbolic language
May 15, 2024



Neuro-symbolic systems (NeSy), which claim to combine the best of both learning and reasoning capabilities of artificial intelligence, are missing a core property of reasoning systems: Declarativeness. The lack of declarativeness is caused by the functional nature of neural predicates inherited from neural networks. We propose and implement a general framework for fully declarative neural predicates, which hence extends to fully declarative NeSy frameworks. We first show that the declarative extension preserves the learning and reasoning capabilities while being able to answer arbitrary queries while only being trained on a single query type.
Climbing the Ladder of Interpretability with Counterfactual Concept Bottleneck Models
Feb 02, 2024



Current deep learning models are not designed to simultaneously address three fundamental questions: predict class labels to solve a given classification task (the "What?"), explain task predictions (the "Why?"), and imagine alternative scenarios that could result in different predictions (the "What if?"). The inability to answer these questions represents a crucial gap in deploying reliable AI agents, calibrating human trust, and deepening human-machine interaction. To bridge this gap, we introduce CounterFactual Concept Bottleneck Models (CF-CBMs), a class of models designed to efficiently address the above queries all at once without the need to run post-hoc searches. Our results show that CF-CBMs produce: accurate predictions (the "What?"), simple explanations for task predictions (the "Why?"), and interpretable counterfactuals (the "What if?"). CF-CBMs can also sample or estimate the most probable counterfactual to: (i) explain the effect of concept interventions on tasks, (ii) show users how to get a desired class label, and (iii) propose concept interventions via "task-driven" interventions.
Relational Concept Based Models
Aug 23, 2023



The design of interpretable deep learning models working in relational domains poses an open challenge: interpretable deep learning methods, such as Concept-Based Models (CBMs), are not designed to solve relational problems, while relational models are not as interpretable as CBMs. To address this problem, we propose Relational Concept-Based Models, a family of relational deep learning methods providing interpretable task predictions. Our experiments, ranging from image classification to link prediction in knowledge graphs, show that relational CBMs (i) match generalization performance of existing relational black-boxes (as opposed to non-relational CBMs), (ii) support the generation of quantified concept-based explanations, (iii) effectively respond to test-time interventions, and (iv) withstand demanding settings including out-of-distribution scenarios, limited training data regimes, and scarce concept supervisions.
Interpretable Neural-Symbolic Concept Reasoning
Apr 27, 2023



Deep learning methods are highly accurate, yet their opaque decision process prevents them from earning full human trust. Concept-based models aim to address this issue by learning tasks based on a set of human-understandable concepts. However, state-of-the-art concept-based models rely on high-dimensional concept embedding representations which lack a clear semantic meaning, thus questioning the interpretability of their decision process. To overcome this limitation, we propose the Deep Concept Reasoner (DCR), the first interpretable concept-based model that builds upon concept embeddings. In DCR, neural networks do not make task predictions directly, but they build syntactic rule structures using concept embeddings. DCR then executes these rules on meaningful concept truth degrees to provide a final interpretable and semantically-consistent prediction in a differentiable manner. Our experiments show that DCR: (i) improves up to +25% w.r.t. state-of-the-art interpretable concept-based models on challenging benchmarks (ii) discovers meaningful logic rules matching known ground truths even in the absence of concept supervision during training, and (iii), facilitates the generation of counterfactual examples providing the learnt rules as guidance.
Enhancing Embedding Representations of Biomedical Data using Logic Knowledge
Mar 23, 2023



