 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Neural-LLM Pipeline for Morphological Glossing in Endangered Language Documentation: A Case Study of Jungar Tuvan
Mar 01, 2026Interlinear glossed text (IGT) creation remains a major bottleneck in linguistic documentation and fieldwork, particularly for low-resource morphologically rich languages. We present a hybrid automatic glossing pipeline that combines neural sequence labeling with large language model (LLM) post-correction, evaluated on Jungar Tuvan, a low-resource Turkic language. Through systematic ablation studies, we show that retrieval-augmented prompting provides substantial gains over random example selection. We further find that morpheme dictionaries paradoxically hurt performance compared to providing no dictionary at all in most cases, and that performance scales approximately logarithmically with the number of few-shot examples. Most significantly, our two-stage pipeline combining a BiLSTM-CRF model with LLM post-correction yields substantial gains for most models, achieving meaningful reductions in annotation workload. Drawing on these findings, we establish concrete design principles for integrating structured prediction models with LLM reasoning in morphologically complex fieldwork contexts. These principles demonstrate that hybrid architectures offer a promising direction for computationally light solutions to automatic linguistic annotation in endangered language documentation.
A Sociophonetic Analysis of Racial Bias in Commercial ASR Systems Using the Pacific Northwest English Corpus
Oct 26, 2025



This paper presents a systematic evaluation of racial bias in four major commercial automatic speech recognition (ASR) systems using the Pacific Northwest English (PNWE) corpus. We analyze transcription accuracy across speakers from four ethnic backgrounds (African American, Caucasian American, ChicanX, and Yakama) and examine how sociophonetic variation contributes to differential system performance. We introduce a heuristically-determined Phonetic Error Rate (PER) metric that links recognition errors to specific linguistically motivated variables derived from sociophonetic annotation. Our analysis of eleven sociophonetic features reveals that vowel quality variation, particularly resistance to the low-back merger and pre-nasal merger patterns, is systematically associated with differential error rates across ethnic groups, with the most pronounced effects for African American speakers across all evaluated systems. These findings demonstrate that acoustic modeling of dialectal phonetic variation, rather than lexical or syntactic factors, remains a primary source of bias in commercial ASR systems. The study establishes the PNWE corpus as a valuable resource for bias evaluation in speech technologies and provides actionable guidance for improving ASR performance through targeted representation of sociophonetic diversity in training data.
The Limits of Data Scaling: Sub-token Utilization and Acoustic Saturation in Multilingual ASR
Oct 26, 2025



How much audio is needed to fully observe a multilingual ASR model's learned sub-token inventory across languages, and does data disparity in multilingual pre-training affect how these tokens are utilized during inference? We address this question by analyzing Whisper's decoding behavior during inference across 49 languages. By logging decoding candidate sub-tokens and tracking their cumulative discovery over time, we study the utilization pattern of the model's sub-token space. Results show that the total number of discovered tokens remains largely independent of a language's pre-training hours, indicating that data disparity does not strongly influence lexical diversity in the model's hypothesis space. Sub-token discovery rates follow a consistent exponential saturation pattern across languages, suggesting a stable time window after which additional audio yields minimal new sub-token activation. We refer to this convergence threshold as acoustic saturation time (AST). Further analyses of rank-frequency distributions reveal Zipf-like patterns better modeled by a Zipf-Mandelbrot law, and mean sub-token length shows a positive correlation with resource level. Additionally, those metrics show more favorable patterns for languages in the Latin script than those in scripts such as Cyrillic, CJK, and Semitic. Together, our study suggests that sub-token utilization during multilingual ASR inference is constrained more by the statistical, typological, and orthographic structure of the speech than by training data scale, providing an empirical basis for more equitable corpus construction and cross-lingual evaluation.
TEII: Think, Explain, Interact and Iterate with Large Language Models to Solve Cross-lingual Emotion Detection
May 27, 2024



Cross-lingual emotion detection allows us to analyze global trends, public opinion, and social phenomena at scale. We participated in the Explainability of Cross-lingual Emotion Detection (EXALT) shared task, achieving an F1-score of 0.6046 on the evaluation set for the emotion detection sub-task. Our system outperformed the baseline by more than 0.16 F1-score absolute, and ranked second amongst competing systems. We conducted experiments using fine-tuning, zero-shot learning, and few-shot learning for Large Language Model (LLM)-based models as well as embedding-based BiLSTM and KNN for non-LLM-based techniques. Additionally, we introduced two novel methods: the Multi-Iteration Agentic Workflow and the Multi-Binary-Classifier Agentic Workflow. We found that LLM-based approaches provided good performance on multilingual emotion detection. Furthermore, ensembles combining all our experimented models yielded higher F1-scores than any single approach alone.
