 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASPIRE: Assistive System for Performance Evaluation in IR
Dec 20, 2024

Information Retrieval (IR) evaluation involves far more complexity than merely presenting performance measures in a table. Researchers often need to compare multiple models across various dimensions, such as the Precision-Recall trade-off and response time, to understand the reasons behind the varying performance of specific queries for different models. We introduce ASPIRE (Assistive System for Performance Evaluation in IR), a visual analytics tool designed to address these complexities by providing an extensive and user-friendly interface for in-depth analysis of IR experiments. ASPIRE supports four key aspects of IR experiment evaluation and analysis: single/multi-experiment comparisons, query-level analysis, query characteristics-performance interplay, and collection-based retrieval analysis. We showcase the functionality of ASPIRE using the TREC Clinical Trials collection. ASPIRE is an open-source toolkit available online: https://github.com/GiorgosPeikos/ASPIRE
Investigating Mixture of Experts in Dense Retrieval
Dec 16, 2024


While Dense Retrieval Models (DRMs) have advanced Information Retrieval (IR), one limitation of these neural models is their narrow generalizability and robustness. To cope with this issue, one can leverage the Mixture-of-Experts (MoE) architecture. While previous IR studies have incorporated MoE architectures within the Transformer layers of DRMs, our work investigates an architecture that integrates a single MoE block (SB-MoE) after the output of the final Transformer layer. Our empirical evaluation investigates how SB-MoE compares, in terms of retrieval effectiveness, to standard fine-tuning. In detail, we fine-tune three DRMs (TinyBERT, BERT, and Contriever) across four benchmark collections with and without adding the MoE block. Moreover, since MoE showcases performance variations with respect to its parameters (i.e., the number of experts), we conduct additional experiments to investigate this aspect further. The findings show the effectiveness of SB-MoE especially for DRMs with a low number of parameters (i.e., TinyBERT), as it consistently outperforms the fine-tuned underlying model on all four benchmarks. For DRMs with a higher number of parameters (i.e., BERT and Contriever), SB-MoE requires larger numbers of training samples to yield better retrieval performance.
Leveraging Large Language Models for Medical Information Extraction and Query Generation
Oct 31, 2024



