 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Cross Subject EEG Decoding
Aug 19, 2023



Recently, deep learning has shown to be effective for Electroencephalography (EEG) decoding tasks. Yet, its performance can be negatively influenced by two key factors: 1) the high variance and different types of corruption that are inherent in the signal, 2) the EEG datasets are usually relatively small given the acquisition cost, annotation cost and amount of effort needed. Data augmentation approaches for alleviation of this problem have been empirically studied, with augmentation operations on spatial domain, time domain or frequency domain handcrafted based on expertise of domain knowledge. In this work, we propose a principled approach to perform dynamic evolution on the data for improvement of decoding robustness. The approach is based on distributionally robust optimization and achieves robustness by optimizing on a family of evolved data distributions instead of the single training data distribution. We derived a general data evolution framework based on Wasserstein gradient flow (WGF) and provides two different forms of evolution within the framework. Intuitively, the evolution process helps the EEG decoder to learn more robust and diverse features. It is worth mentioning that the proposed approach can be readily integrated with other data augmentation approaches for further improvements. We performed extensive experiments on the proposed approach and tested its performance on different types of corrupted EEG signals. The model significantly outperforms competitive baselines on challenging decoding scenarios.
ChatGPT in the Age of Generative AI and Large Language Models: A Concise Survey
Jul 15, 2023



ChatGPT is a large language model (LLM) created by OpenAI that has been carefully trained on a large amount of data. It has revolutionized the field of natural language processing (NLP) and has pushed the boundaries of LLM capabilities. ChatGPT has played a pivotal role in enabling widespread public interaction with generative artificial intelligence (GAI) on a large scale. It has also sparked research interest in developing similar technologies and investigating their applications and implications. In this paper, our primary goal is to provide a concise survey on the current lines of research on ChatGPT and its evolution. We considered both the glass box and black box views of ChatGPT, encompassing the components and foundational elements of the technology, as well as its applications, impacts, and implications. The glass box approach focuses on understanding the inner workings of the technology, and the black box approach embraces it as a complex system, and thus examines its inputs, outputs, and effects. This paves the way for a comprehensive exploration of the technology and provides a road map for further research and experimentation. We also lay out essential foundational literature on LLMs and GAI in general and their connection with ChatGPT. This overview sheds light on existing and missing research lines in the emerging field of LLMs, benefiting both public users and developers. Furthermore, the paper delves into the broad spectrum of applications and significant concerns in fields such as education, research, healthcare, finance, etc.
More Synergy, Less Redundancy: Exploiting Joint Mutual Information for Self-Supervised Learning
Jul 02, 2023



Self-supervised learning (SSL) is now a serious competitor for supervised learning, even though it does not require data annotation. Several baselines have attempted to make SSL models exploit information about data distribution, and less dependent on the augmentation effect. However, there is no clear consensus on whether maximizing or minimizing the mutual information between representations of augmentation views practically contribute to improvement or degradation in performance of SSL models. This paper is a fundamental work where, we investigate role of mutual information in SSL, and reformulate the problem of SSL in the context of a new perspective on mutual information. To this end, we consider joint mutual information from the perspective of partial information decomposition (PID) as a key step in \textbf{reliable multivariate information measurement}. PID enables us to decompose joint mutual information into three important components, namely, unique information, redundant information and synergistic information. Our framework aims for minimizing the redundant information between views and the desired target representation while maximizing the synergistic information at the same time. Our experiments lead to a re-calibration of two redundancy reduction baselines, and a proposal for a new SSL training protocol. Extensive experimental results on multiple datasets and two downstream tasks show the effectiveness of this framework.
A Robust Likelihood Model for Novelty Detection
Jun 06, 2023Current approaches to novelty or anomaly detection are based on deep neural networks. Despite their effectiveness, neural networks are also vulnerable to imperceptible deformations of the input data. This is a serious issue in critical applications, or when data alterations are generated by an adversarial attack. While this is a known problem that has been studied in recent years for the case of supervised learning, the case of novelty detection has received very limited attention. Indeed, in this latter setting the learning is typically unsupervised because outlier data is not available during training, and new approaches for this case need to be investigated. We propose a new prior that aims at learning a robust likelihood for the novelty test, as a defense against attacks. We also integrate the same prior with a state-of-the-art novelty detection approach. Because of the geometric properties of that approach, the resulting robust training is computationally very efficient. An initial evaluation of the method indicates that it is effective at improving performance with respect to the standard models in the absence and presence of attacks.
Self-supervised Interest Point Detection and Description for Fisheye and Perspective Images
Jun 02, 2023



