 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIQORN: Unified Question Answering over RDF Knowledge Graphs and Natural Language Text
Aug 19, 2021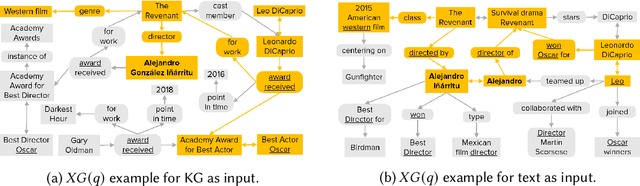
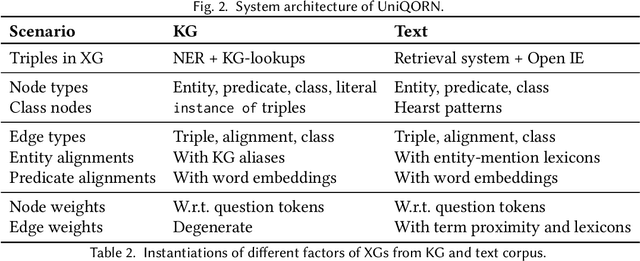
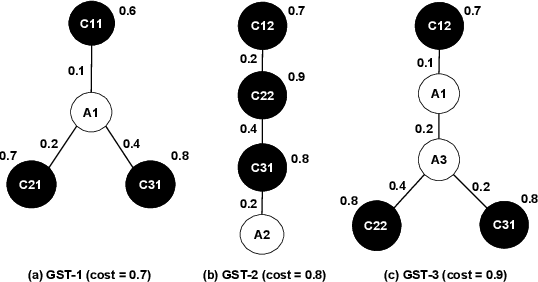
Question answering over knowledge graphs and other RDF data has been greatly advanced, with a number of good systems providing crisp answers for natural language questions or telegraphic queries. Some of these systems incorporate textual sources as additional evidence for the answering process, but cannot compute answers that are present in text alone. Conversely, systems from the IR and NLP communities have addressed QA over text, but barely utilize semantic data and knowledge. This paper presents the first QA system that can seamlessly operate over RDF datasets and text corpora, or both together, in a unified framework. Our method, called UNIQORN, builds a context graph on the fly, by retrieving question-relevant triples from the RDF data and/or the text corpus, where the latter case is handled by automatic information extraction. The resulting graph is typically rich but highly noisy. UNIQORN copes with this input by advanced graph algorithms for Group Steiner Trees, that identify the best answer candidates in the context graph. Experimental results on several benchmarks of complex questions with multiple entities and relations, show that UNIQORN, an unsupervised method with only five parameters, produces results comparable to the state-of-the-art on KGs, text corpora, and heterogeneous sources. The graph-based methodology provides user-interpretable evidence for the complete answering process.
Inside ASCENT: Exploring a Deep Commonsense Knowledge Base and its Usage in Question Answering
May 28, 2021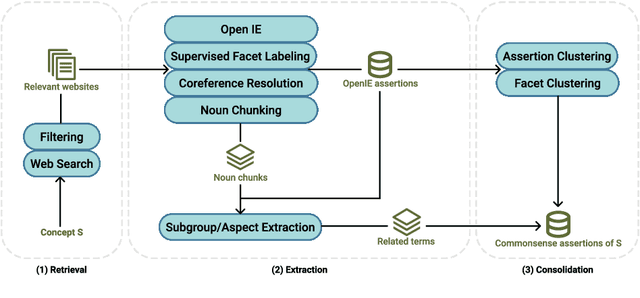

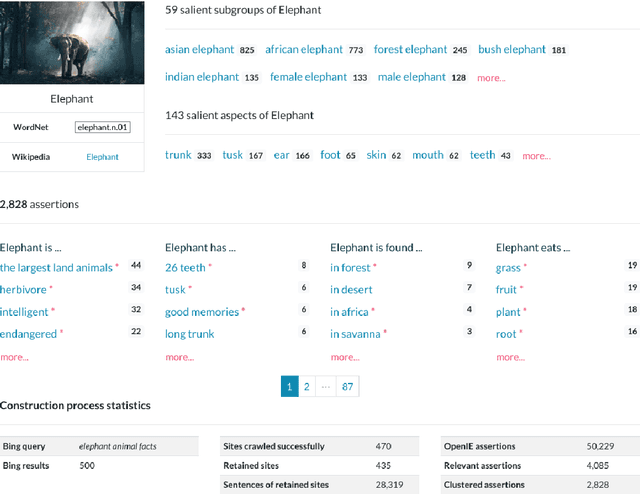
ASCENT is a fully automated methodology for extracting and consolidating commonsense assertions from web contents (Nguyen et al., WWW 2021). It advances traditional triple-based commonsense knowledge representation by capturing semantic facets like locations and purposes, and composite concepts, i.e., subgroups and related aspects of subjects. In this demo, we present a web portal that allows users to understand its construction process, explore its content, and observe its impact in the use case of question answering. The demo website and an introductory video are both available online.
