 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case Study and Qualitative Analysis of Simple Cross-Lingual Opinion Mining
Nov 04, 2021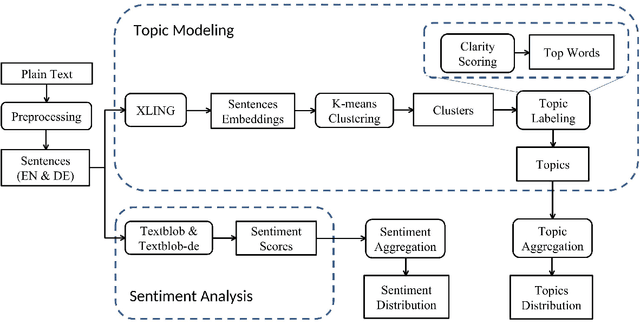
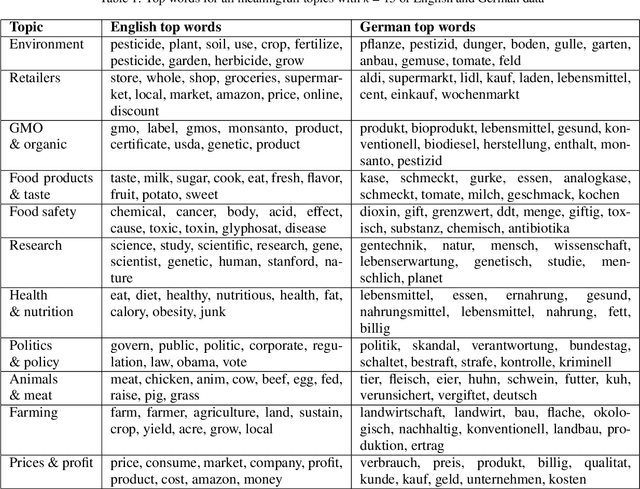
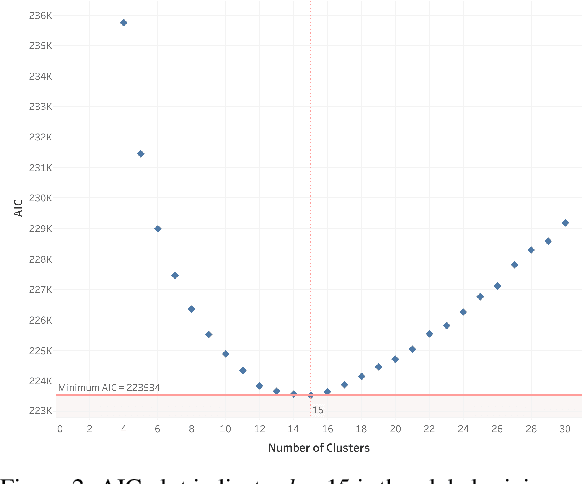
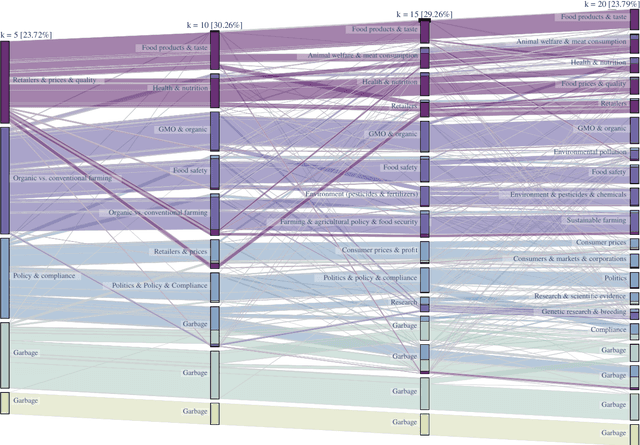
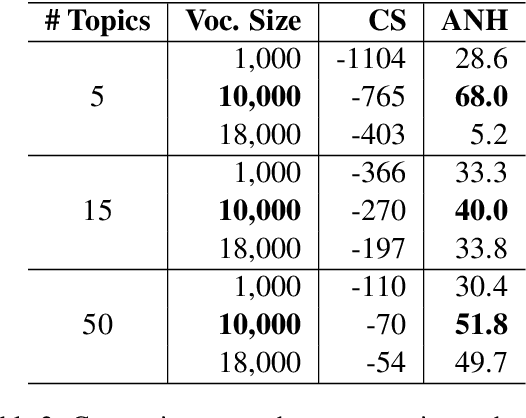
User-generated content from social media is produced in many languages, making it technically challenging to compare the discussed themes from one domain across different cultures and regions. It is relevant for domains in a globalized world, such as market research, where people from two nations and markets might have different requirements for a product. We propose a simple, modern, and effective method for building a single topic model with sentiment analysis capable of covering multiple languages simultanteously, based on a pre-trained state-of-the-art deep neural network for natural language understanding. To demonstrate its feasibility, we apply the model to newspaper articles and user comments of a specific domain, i.e., organic food products and related consumption behavior. The themes match across languages. Additionally, we obtain an high proportion of stable and domain-relevant topics, a meaningful relation between topics and their respective textual contents, and an interpretable representation for social media documents. Marketing can potentially benefit from our method, since it provides an easy-to-use means of addressing specific customer interests from different market regions around the globe. For reproducibility, we provide the code, data, and results of our study.
