 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Large-Scale Discourse Structures in Pre-Trained and Fine-Tuned Language Models
Apr 08, 2022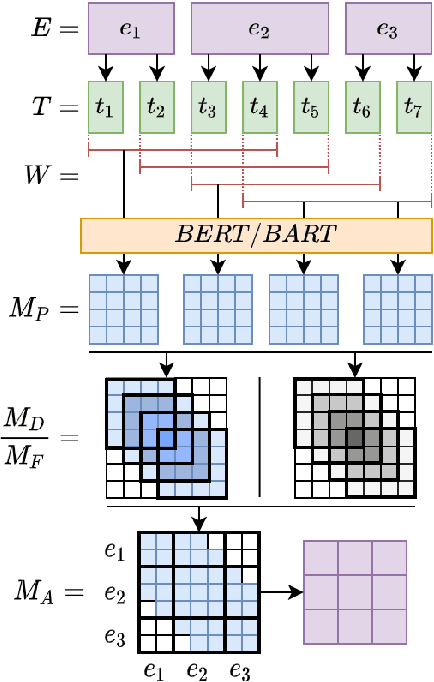
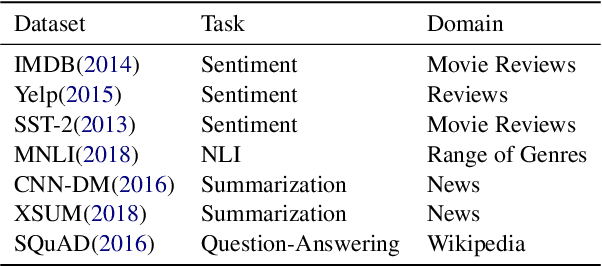
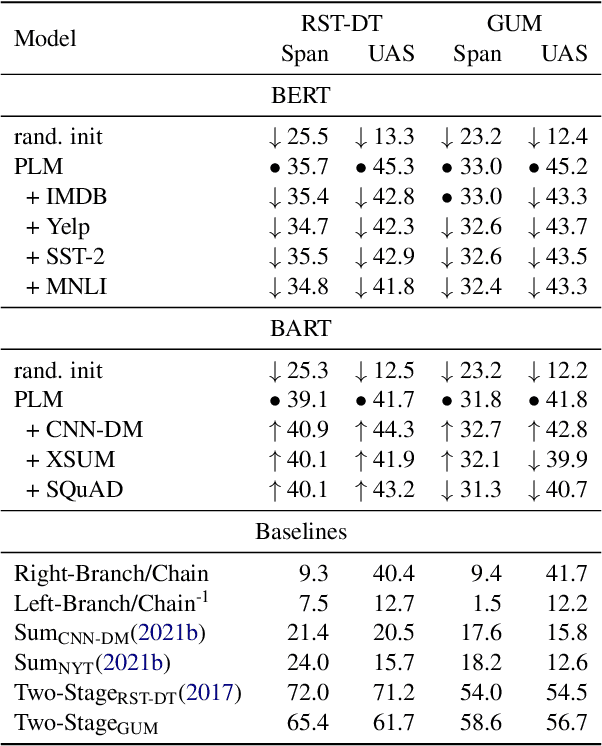
With a growing number of BERTology work analyzing different components of pre-trained language models, we extend this line of research through an in-depth analysis of discourse information in pre-trained and fine-tuned language models. We move beyond prior work along three dimensions: First, we describe a novel approach to infer discourse structures from arbitrarily long documents. Second, we propose a new type of analysis to explore where and how accurately intrinsic discourse is captured in the BERT and BART models. Finally, we assess how similar the generated structures are to a variety of baselines as well as their distribution within and between models.