* Demo website: https://ascent.mpi-inf.mpg.de; introductory video: https://youtu.be/qMkJXqu_Yd4
Reinforcement Learning from Reformulations in Conversational Question Answering over Knowledge Graphs
May 11, 2021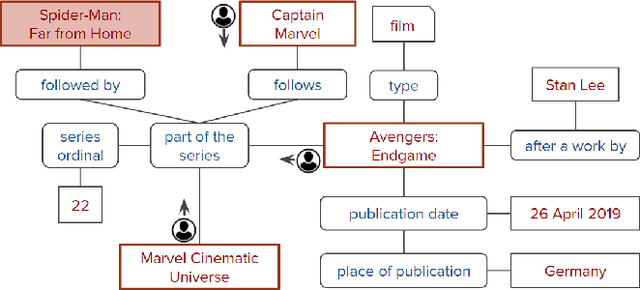

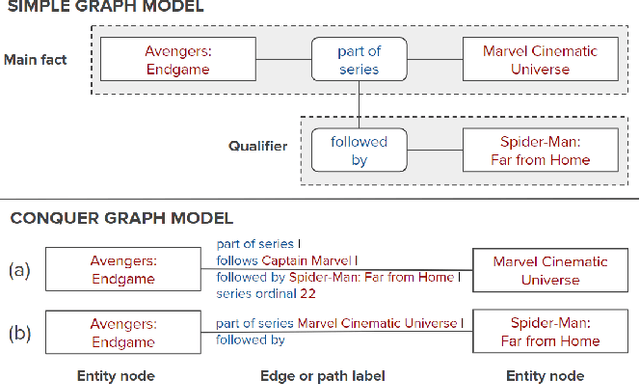

The rise of personal assistants has made conversational question answering (ConvQA) a very popular mechanism for user-system interaction. State-of-the-art methods for ConvQA over knowledge graphs (KGs) can only learn from crisp question-answer pairs found in popular benchmarks. In reality, however, such training data is hard to come by: users would rarely mark answers explicitly as correct or wrong. In this work, we take a step towards a more natural learning paradigm - from noisy and implicit feedback via question reformulations. A reformulation is likely to be triggered by an incorrect system response, whereas a new follow-up question could be a positive signal on the previous turn's answer. We present a reinforcement learning model, termed CONQUER, that can learn from a conversational stream of questions and reformulations. CONQUER models the answering process as multiple agents walking in parallel on the KG, where the walks are determined by actions sampled using a policy network. This policy network takes the question along with the conversational context as inputs and is trained via noisy rewards obtained from the reformulation likelihood. To evaluate CONQUER, we create and release ConvRef, a benchmark with about 11k natural conversations containing around 205k reformulations. Experiments show that CONQUER successfully learns to answer conversational questions from noisy reward signals, significantly improving over a state-of-the-art baseline.