Knowledge Graph Embeddings (KGE) have become a quite popular class of models specifically devised to deal with ontologies and graph structure data, as they can implicitly encode statistical dependencies between entities and relations in a latent space. KGE techniques are particularly effective for the biomedical domain, where it is quite common to deal with large knowledge graphs underlying complex interactions between biological and chemical objects. Recently in the literature, the PharmKG dataset has been proposed as one of the most challenging knowledge graph biomedical benchmark, with hundreds of thousands of relational facts between genes, diseases and chemicals. Despite KGEs can scale to very large relational domains, they generally fail at representing more complex relational dependencies between facts, like logic rules, which may be fundamental in complex experimental settings. In this paper, we exploit logic rules to enhance the embedding representations of KGEs on the PharmKG dataset. To this end, we adopt Relational Reasoning Network (R2N), a recently proposed neural-symbolic approach showing promising results on knowledge graph completion tasks. An R2N uses the available logic rules to build a neural architecture that reasons over KGE latent representations. In the experiments, we show that our approach is able to significantly improve the current state-of-the-art on the PharmKG dataset. Finally, we provide an ablation study to experimentally compare the effect of alternative sets of rules according to different selection criteria and varying the number of considered rules.
Neural Probabilistic Logic Programming in Discrete-Continuous Domains
Mar 14, 2023Neural-symbolic AI (NeSy) allows neural networks to exploit symbolic background knowledge in the form of logic. It has been shown to aid learning in the limited data regime and to facilitate inference on out-of-distribution data. Probabilistic NeSy focuses on integrating neural networks with both logic and probability theory, which additionally allows learning under uncertainty. A major limitation of current probabilistic NeSy systems, such as DeepProbLog, is their restriction to finite probability distributions, i.e., discrete random variables. In contrast, deep probabilistic programming (DPP) excels in modelling and optimising continuous probability distributions. Hence, we introduce DeepSeaProbLog, a neural probabilistic logic programming language that incorporates DPP techniques into NeSy. Doing so results in the support of inference and learning of both discrete and continuous probability distributions under logical constraints. Our main contributions are 1) the semantics of DeepSeaProbLog and its corresponding inference algorithm, 2) a proven asymptotically unbiased learning algorithm, and 3) a series of experiments that illustrate the versatility of our approach.
Safe Reinforcement Learning via Probabilistic Logic Shields
Mar 06, 2023Safe Reinforcement learning (Safe RL) aims at learning optimal policies while staying safe. A popular solution to Safe RL is shielding, which uses a logical safety specification to prevent an RL agent from taking unsafe actions. However, traditional shielding techniques are difficult to integrate with continuous, end-to-end deep RL methods. To this end, we introduce Probabilistic Logic Policy Gradient (PLPG). PLPG is a model-based Safe RL technique that uses probabilistic logic programming to model logical safety constraints as differentiable functions. Therefore, PLPG can be seamlessly applied to any policy gradient algorithm while still providing the same convergence guarantees. In our experiments, we show that PLPG learns safer and more rewarding policies compared to other state-of-the-art shielding techniques.
Concept Embedding Models
Sep 19, 2022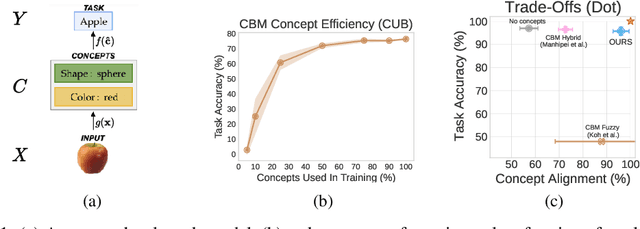

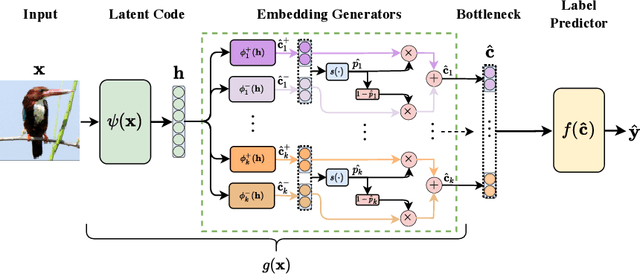

Deploying AI-powered systems requires trustworthy models supporting effective human interactions, going beyond raw prediction accuracy. Concept bottleneck models promote trustworthiness by conditioning classification tasks on an intermediate level of human-like concepts. This enables human interventions which can correct mispredicted concepts to improve the model's performance. However, existing concept bottleneck models are unable to find optimal compromises between high task accuracy, robust concept-based explanations, and effective interventions on concepts -- particularly in real-world conditions where complete and accurate concept supervisions are scarce. To address this, we propose Concept Embedding Models, a novel family of concept bottleneck models which goes beyond the current accuracy-vs-interpretability trade-off by learning interpretable high-dimensional concept representations. Our experiments demonstrate that Concept Embedding Models (1) attain better or competitive task accuracy w.r.t. standard neural models without concepts, (2) provide concept representations capturing meaningful semantics including and beyond their ground truth labels, (3) support test-time concept interventions whose effect in test accuracy surpasses that in standard concept bottleneck models, and (4) scale to real-world conditions where complete concept supervisions are scarce.
VAEL: Bridging Variational Autoencoders and Probabilistic Logic Programming
Feb 07, 2022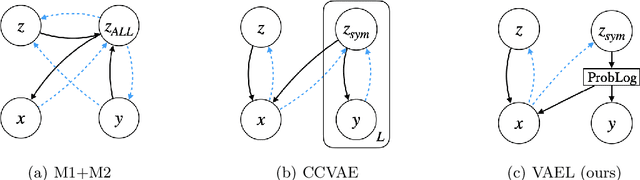
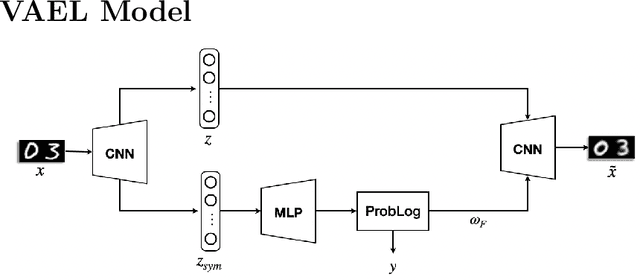