A Masked Segmental Language Model for Unsupervised Natural Language Segmentation
Apr 16, 2021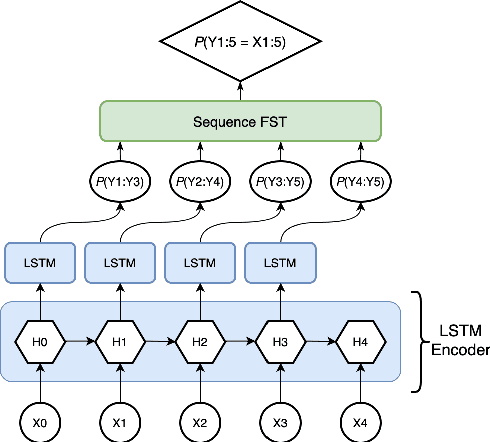
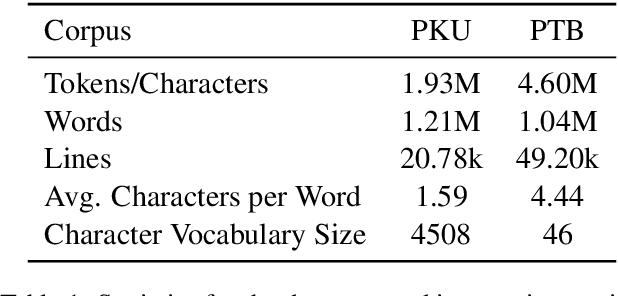
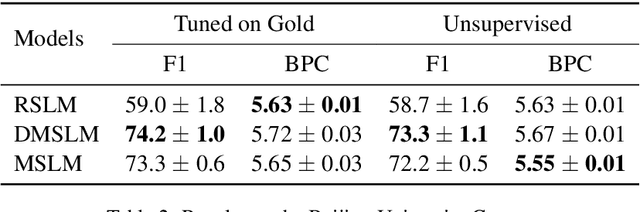
Segmentation remains an important preprocessing step both in languages where "words" or other important syntactic/semantic units (like morphemes) are not clearly delineated by white space, as well as when dealing with continuous speech data, where there is often no meaningful pause between words. Near-perfect supervised methods have been developed for use in resource-rich languages such as Chinese, but many of the world's languages are both morphologically complex, and have no large dataset of "gold" segmentations into meaningful units. To solve this problem, we propose a new type of Segmental Language Model (Sun and Deng, 2018; Kawakami et al., 2019; Wang et al., 2021) for use in both unsupervised and lightly supervised segmentation tasks. We introduce a Masked Segmental Language Model (MSLM) built on a span-masking transformer architecture, harnessing the power of a bi-directional masked modeling context and attention. In a series of experiments, our model consistently outperforms Recurrent SLMs on Chinese (PKU Corpus) in segmentation quality, and performs similarly to the Recurrent model on English (PTB). We conclude by discussing the different challenges posed in segmenting phonemic-type writing systems.
Pardon the Interruption: An Analysis of Gender and Turn-Taking in U.S. Supreme Court Oral Arguments