Keypoint detection and matching is a fundamental task in many computer vision problems, from shape reconstruction, to structure from motion, to AR/VR applications and robotics. It is a well-studied problem with remarkable successes such as SIFT, and more recent deep learning approaches. While great robustness is exhibited by these techniques with respect to noise, illumination variation, and rigid motion transformations, less attention has been placed on image distortion sensitivity. In this work, we focus on the case when this is caused by the geometry of the cameras used for image acquisition, and consider the keypoint detection and matching problem between the hybrid scenario of a fisheye and a projective image. We build on a state-of-the-art approach and derive a self-supervised procedure that enables training an interest point detector and descriptor network. We also collected two new datasets for additional training and testing in this unexplored scenario, and we demonstrate that current approaches are suboptimal because they are designed to work in traditional projective conditions, while the proposed approach turns out to be the most effective.
CellTranspose: Few-shot Domain Adaptation for Cellular Instance Segmentation
Dec 28, 2022Automated cellular instance segmentation is a process utilized for accelerating biological research for the past two decades, and recent advancements have produced higher quality results with less effort from the biologist. Most current endeavors focus on completely cutting the researcher out of the picture by generating highly generalized models. However, these models invariably fail when faced with novel data, distributed differently than the ones used for training. Rather than approaching the problem with methods that presume the availability of large amounts of target data and computing power for retraining, in this work we address the even greater challenge of designing an approach that requires minimal amounts of new annotated data as well as training time. We do so by designing specialized contrastive losses that leverage the few annotated samples very efficiently. A large set of results show that 3 to 5 annotations lead to models with accuracy that: 1) significantly mitigate the covariate shift effects; 2) matches or surpasses other adaptation methods; 3) even approaches methods that have been fully retrained on the target distribution. The adaptation training is only a few minutes, paving a path towards a balance between model performance, computing requirements and expert-level annotation needs.
Joint Discriminative and Metric Embedding Learning for Person Re-Identification
Dec 28, 2022Person re-identification is a challenging task because of the high intra-class variance induced by the unrestricted nuisance factors of variations such as pose, illumination, viewpoint, background, and sensor noise. Recent approaches postulate that powerful architectures have the capacity to learn feature representations invariant to nuisance factors, by training them with losses that minimize intra-class variance and maximize inter-class separation, without modeling nuisance factors explicitly. The dominant approaches use either a discriminative loss with margin, like the softmax loss with the additive angular margin, or a metric learning loss, like the triplet loss with batch hard mining of triplets. Since the softmax imposes feature normalization, it limits the gradient flow supervising the feature embedding. We address this by joining the losses and leveraging the triplet loss as a proxy for the missing gradients. We further improve invariance to nuisance factors by adding the discriminative task of predicting attributes. Our extensive evaluation highlights that when only a holistic representation is learned, we consistently outperform the state-of-the-art on the three most challenging datasets. Such representations are easier to deploy in practical systems. Finally, we found that joining the losses removes the requirement for having a margin in the softmax loss while increasing performance.
Learning Representations for Masked Facial Recovery
Dec 28, 2022The pandemic of these very recent years has led to a dramatic increase in people wearing protective masks in public venues. This poses obvious challenges to the pervasive use of face recognition technology that now is suffering a decline in performance. One way to address the problem is to revert to face recovery methods as a preprocessing step. Current approaches to face reconstruction and manipulation leverage the ability to model the face manifold, but tend to be generic. We introduce a method that is specific for the recovery of the face image from an image of the same individual wearing a mask. We do so by designing a specialized GAN inversion method, based on an appropriate set of losses for learning an unmasking encoder. With extensive experiments, we show that the approach is effective at unmasking face images. In addition, we also show that the identity information is preserved sufficiently well to improve face verification performance based on several face recognition benchmark datasets.
FUSSL: Fuzzy Uncertain Self Supervised Learning
Oct 28, 2022