* 9 pages
Predicting Above-Sentence Discourse Structure using Distant Supervision from Topic Segmentation
Dec 12, 2021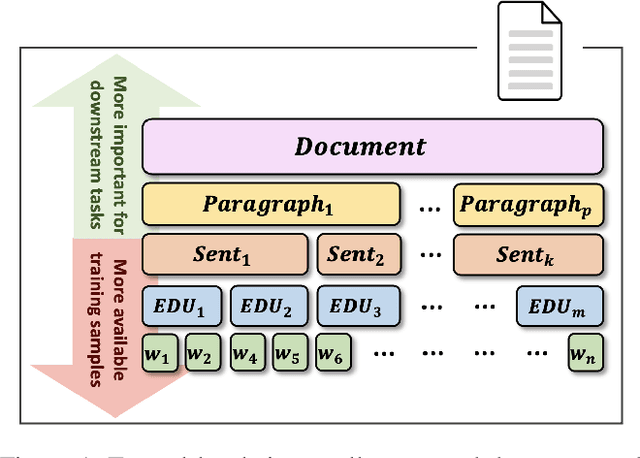
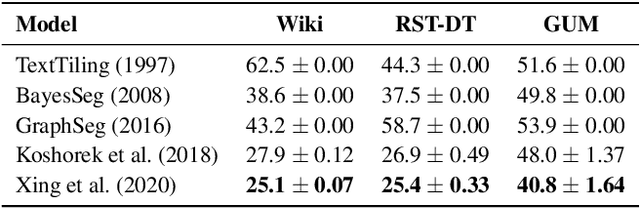
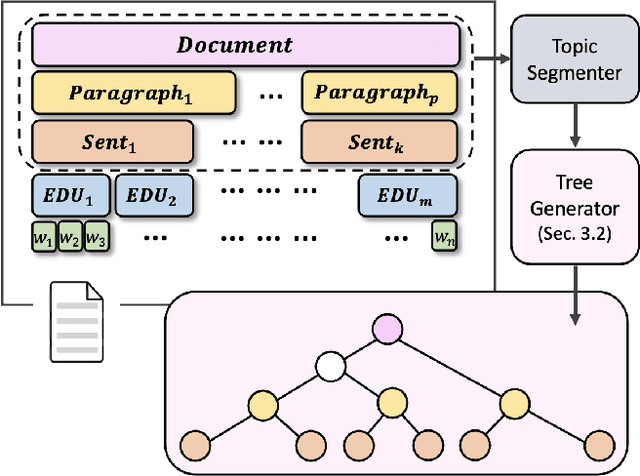
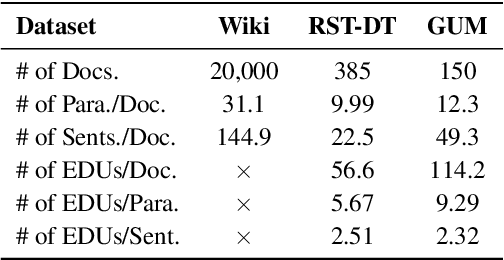
RST-style discourse parsing plays a vital role in many NLP tasks, revealing the underlying semantic/pragmatic structure of potentially complex and diverse documents. Despite its importance, one of the most prevailing limitations in modern day discourse parsing is the lack of large-scale datasets. To overcome the data sparsity issue, distantly supervised approaches from tasks like sentiment analysis and summarization have been recently proposed. Here, we extend this line of research by exploiting distant supervision from topic segmentation, which can arguably provide a strong and oftentimes complementary signal for high-level discourse structures. Experiments on two human-annotated discourse treebanks confirm that our proposal generates accurate tree structures on sentence and paragraph level, consistently outperforming previous distantly supervised models on the sentence-to-document task and occasionally reaching even higher scores on the sentence-to-paragraph level.