ELIXIR: Learning from User Feedback on Explanations to Improve Recommender Models
Feb 22, 2021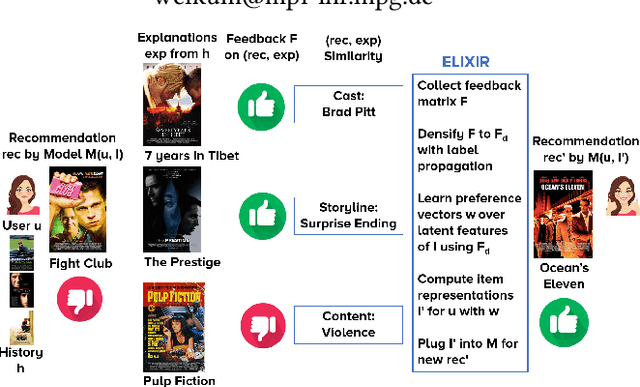

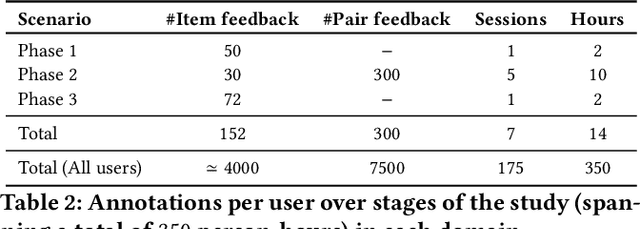
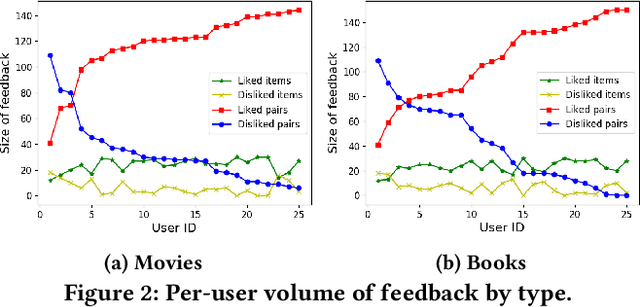
System-provided explanations for recommendations are an important component towards transparent and trustworthy AI. In state-of-the-art research, this is a one-way signal, though, to improve user acceptance. In this paper, we turn the role of explanations around and investigate how they can contribute to enhancing the quality of generated recommendations themselves. We devise a human-in-the-loop framework, called ELIXIR, where user feedback on explanations is leveraged for pairwise learning of user preferences. ELIXIR leverages feedback on pairs of recommendations and explanations to learn user-specific latent preference vectors, overcoming sparseness by label propagation with item-similarity-based neighborhoods. Our framework is instantiated using generalized graph recommendation via Random Walk with Restart. Insightful experiments with a real user study show significant improvements in movie and book recommendations over item-level feedback.
Cross-Domain Learning for Classifying Propaganda in Online Contents
Nov 22, 2020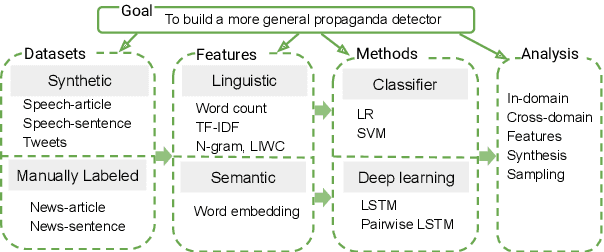
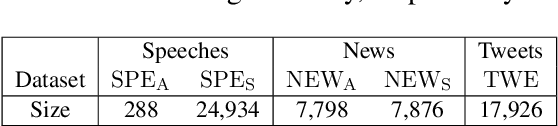
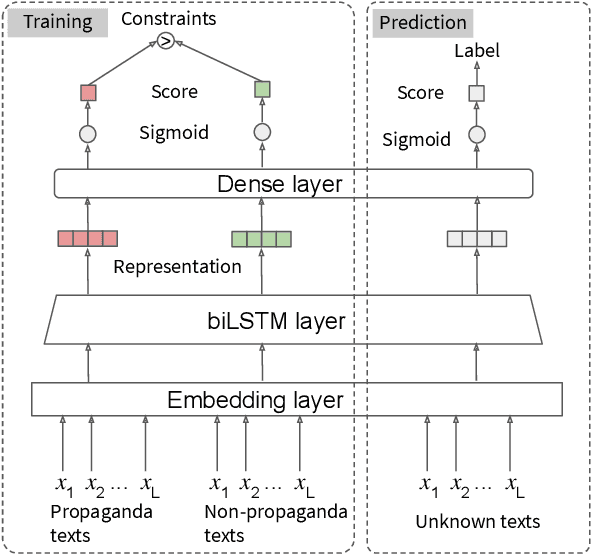

As news and social media exhibit an increasing amount of manipulative polarized content, detecting such propaganda has received attention as a new task for content analysis. Prior work has focused on supervised learning with training data from the same domain. However, as propaganda can be subtle and keeps evolving, manual identification and proper labeling are very demanding. As a consequence, training data is a major bottleneck. In this paper, we tackle this bottleneck and present an approach to leverage cross-domain learning, based on labeled documents and sentences from news and tweets, as well as political speeches with a clear difference in their degrees of being propagandistic. We devise informative features and build various classifiers for propaganda labeling, using cross-domain learning. Our experiments demonstrate the usefulness of this approach, and identify difficulties and limitations in various configurations of sources and targets for the transfer step. We further analyze the influence of various features, and characterize salient indicators of propaganda.