* 10 pages, 2 tables, 5 figures, full paper, peer-reviewed, published at KDIR/IC3k 2021 conference
End-to-End Annotator Bias Approximation on Crowdsourced Single-Label Sentiment Analysis
Nov 03, 2021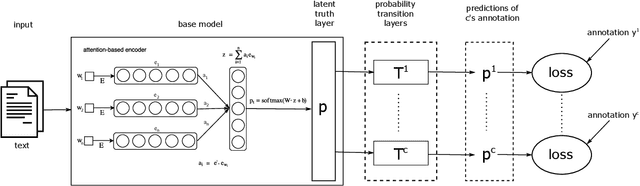
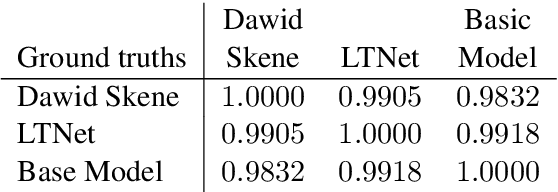
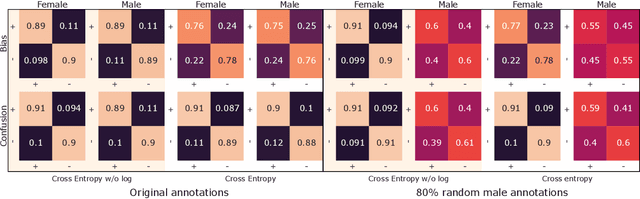
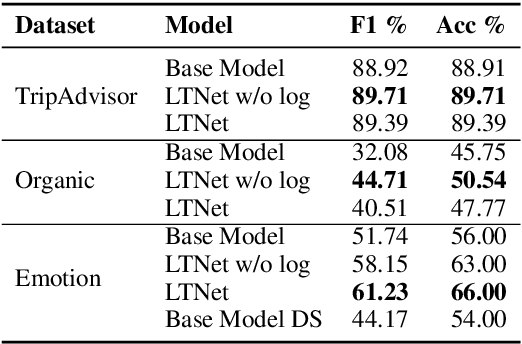
Sentiment analysis is often a crowdsourcing task prone to subjective labels given by many annotators. It is not yet fully understood how the annotation bias of each annotator can be modeled correctly with state-of-the-art methods. However, resolving annotator bias precisely and reliably is the key to understand annotators' labeling behavior and to successfully resolve corresponding individual misconceptions and wrongdoings regarding the annotation task. Our contribution is an explanation and improvement for precise neural end-to-end bias modeling and ground truth estimation, which reduces an undesired mismatch in that regard of the existing state-of-the-art. Classification experiments show that it has potential to improve accuracy in cases where each sample is annotated only by one single annotator. We provide the whole source code publicly and release an own domain-specific sentiment dataset containing 10,000 sentences discussing organic food products. These are crawled from social media and are singly labeled by 10 non-expert annotators.