Human Interpretation and Exploitation of Self-attention Patterns in Transformers: A Case Study in Extractive Summarization
Dec 10, 2021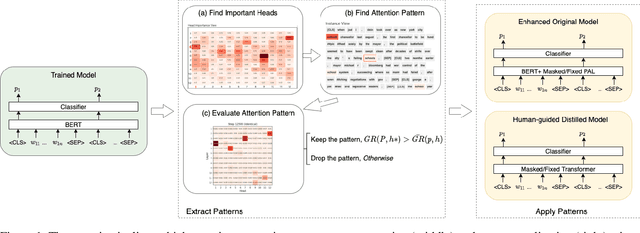
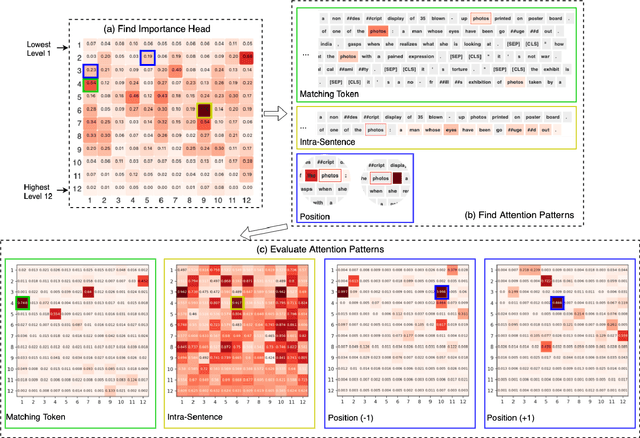
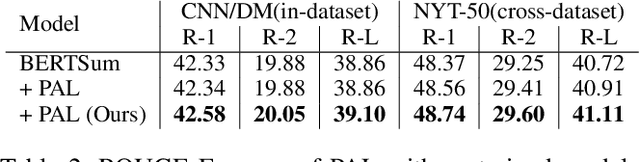
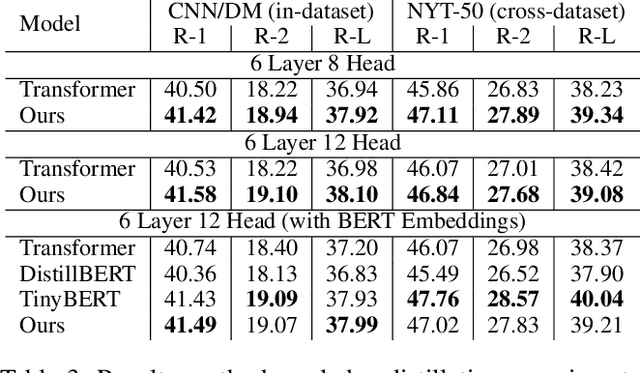
The transformer multi-head self-attention mechanism has been thoroughly investigated recently. On one hand, researchers are interested in understanding why and how transformers work. On the other hand, they propose new attention augmentation methods to make transformers more accurate, efficient and interpretable. In this paper, we synergize these two lines of research in a human-in-the-loop pipeline to first find important task-specific attention patterns. Then those patterns are applied, not only to the original model, but also to smaller models, as a human-guided knowledge distillation process. The benefits of our pipeline are demonstrated in a case study with the extractive summarization task. After finding three meaningful attention patterns in the popular BERTSum model, experiments indicate that when we inject such patterns, both the original and the smaller model show improvements in performance and arguably interpretability.
PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
Oct 16, 2021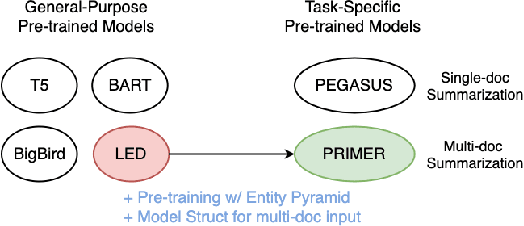
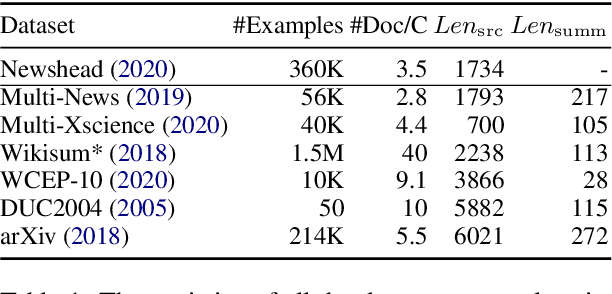
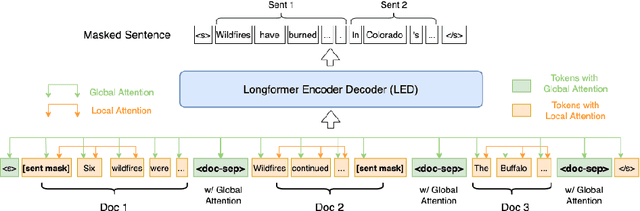
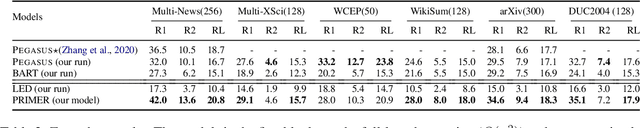
Recently proposed pre-trained generation models achieve strong performance on single-document summarization benchmarks. However, most of them are pre-trained with general-purpose objectives and mainly aim to process single document inputs. In this paper, we propose PRIMER, a pre-trained model for multi-document representation with focus on summarization that reduces the need for dataset-specific architectures and large amounts of fine-tuning labeled data. Specifically, we adopt the Longformer architecture with proper input transformation and global attention to fit for multi-document inputs, and we use Gap Sentence Generation objective with a new strategy to select salient