Advanced Semantics for Commonsense Knowledge Extraction
Nov 02, 2020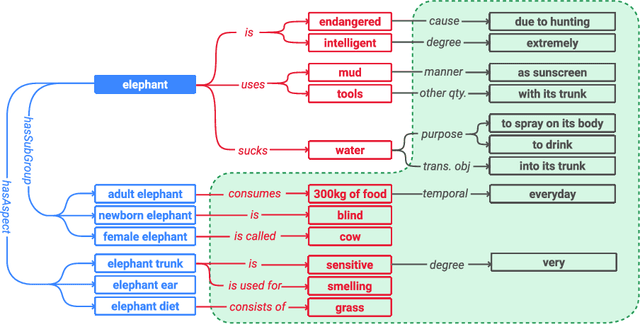

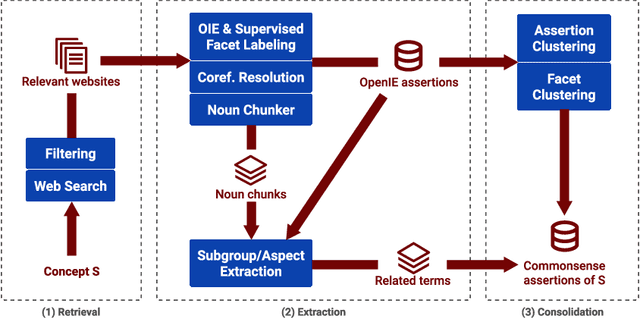
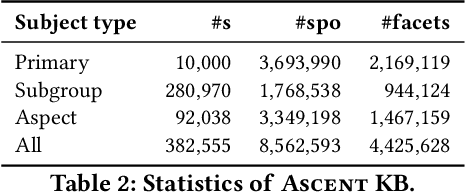
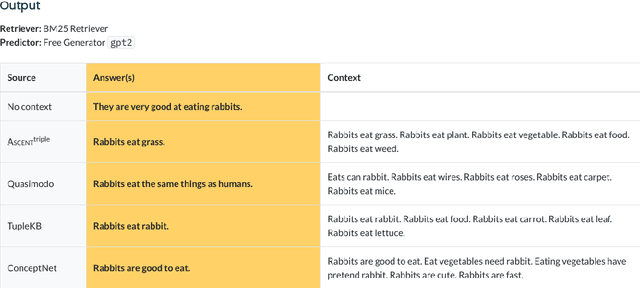
Commonsense knowledge (CSK) about concepts and their properties is useful for AI applications such as robust chatbots. Prior works like ConceptNet, TupleKB and others compiled large CSK collections, but are restricted in their expressiveness to subject-predicate-object (SPO) triples with simple concepts for S and monolithic strings for P and O. Also, these projects have either prioritized precision or recall, but hardly reconcile these complementary goals. This paper presents a methodology, called Ascent, to automatically build a large-scale knowledge base (KB) of CSK assertions, with advanced expressiveness and both better precision and recall than prior works. Ascent goes beyond triples by capturing composite concepts with subgroups and aspects, and by refining assertions with semantic facets. The latter are important to express temporal and spatial validity of assertions and further qualifiers. Ascent combines open information extraction with judicious cleaning using language models. Intrinsic evaluation shows the superior size and quality of the Ascent KB, and an extrinsic evaluation for QA-support tasks underlines the benefits of Ascent.