Self supervised learning (SSL) has become a very successful technique to harness the power of unlabeled data, with no annotation effort. A number of developed approaches are evolving with the goal of outperforming supervised alternatives, which have been relatively successful. One main issue in SSL is robustness of the approaches under different settings. In this paper, for the first time, we recognize the fundamental limits of SSL coming from the use of a single-supervisory signal. To address this limitation, we leverage the power of uncertainty representation to devise a robust and general standard hierarchical learning/training protocol for any SSL baseline, regardless of their assumptions and approaches. Essentially, using the information bottleneck principle, we decompose feature learning into a two-stage training procedure, each with a distinct supervision signal. This double supervision approach is captured in two key steps: 1) invariance enforcement to data augmentation, and 2) fuzzy pseudo labeling (both hard and soft annotation). This simple, yet, effective protocol which enables cross-class/cluster feature learning, is instantiated via an initial training of an ensemble of models through invariance enforcement to data augmentation as first training phase, and then assigning fuzzy labels to the original samples for the second training phase. We consider multiple alternative scenarios with double supervision and evaluate the effectiveness of our approach on recent baselines, covering four different SSL paradigms, including geometrical, contrastive, non-contrastive, and hard/soft whitening (redundancy reduction) baselines. Extensive experiments under multiple settings show that the proposed training protocol consistently improves the performance of the former baselines, independent of their respective underlying principles.
Deep Active Ensemble Sampling For Image Classification
Oct 11, 2022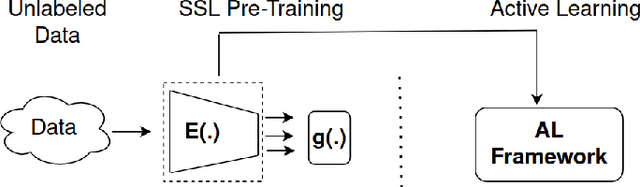
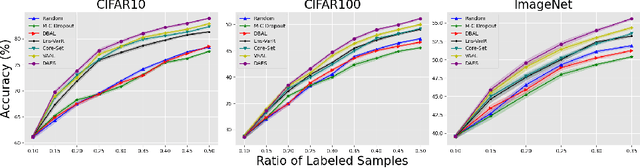
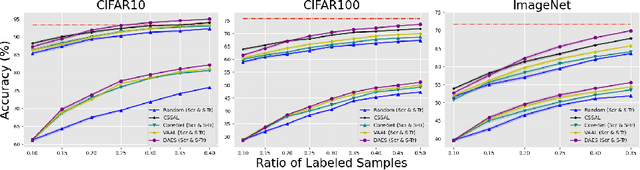
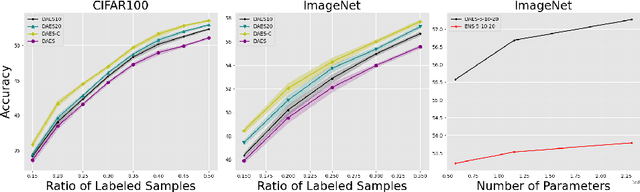
Conventional active learning (AL) frameworks aim to reduce the cost of data annotation by actively requesting the labeling for the most informative data points. However, introducing AL to data hungry deep learning algorithms has been a challenge. Some proposed approaches include uncertainty-based techniques, geometric methods, implicit combination of uncertainty-based and geometric approaches, and more recently, frameworks based on semi/self supervised techniques. In this paper, we address two specific problems in this area. The first is the need for efficient exploitation/exploration trade-off in sample selection in AL. For this, we present an innovative integration of recent progress in both uncertainty-based and geometric frameworks to enable an efficient exploration/exploitation trade-off in sample selection strategy. To this end, we build on a computationally efficient approximate of Thompson sampling with key changes as a posterior estimator for uncertainty representation. Our framework provides two advantages: (1) accurate posterior estimation, and (2) tune-able trade-off between computational overhead and higher accuracy. The second problem is the need for improved training protocols in deep AL. For this, we use ideas from semi/self supervised learning to propose a general approach that is independent of the specific AL technique being used. Taken these together, our framework shows a significant improvement over the state-of-the-art, with results that are comparable to the performance of supervised-learning under the same setting. We show empirical results of our framework, and comparative performance with the state-of-the-art on four datasets, namely, MNIST, CIFAR10, CIFAR100 and ImageNet to establish a new baseline in two different settings.