sentences for the whole cluster, called Entity Pyramid, to teach the model to select and aggregate information across a cluster of related documents. With extensive experiments on 6 multi-document summarization datasets from 3 different domains on the zero-shot, few-shot, and full-supervised settings, our model, PRIMER, outperforms current state-of-the-art models on most of these settings with large margins. Code and pre-trained models are released at https://github.com/allenai/PRIMER
T3-Vis: a visual analytic framework for Training and fine-Tuning Transformers in NLP
Aug 31, 2021

Transformers are the dominant architecture in NLP, but their training and fine-tuning is still very challenging. In this paper, we present the design and implementation of a visual analytic framework for assisting researchers in such process, by providing them with valuable insights about the model's intrinsic properties and behaviours. Our framework offers an intuitive overview that allows the user to explore different facets of the model (e.g., hidden states, attention) through interactive visualization, and allows a suite of built-in algorithms that compute the importance of model components and different parts of the input sequence. Case studies and feedback from a user focus group indicate that the framework is useful, and suggest several improvements.
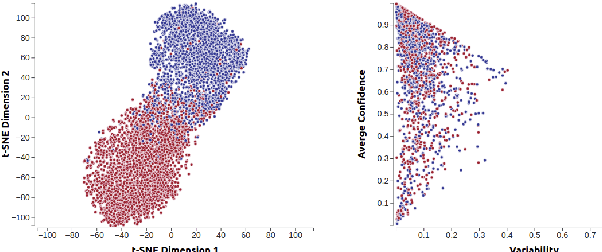
ConVIScope: Visual Analytics for Exploring Patient Conversations
Aug 30, 2021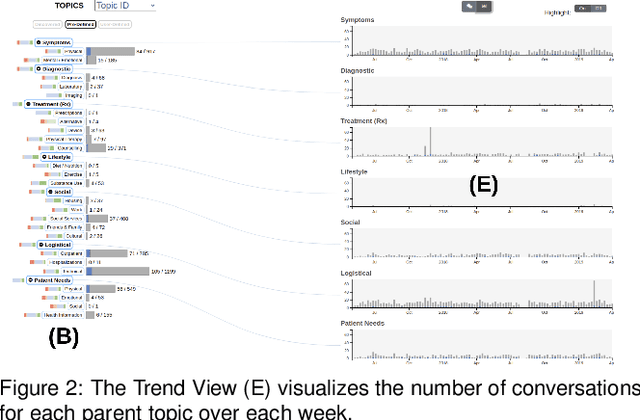
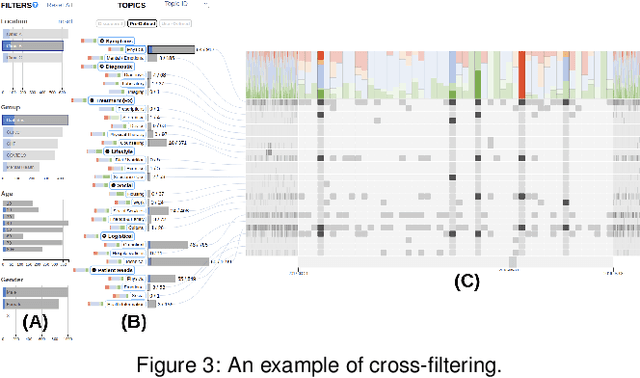
The proliferation of text messaging for mobile health is generating a large amount of patient-doctor conversations that can be extremely valuable to health care professionals. We present ConVIScope, a visual text analytic system that tightly integrates interactive visualization with natural language processing in analyzing patient-doctor conversations. ConVIScope was developed in collaboration with healthcare professionals following a user-centered iterative design. Case studies with six domain experts suggest the potential utility of ConVIScope and reveal lessons for further developments.