Machine Knowledge: Creation and Curation of Comprehensive Knowledge Bases
Sep 24, 2020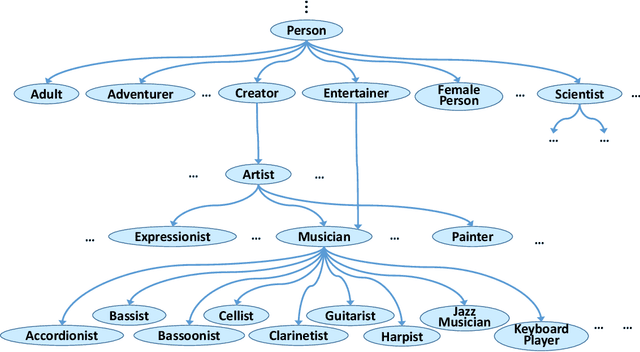
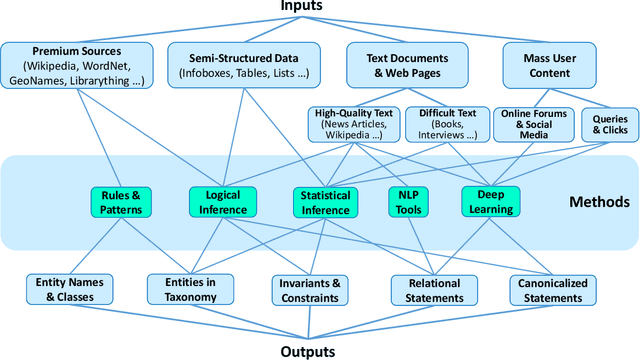
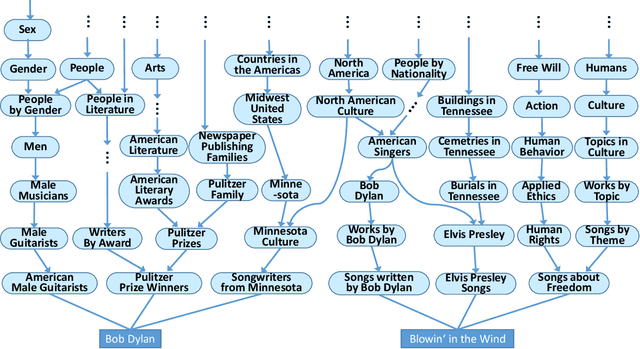
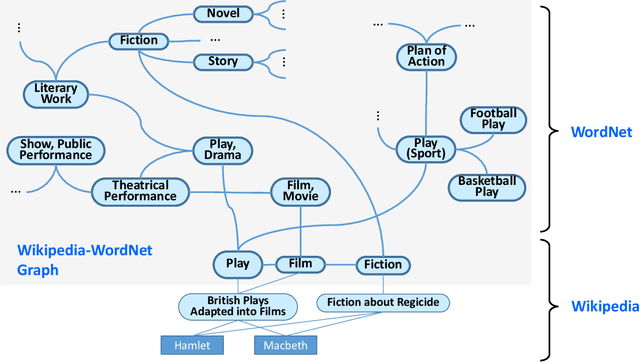
Equipping machines with comprehensive knowledge of the world's entities and their relationships has been a long-standing goal of AI. Over the last decade, large-scale knowledge bases, also known as knowledge graphs, have been automatically constructed from web contents and text sources, and have become a key asset for search engines. This machine knowledge can be harnessed to semantically interpret textual phrases in news, social media and web tables, and contributes to question answering, natural language processing and data analytics. This article surveys fundamental concepts and practical methods for creating and curating large knowledge bases. It covers models and methods for discovering and canonicalizing entities and their semantic types and organizing them into clean taxonomies. On top of this, the article discusses the automatic extraction of entity-centric properties. To support the long-term life-cycle and the quality assurance of machine knowledge, the article presents methods for constructing open schemas and for knowledge curation. Case studies on academic projects and industrial knowledge graphs complement the survey of concepts and methods.