* 10 pages, 2 figures, 2 tables, full conference paper, peer-reviewed
An Analysis of Programming Course Evaluations Before and After the Introduction of an Autograder
Oct 28, 2021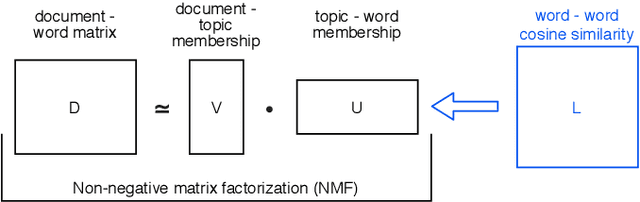
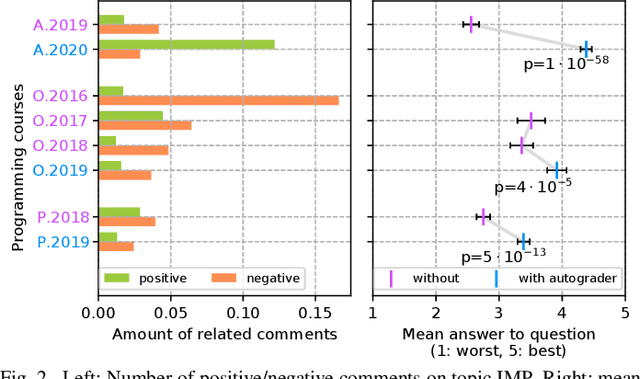
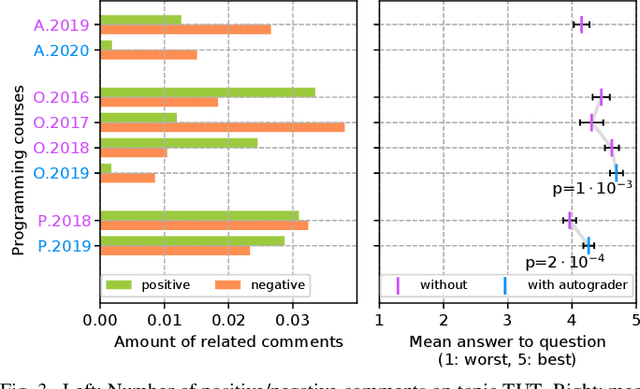
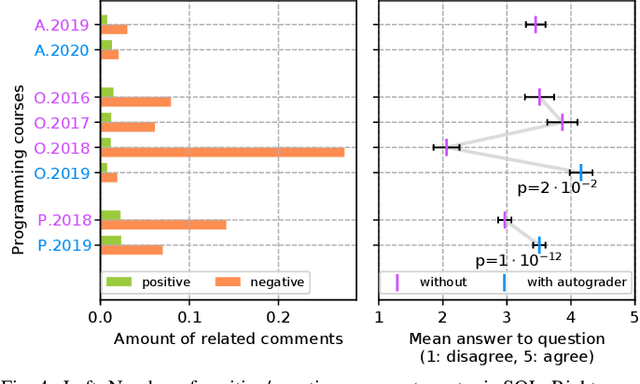
Commonly, introductory programming courses in higher education institutions have hundreds of participating students eager to learn to program. The manual effort for reviewing the submitted source code and for providing feedback can no longer be managed. Manually reviewing the submitted homework can be subjective and unfair, particularly if many tutors are responsible for grading. Different autograders can help in this situation; however, there is a lack of knowledge about how autograders can impact students' overall perception of programming classes and teaching. This is relevant for course organizers and institutions to keep their programming courses attractive while coping with increasing students. This paper studies the answers to the standardized university evaluation questionnaires of multiple large-scale foundational computer science courses which recently introduced autograding. The differences before and after this intervention are analyzed. By incorporating additional observations, we hypothesize how the autograder might have contributed to the significant changes in the data, such as, improved interactions between tutors and students, improved overall course quality, improved learning success, increased time spent, and reduced difficulty. This qualitative study aims to provide hypotheses for future research to define and conduct quantitative surveys and data analysis. The autograder technology can be validated as a teaching method to improve student satisfaction with programming courses.
* Accepted full paper article on IEEE ITHET 2021
SocialVisTUM: An Interactive Visualization Toolkit for Correlated Neural Topic Models on Social Media Opinion Mining
Oct 20, 2021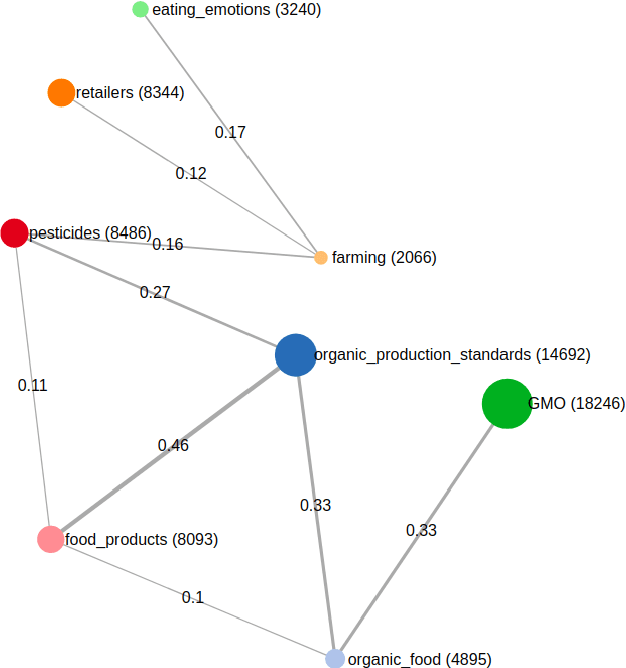

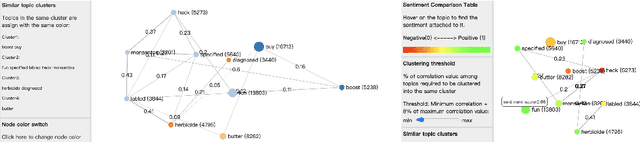
Recent research in opinion mining proposed word embedding-based topic modeling methods that provide superior coherence compared to traditional topic modeling. In this paper, we demonstrate how these methods can be used to display correlated topic models on social media texts using SocialVisTUM, our proposed interactive visualization toolkit. It displays a graph with topics as nodes and their correlations as edges. Further details are displayed interactively to support the exploration of large text collections, e.g., representative words and sentences of topics, topic and sentiment distributions, hierarchical topic clustering, and customizable, predefined topic labels. The toolkit optimizes automatically on custom data for optimal coherence. We show a working instance of the toolkit on data crawled from English social media discussions about organic food consumption. The visualization confirms findings of a qualitative consumer research study. SocialVisTUM and its training procedures are accessible online.
