 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou are your Metadata: Identification and Obfuscation of Social Media Users using Metadata Information
May 14, 2018
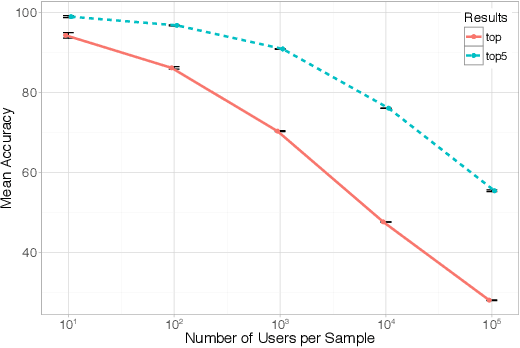
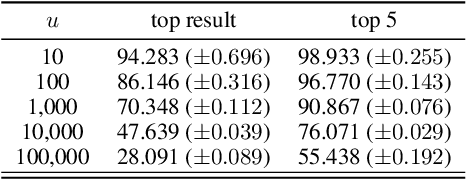
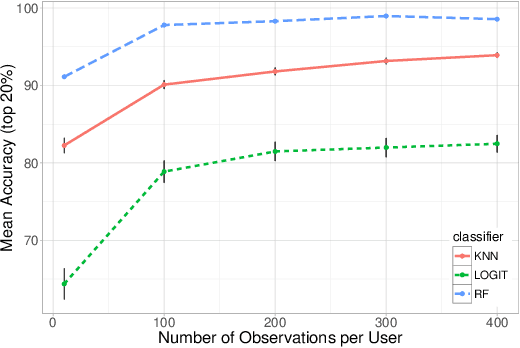
Metadata are associated to most of the information we produce in our daily interactions and communication in the digital world. Yet, surprisingly, metadata are often still catergorized as non-sensitive. Indeed, in the past, researchers and practitioners have mainly focused on the problem of the identification of a user from the content of a message. In this paper, we use Twitter as a case study to quantify the uniqueness of the association between metadata and user identity and to understand the effectiveness of potential obfuscation strategies. More specifically, we analyze atomic fields in the metadata and systematically combine them in an effort to classify new tweets as belonging to an account using different machine learning algorithms of increasing complexity. We demonstrate that through the application of a supervised learning algorithm, we are able to identify any user in a group of 10,000 with approximately 96.7% accuracy. Moreover, if we broaden the scope of our search and consider the 10 most likely candidates we increase the accuracy of the model to 99.22%. We also found that data obfuscation is hard and ineffective for this type of data: even after perturbing 60% of the training data, it is still possible to classify users with an accuracy higher than 95%. These results have strong implications in terms of the design of metadata obfuscation strategies, for example for data set release, not only for Twitter, but, more generally, for most social media platforms.
MaMaDroid: Detecting Android Malware by Building Markov Chains of Behavioral Models (Extended Version)
Nov 20, 2017
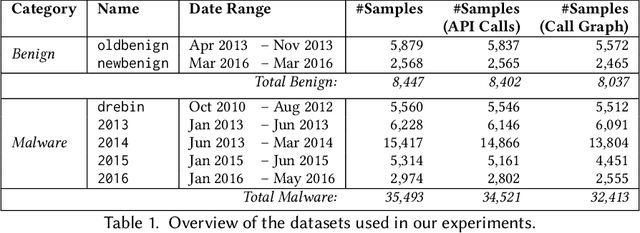
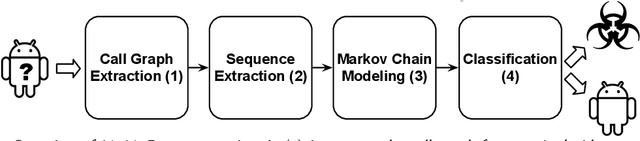
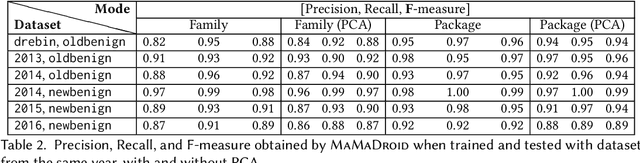
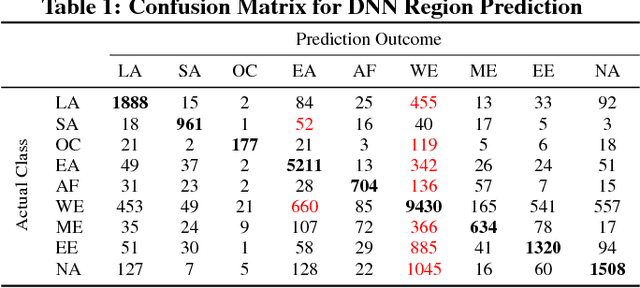
As Android becomes increasingly popular, so does malware targeting it, this motivating the research community to propose many different detection techniques. However, the constant evolution of the Android ecosystem, and of malware itself, makes it hard to design robust tools that can operate for long periods of time without the need for modifications or costly re-training. Aiming to address this issue, we set to detect malware from a behavioral point of view, modeled as the sequence of abstracted API calls. We introduce MaMaDroid, a static-analysis based system that abstracts app's API calls to their class, package, or family, and builds a model from their sequences obtained from the call graph of an app as Markov chains. This ensures that the model is more resilient to API changes and the features set is of manageable size. We evaluate MaMaDroid using a dataset of 8.5K benign and 35.5K malicious apps collected over a period of six years, showing that it effectively detects malware (with up to 0.99 F-measure) and keeps its detection capabilities for long periods of time (up to 0.87 F-measure two years after training). We also show that MaMaDroid remarkably improves over DroidAPIMiner, a state-of-the-art detection system that relies on the frequency of (raw) API calls. Aiming to assess whether MaMaDroid's effectiveness mainly stems from the API abstraction or from the sequencing modeling, we also evaluate a variant of it that uses frequency (instead of sequences), of abstracted API calls. We find that it is not as accurate, failing to capture maliciousness when trained on malware samples including API calls that are equally or more frequently used by benign apps.