Conversational Question Answering over Passages by Leveraging Word Proximity Networks
May 25, 2020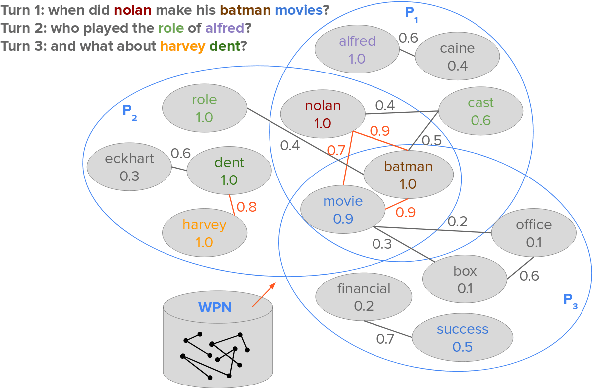
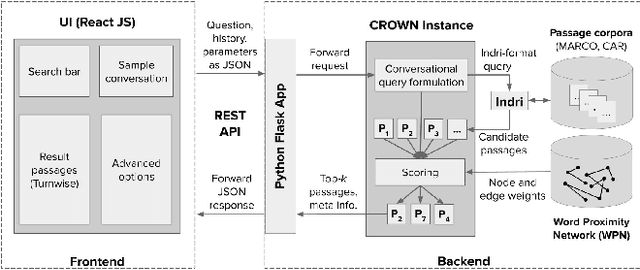
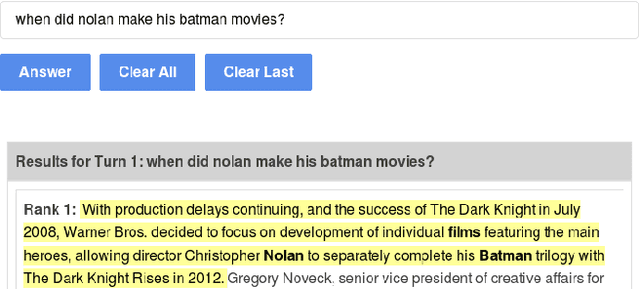

Question answering (QA) over text passages is a problem of long-standing interest in information retrieval. Recently, the conversational setting has attracted attention, where a user asks a sequence of questions to satisfy her information needs around a topic. While this setup is a natural one and similar to humans conversing with each other, it introduces two key research challenges: understanding the context left implicit by the user in follow-up questions, and dealing with ad hoc question formulations. In this work, we demonstrate CROWN (Conversational passage ranking by Reasoning Over Word Networks): an unsupervised yet effective system for conversational QA with passage responses, that supports several modes of context propagation over multiple turns. To this end, CROWN first builds a word proximity network (WPN) from large corpora to store statistically significant term co-occurrences. At answering time, passages are ranked by a combination of their similarity to the question, and coherence of query terms within: these factors are measured by reading off node and edge weights from the WPN. CROWN provides an interface that is both intuitive for end-users, and insightful for experts for reconfiguration to individual setups. CROWN was evaluated on TREC CAsT data, where it achieved above-median performance in a pool of neural methods.