Improving Unsupervised Dialogue Topic Segmentation with Utterance-Pair Coherence Scoring
Jun 12, 2021
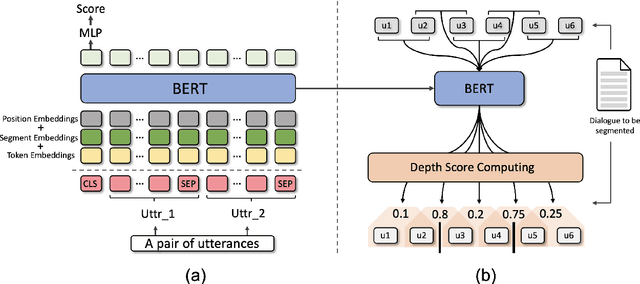
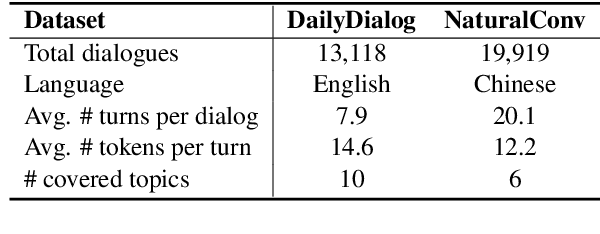
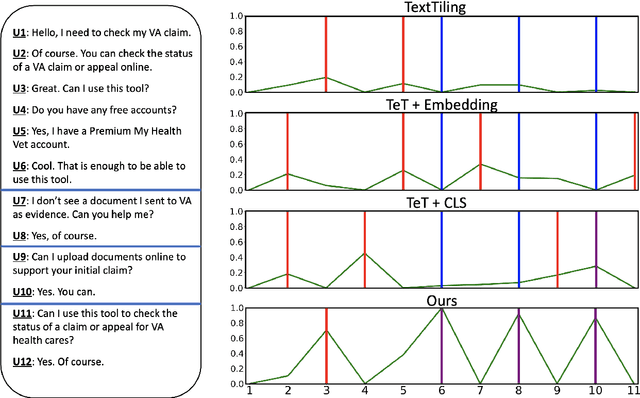
Dialogue topic segmentation is critical in several dialogue modeling problems. However, popular unsupervised approaches only exploit surface features in assessing topical coherence among utterances. In this work, we address this limitation by leveraging supervisory signals from the utterance-pair coherence scoring task. First, we present a simple yet effective strategy to generate a training corpus for utterance-pair coherence scoring. Then, we train a BERT-based neural utterance-pair coherence model with the obtained training corpus. Finally, such model is used to measure the topical relevance between utterances, acting as the basis of the segmentation inference. Experiments on three public datasets in English and Chinese demonstrate that our proposal outperforms the state-of-the-art baselines.