Email Babel: Does Language Affect Criminal Activity in Compromised Webmail Accounts?
Apr 25, 2017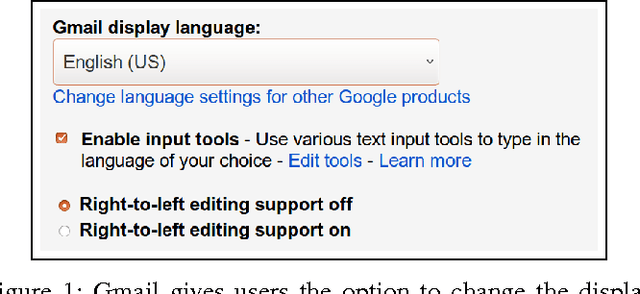
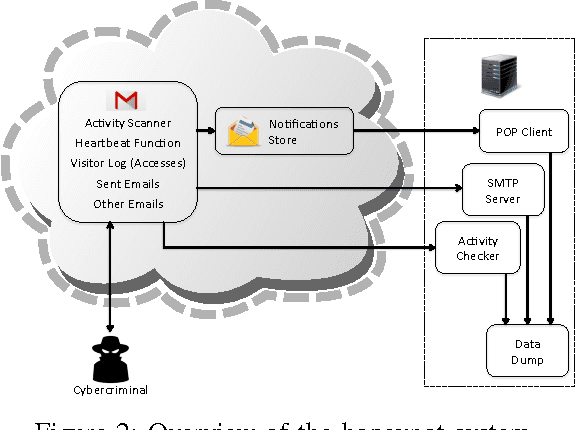

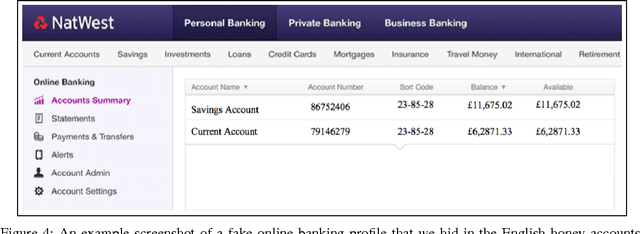
We set out to understand the effects of differing language on the ability of cybercriminals to navigate webmail accounts and locate sensitive information in them. To this end, we configured thirty Gmail honeypot accounts with English, Romanian, and Greek language settings. We populated the accounts with email messages in those languages by subscribing them to selected online newsletters. We hid email messages about fake bank accounts in fifteen of the accounts to mimic real-world webmail users that sometimes store sensitive information in their accounts. We then leaked credentials to the honey accounts via paste sites on the Surface Web and the Dark Web, and collected data for fifteen days. Our statistical analyses on the data show that cybercriminals are more likely to discover sensitive information (bank account information) in the Greek accounts than the remaining accounts, contrary to the expectation that Greek ought to constitute a barrier to the understanding of non-Greek visitors to the Greek accounts. We also extracted the important words among the emails that cybercriminals accessed (as an approximation of the keywords that they searched for within the honey accounts), and found that financial terms featured among the top words. In summary, we show that language plays a significant role in the ability of cybercriminals to access sensitive information hidden in compromised webmail accounts.