CounQER: A System for Discovering and Linking Count Information in Knowledge Bases
May 07, 2020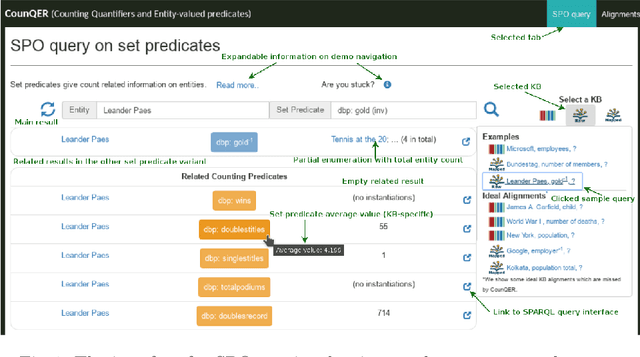
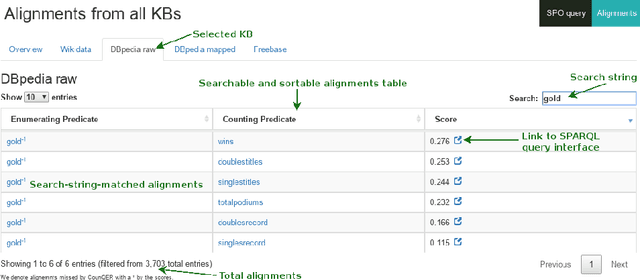
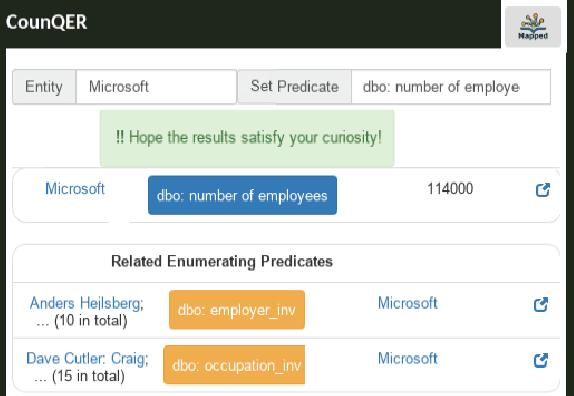
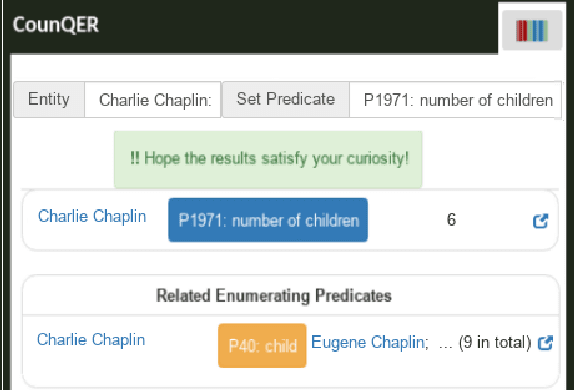
Predicate constraints of general-purpose knowledge bases (KBs) like Wikidata, DBpedia and Freebase are often limited to subproperty, domain and range constraints. In this demo we showcase CounQER, a system that illustrates the alignment of counting predicates, like staffSize, and enumerating predicates, like workInstitution^{-1} . In the demonstration session, attendees can inspect these alignments, and will learn about the importance of these alignments for KB question answering and curation. CounQER is available at https://counqer.mpi-inf.mpg.de/spo.
Negative Statements Considered Useful
Jan 20, 2020
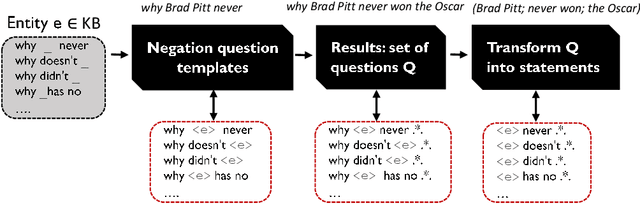


Knowledge bases (KBs), pragmatic collections of knowledge about notable entities, are an important asset in applications such as search, question answering and dialogue. Rooted in a long tradition in knowledge representation, all popular KBs only store positive information, while they abstain from taking any stance towards statements not contained in them. In this paper, we make the case for explicitly stating interesting statements which are not true. Negative statements would be important to overcome current limitations of question answering, yet due to their potential abundance, any effort towards compiling them needs a tight coupling with ranking. We introduce two approaches towards compiling negative statements. (i) In peer-based statistical inferences, we compare entities with highly related entities in order to derive potential negative statements, which we then rank using supervised and unsupervised features. (ii) In query-log-based text extraction, we use a pattern-based approach for harvesting search engine query logs. Experimental results show that both approaches hold promising and complementary potential. Along with this paper, we publish the first datasets on interesting negative information, containing over 1.1M statements for 100K popular Wikidata entities.