W-RST: Towards a Weighted RST-style Discourse Framework
Jun 04, 2021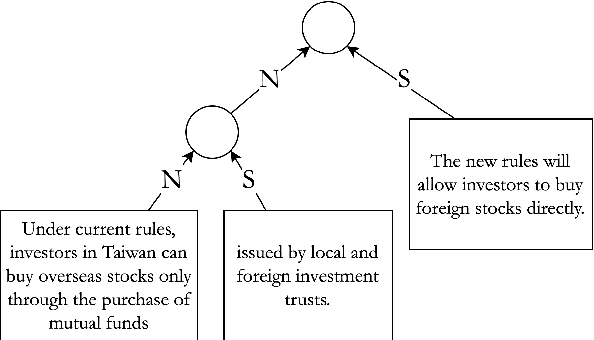
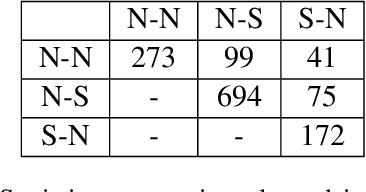
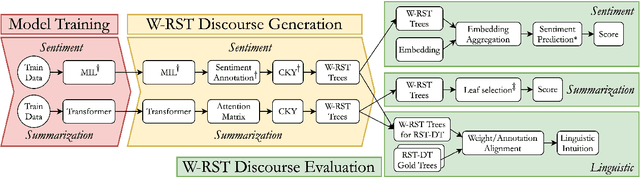
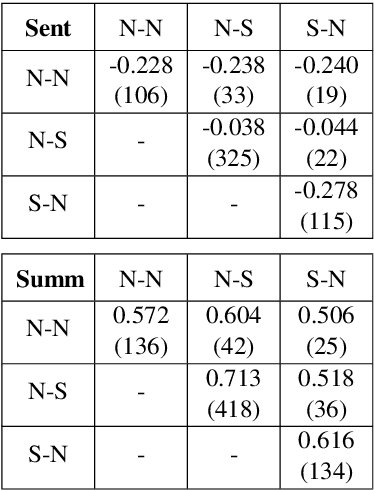
Aiming for a better integration of data-driven and linguistically-inspired approaches, we explore whether RST Nuclearity, assigning a binary assessment of importance between text segments, can be replaced by automatically generated, real-valued scores, in what we call a Weighted-RST framework. In particular, we find that weighted discourse trees from auxiliary tasks can benefit key NLP downstream applications, compared to nuclearity-centered approaches. We further show that real-valued importance distributions partially and interestingly align with the assessment and uncertainty of human annotators.
Demoting the Lead Bias in News Summarization via Alternating Adversarial Learning
May 29, 2021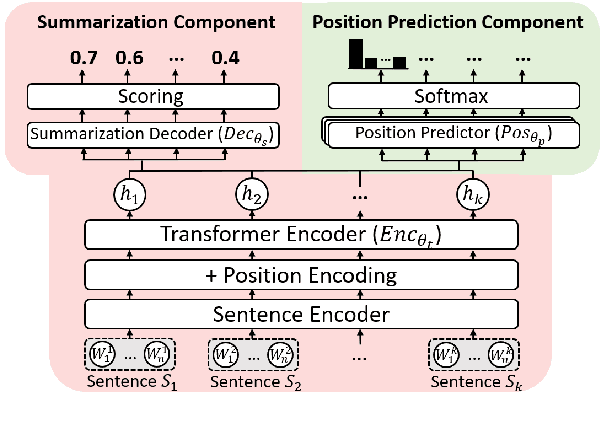
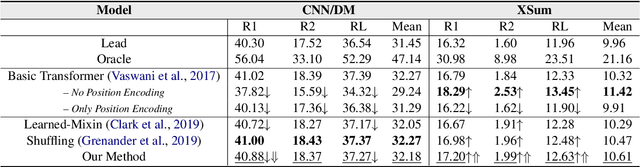
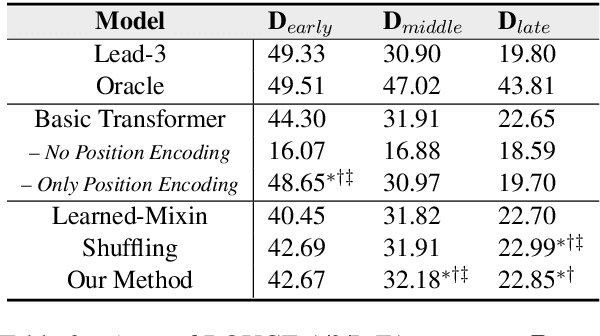
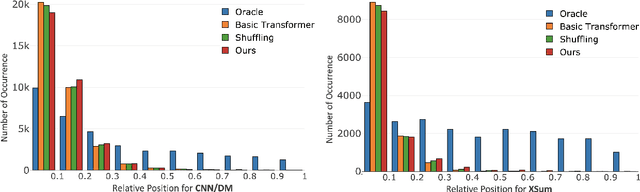
In news articles the lead bias is a common phenomenon that usually dominates the learning signals for neural extractive summarizers, severely limiting their performance on data with different or even no bias. In this paper, we introduce a novel technique to demote lead bias and make the summarizer focus more on the content semantics. Experiments on two news corpora with different degrees of lead bias show that our method can effectively demote the model's learned lead bias and improve its generality on out-of-distribution data, with little to no performance loss on in-distribution data.