* Demo paper accepted for publication on RANLP 2021; 8 pages, 5 figures, 1 table
Classification of Consumer Belief Statements From Social Media
Jun 29, 2021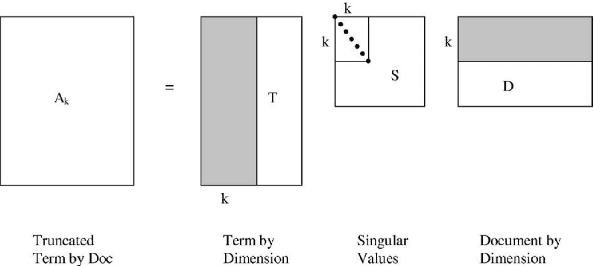
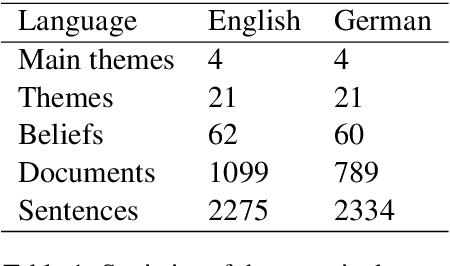
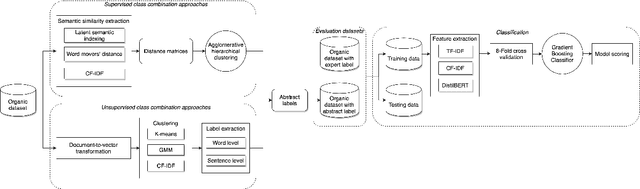

Social media offer plenty of information to perform market research in order to meet the requirements of customers. One way how this research is conducted is that a domain expert gathers and categorizes user-generated content into a complex and fine-grained class structure. In many of such cases, little data meets complex annotations. It is not yet fully understood how this can be leveraged successfully for classification. We examine the classification accuracy of expert labels when used with a) many fine-grained classes and b) few abstract classes. For scenario b) we compare abstract class labels given by the domain expert as baseline and by automatic hierarchical clustering. We compare this to another baseline where the entire class structure is given by a completely unsupervised clustering approach. By doing so, this work can serve as an example of how complex expert annotations are potentially beneficial and can be utilized in the most optimal way for opinion mining in highly specific domains. By exploring across a range of techniques and experiments, we find that automated class abstraction approaches in particular the unsupervised approach performs remarkably well against domain expert baseline on text classification tasks. This has the potential to inspire opinion mining applications in order to support market researchers in practice and to inspire fine-grained automated content analysis on a large scale.
Unsupervised Graph-based Topic Modeling from Video Transcriptions
May 04, 2021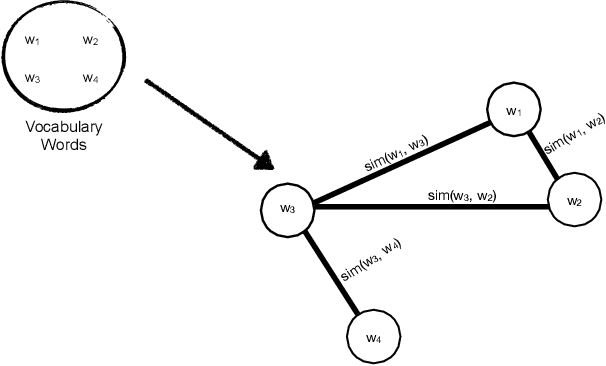



To unfold the tremendous amount of audiovisual data uploaded daily to social media platforms, effective topic modelling techniques are needed. Existing work tends to apply variants of topic models on text data sets. In this paper, we aim at developing a topic extractor on video transcriptions. The model improves coherence by exploiting neural word embeddings through a graph-based clustering method. Unlike typical topic models, this approach works without knowing the true number of topics. Experimental results on the real-life multimodal data set MuSe-CaR demonstrates that our approach extracts coherent and meaningful topics, outperforming baseline methods. Furthermore, we successfully demonstrate the generalisability of our approach on a pure text review data set.