Sep 15, 2020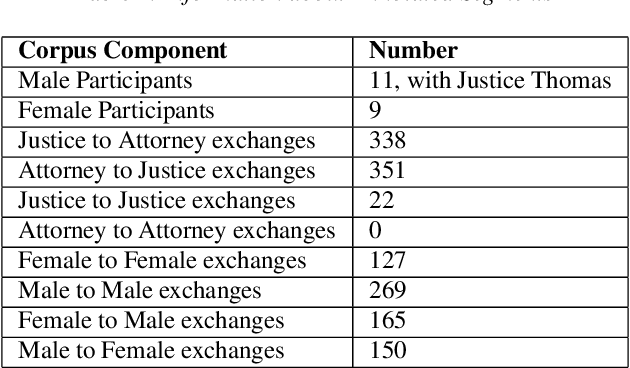
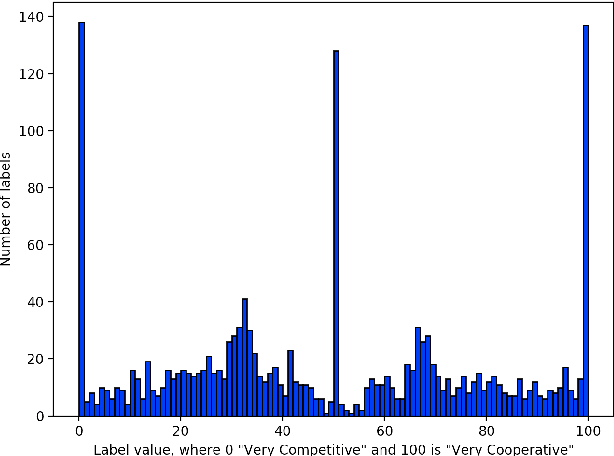
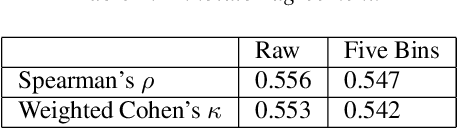
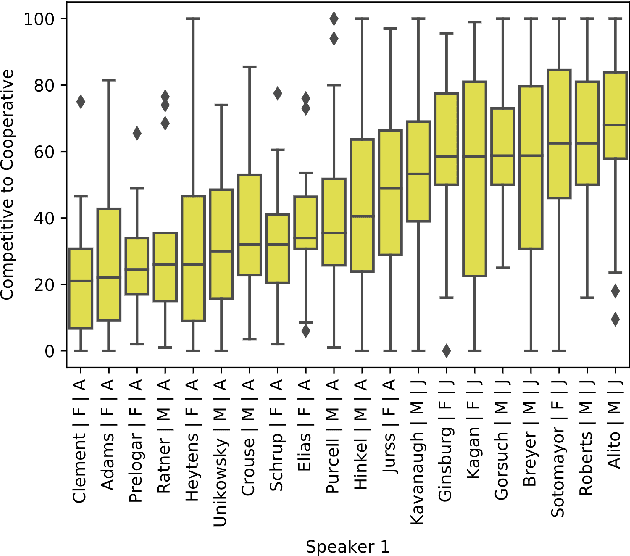
This study presents a corpus of turn changes between speakers in U.S. Supreme Court oral arguments. Each turn change is labeled on a spectrum of "cooperative" to "competitive" by a human annotator with legal experience in the United States. We analyze the relationship between speech features, the nature of exchanges, and the gender and legal role of the speakers. Finally, we demonstrate that the models can be used to predict the label of an exchange with moderate success. The automatic classification of the nature of exchanges indicates that future studies of turn-taking in oral arguments can rely on larger, unlabeled corpora.
Fast transcription of speech in low-resource languages
Sep 16, 2019
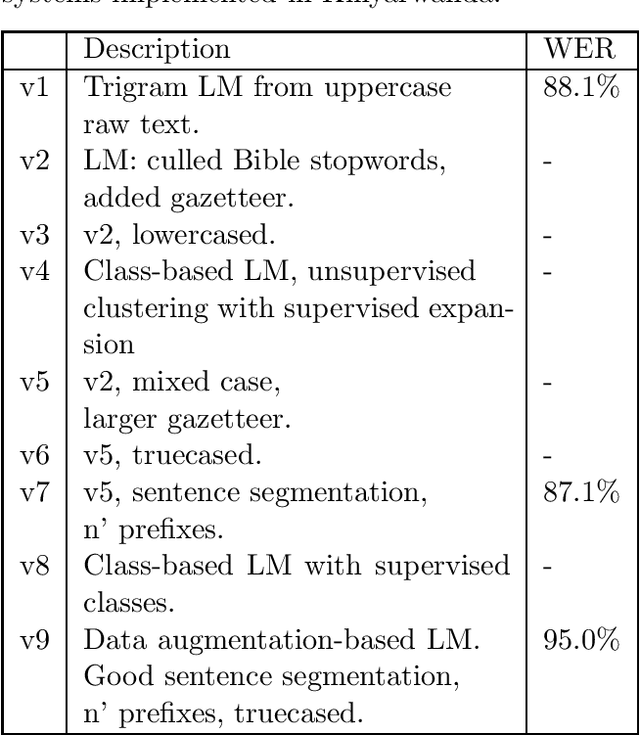

We present software that, in only a few hours, transcribes forty hours of recorded speech in a surprise language, using only a few tens of megabytes of noisy text in that language, and a zero-resource grapheme to phoneme (G2P) table. A pretrained acoustic model maps acoustic features to phonemes; a reversed G2P maps these to graphemes; then a language model maps these to a most-likely grapheme sequence, i.e., a transcription. This software has worked successfully with corpora in Arabic, Assam, Kinyarwanda, Russian, Sinhalese, Swahili, Tagalog, and Tamil.