Predicting Discourse Trees from Transformer-based Neural Summarizers
Apr 14, 2021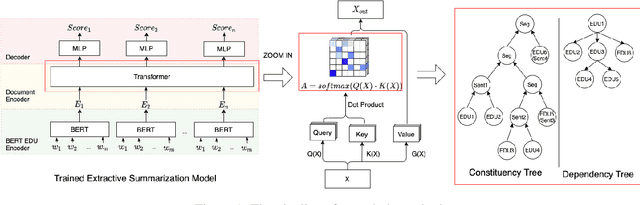
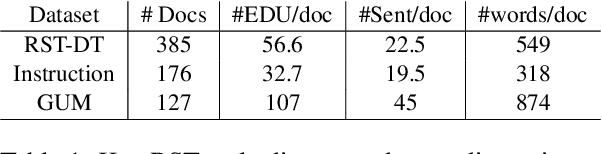
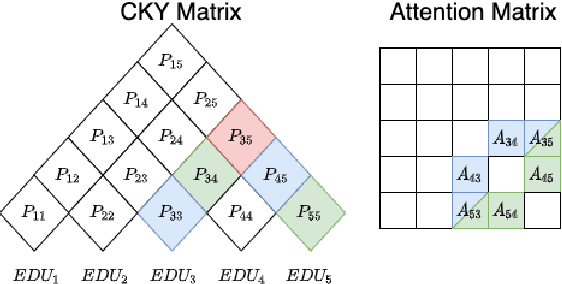
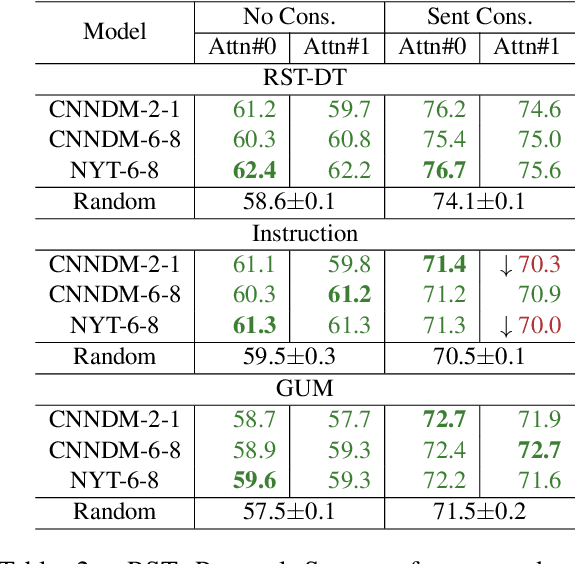
Previous work indicates that discourse information benefits summarization. In this paper, we explore whether this synergy between discourse and summarization is bidirectional, by inferring document-level discourse trees from pre-trained neural summarizers. In particular, we generate unlabeled RST-style discourse trees from the self-attention matrices of the transformer model. Experiments across models and datasets reveal that the summarizer learns both, dependency- and constituency-style discourse information, which is typically encoded in a single head, covering long- and short-distance discourse dependencies. Overall, the experimental results suggest that the learned discourse information is general and transferable inter-domain.