 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling-Up the Pretraining of the Earth Observation Foundation Model PhilEO to the MajorTOM Dataset
Jun 17, 2025



Today, Earth Observation (EO) satellites generate massive volumes of data, with the Copernicus Sentinel-2 constellation alone producing approximately 1.6TB per day. To fully exploit this information, it is essential to pretrain EO Foundation Models (FMs) on large unlabeled datasets, enabling efficient fine-tuning for several different downstream tasks with minimal labeled data. In this work, we present the scaling-up of our recently proposed EO Foundation Model, PhilEO Geo-Aware U-Net, on the unlabeled 23TB dataset MajorTOM, which covers the vast majority of the Earth's surface, as well as on the specialized subset FastTOM 2TB that does not include oceans and ice. We develop and study various PhilEO model variants with different numbers of parameters and architectures. Finally, we fine-tune the models on the PhilEO Bench for road density estimation, building density pixel-wise regression, and land cover semantic segmentation, and we evaluate the performance. Our results demonstrate that for all n-shots for road density regression, the PhilEO 44M MajorTOM 23TB model outperforms PhilEO Globe 0.5TB 44M. We also show that for most n-shots for road density estimation and building density regression, PhilEO 200M FastTOM outperforms all the other models. The effectiveness of both dataset and model scaling is validated using the PhilEO Bench. We also study the impact of architecture scaling, transitioning from U-Net Convolutional Neural Networks (CNN) to Vision Transformers (ViT).
Unsupervised Human Action Recognition with Skeletal Graph Laplacian and Self-Supervised Viewpoints Invariance
Apr 21, 2022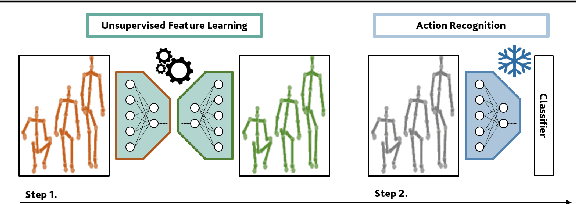
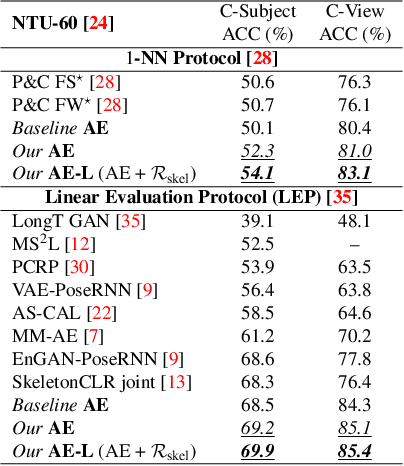
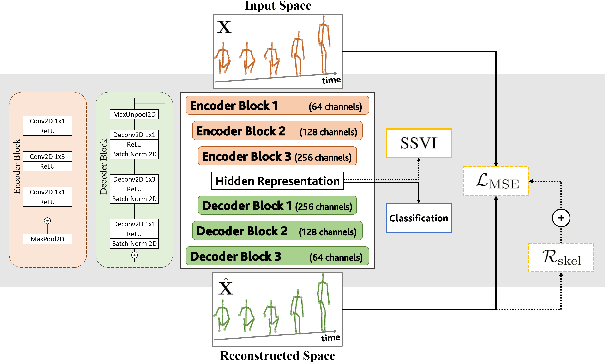

This paper presents a novel end-to-end method for the problem of skeleton-based unsupervised human action recognition. We propose a new architecture with a convolutional autoencoder that uses graph Laplacian regularization to model the skeletal geometry across the temporal dynamics of actions. Our approach is robust towards viewpoint variations by including a self-supervised gradient reverse layer that ensures generalization across camera views. The proposed method is validated on NTU-60 and NTU-120 large-scale datasets in which it outperforms all prior unsupervised skeleton-based approaches on the cross-subject, cross-view, and cross-setup protocols. Although unsupervised, our learnable representation allows our method even to surpass a few supervised skeleton-based action recognition methods. The code is available in: www.github.com/IIT-PAVIS/UHAR_Skeletal_Laplacian
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Jun 21, 2020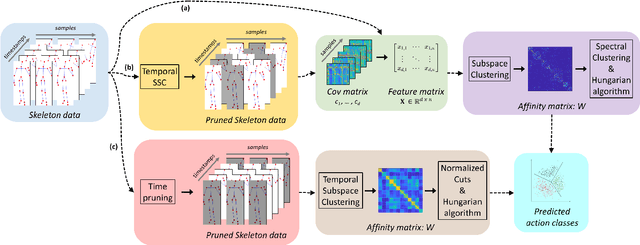
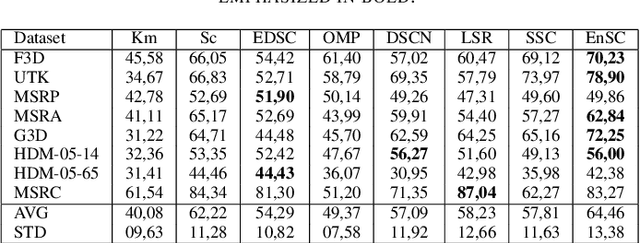
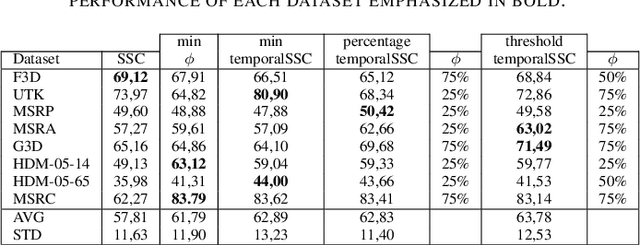
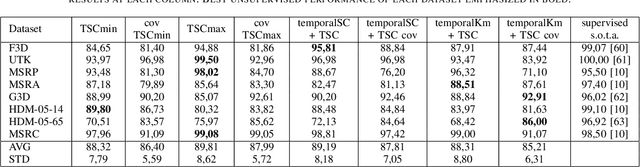
This paper tackles the problem of human action recognition, defined as classifying which action is displayed in a trimmed sequence, from skeletal data. Albeit state-of-the-art approaches designed for this application are all supervised, in this paper we pursue a more challenging direction: Solving the problem with unsupervised learning. To this end, we propose a novel subspace clustering method, which exploits covariance matrix to enhance the action's discriminability and a timestamp pruning approach that allow us to better handle the temporal dimension of the data. Through a broad experimental validation, we show that our computational pipeline surpasses existing unsupervised approaches but also can result in favorable performances as compared to supervised methods.