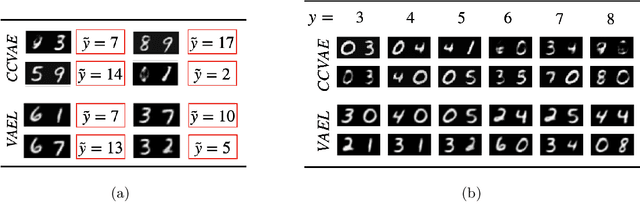
We present VAEL, a neuro-symbolic generative model integrating variational autoencoders (VAE) with the reasoning capabilities of probabilistic logic (L) programming. Besides standard latent subsymbolic variables, our model exploits a probabilistic logic program to define a further structured representation, which is used for logical reasoning. The entire process is end-to-end differentiable. Once trained, VAEL can solve new unseen generation tasks by (i) leveraging the previously acquired knowledge encoded in the neural component and (ii) exploiting new logical programs on the structured latent space. Our experiments provide support on the benefits of this neuro-symbolic integration both in terms of task generalization and data efficiency. To the best of our knowledge, this work is the first to propose a general-purpose end-to-end framework integrating probabilistic logic programming into a deep generative model.
From Statistical Relational to Neural Symbolic Artificial Intelligence: a Survey
Aug 25, 2021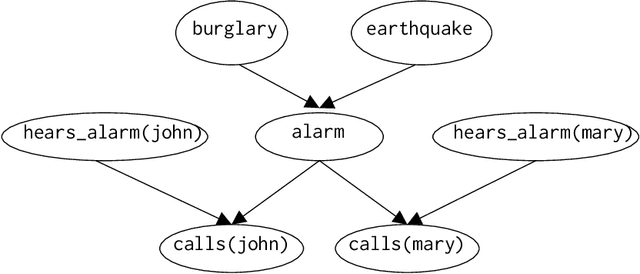
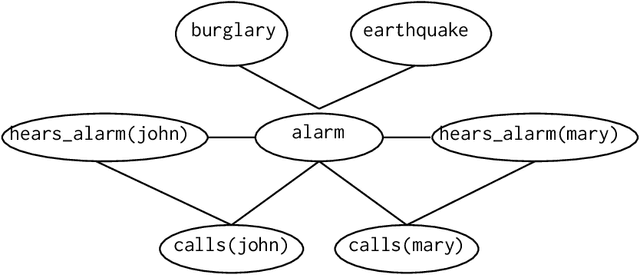
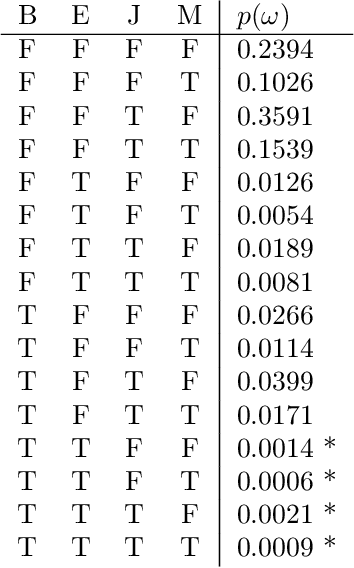
Neural-symbolic and statistical relational artificial intelligence both integrate frameworks for learning with logical reasoning. This survey identifies several parallels across seven different dimensions between these two fields. These cannot only be used to characterize and position neural-symbolic artificial intelligence approaches but also to identify a number of directions for further research.