Kissing Cuisines: Exploring Worldwide Culinary Habits on the Web
Apr 25, 2017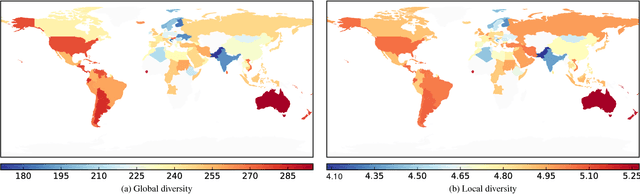
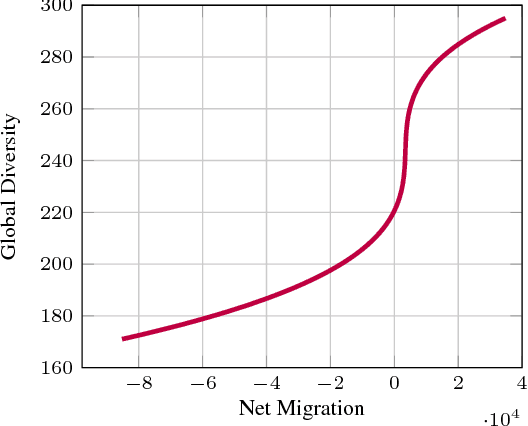
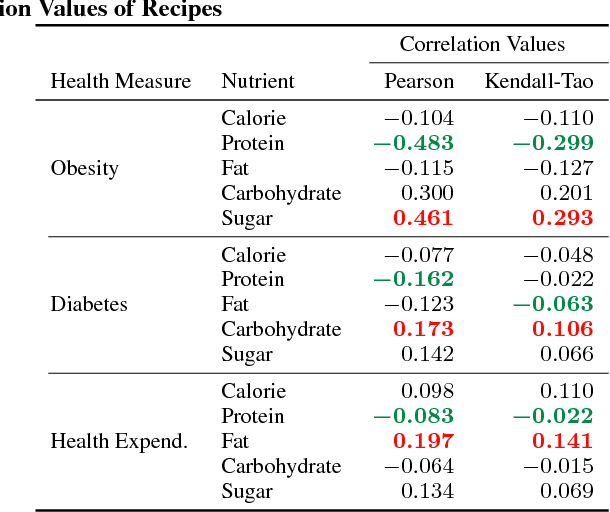
Food and nutrition occupy an increasingly prevalent space on the web, and dishes and recipes shared online provide an invaluable mirror into culinary cultures and attitudes around the world. More specifically, ingredients, flavors, and nutrition information become strong signals of the taste preferences of individuals and civilizations. However, there is little understanding of these palate varieties. In this paper, we present a large-scale study of recipes published on the web and their content, aiming to understand cuisines and culinary habits around the world. Using a database of more than 157K recipes from over 200 different cuisines, we analyze ingredients, flavors, and nutritional values which distinguish dishes from different regions, and use this knowledge to assess the predictability of recipes from different cuisines. We then use country health statistics to understand the relation between these factors and health indicators of different nations, such as obesity, diabetes, migration, and health expenditure. Our results confirm the strong effects of geographical and cultural similarities on recipes, health indicators, and culinary preferences across the globe.
Measuring #GamerGate: A Tale of Hate, Sexism, and Bullying
Feb 24, 2017

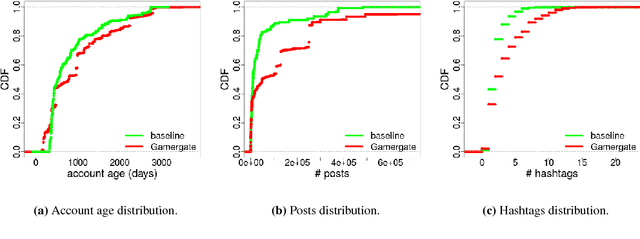
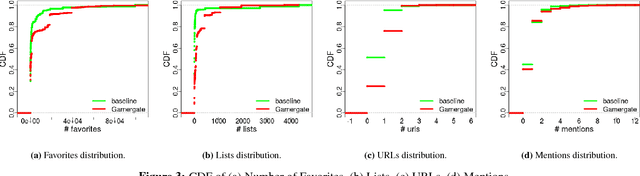
Over the past few years, online aggression and abusive behaviors have occurred in many different forms and on a variety of platforms. In extreme cases, these incidents have evolved into hate, discrimination, and bullying, and even materialized into real-world threats and attacks against individuals or groups. In this paper, we study the Gamergate controversy. Started in August 2014 in the online gaming world, it quickly spread across various social networking platforms, ultimately leading to many incidents of cyberbullying and cyberaggression. We focus on Twitter, presenting a measurement study of a dataset of 340k unique users and 1.6M tweets to study the properties of these users, the content they post, and how they differ from random Twitter users. We find that users involved in this "Twitter war" tend to have more friends and followers, are generally more engaged and post tweets with negative sentiment, less joy, and more hate than random users. We also perform preliminary measurements on how the Twitter suspension mechanism deals with such abusive behaviors. While we focus on Gamergate, our methodology to collect and analyze tweets related to aggressive and bullying activities is of independent interest.