This paper introduces a system that integrates large language models (LLMs) into the clinical trial retrieval process, enhancing the effectiveness of matching patients with eligible trials while maintaining information privacy and allowing expert oversight. We evaluate six LLMs for query generation, focusing on open-source and relatively small models that require minimal computational resources. Our evaluation includes two closed-source and four open-source models, with one specifically trained in the medical field and five general-purpose models. We compare the retrieval effectiveness achieved by LLM-generated queries against those created by medical experts and state-of-the-art methods from the literature. Our findings indicate that the evaluated models reach retrieval effectiveness on par with or greater than expert-created queries. The LLMs consistently outperform standard baselines and other approaches in the literature. The best performing LLMs exhibit fast response times, ranging from 1.7 to 8 seconds, and generate a manageable number of query terms (15-63 on average), making them suitable for practical implementation. Our overall findings suggest that leveraging small, open-source LLMs for clinical trials retrieval can balance performance, computational efficiency, and real-world applicability in medical settings.
Utilizing ChatGPT to Enhance Clinical Trial Enrollment
Jun 03, 2023Clinical trials are a critical component of evaluating the effectiveness of new medical interventions and driving advancements in medical research. Therefore, timely enrollment of patients is crucial to prevent delays or premature termination of trials. In this context, Electronic Health Records (EHRs) have emerged as a valuable tool for identifying and enrolling eligible participants. In this study, we propose an automated approach that leverages ChatGPT, a large language model, to extract patient-related information from unstructured clinical notes and generate search queries for retrieving potentially eligible clinical trials. Our empirical evaluation, conducted on two benchmark retrieval collections, shows improved retrieval performance compared to existing approaches when several general-purposed and task-specific prompts are used. Notably, ChatGPT-generated queries also outperform human-generated queries in terms of retrieval performance. These findings highlight the potential use of ChatGPT to enhance clinical trial enrollment while ensuring the quality of medical service and minimizing direct risks to patients.
UNIMIB at TREC 2021 Clinical Trials Track
Jul 27, 2022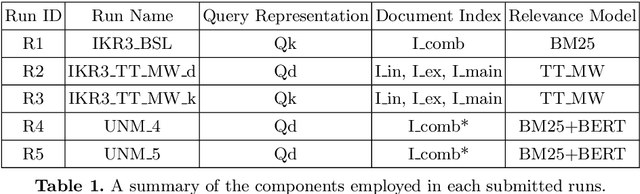
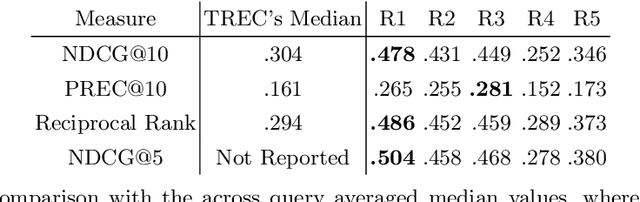
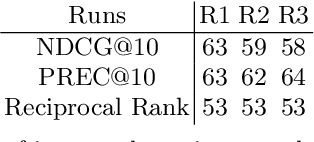
This contribution summarizes the participation of the UNIMIB team to the TREC 2021 Clinical Trials Track. We have investigated the effect of different query representations combined with several retrieval models on the retrieval performance. First, we have implemented a neural re-ranking approach to study the effectiveness of dense text representations. Additionally, we have investigated the effectiveness of a novel decision-theoretic model for relevance estimation. Finally, both of the above relevance models have been compared with standard retrieval approaches. In particular, we combined a keyword extraction method with a standard retrieval process based on the BM25 model and a decision-theoretic relevance model that exploits the characteristics of this particular search task. The obtained results show that the proposed keyword extraction method improves 84% of the queries over the TREC's median NDCG@10 measure when combined with either traditional or decision-theoretic relevance models. Moreover, regarding RPEC@10, the employed decision-theoretic model improves 85% of the queries over the reported TREC's median value.
LeiBi@COLIEE 2022: Aggregating Tuned Lexical Models with a Cluster-driven BERT-based Model for Case Law Retrieval
May 26, 2022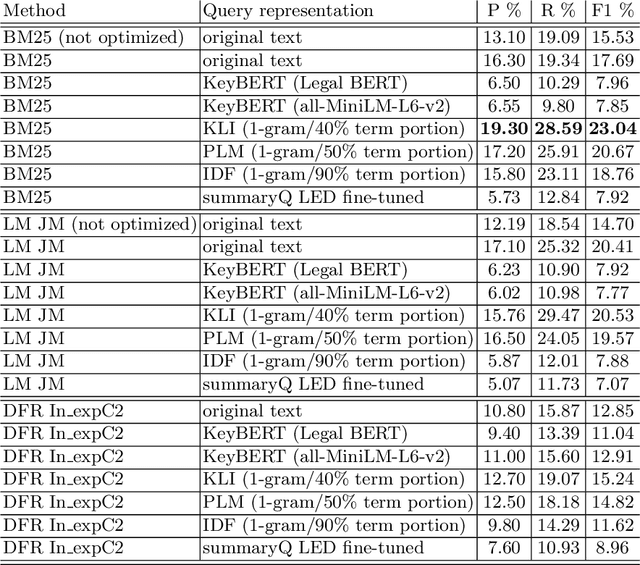
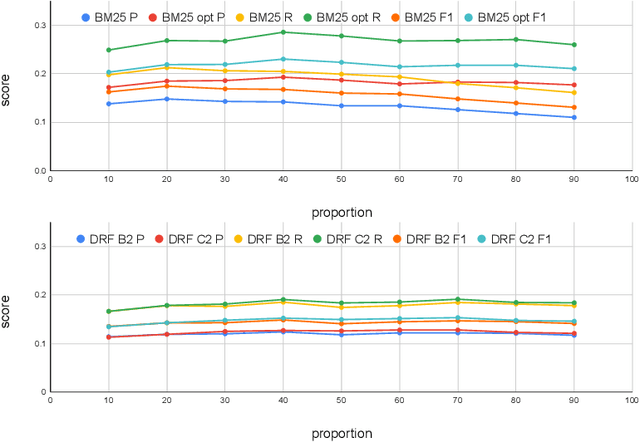


This paper summarizes our approaches submitted to the case law retrieval task in the Competition on Legal Information Extraction/Entailment (COLIEE) 2022. Our methodology consists of four steps; in detail, given a legal case as a query, we reformulate it by extracting various meaningful sentences or n-grams. Then, we utilize the pre-processed query case to retrieve an initial set of possible relevant legal cases, which we further re-rank. Lastly, we aggregate the relevance scores obtained by the first stage and the re-ranking models to improve retrieval effectiveness. In each step of our methodology, we explore various well-known and novel methods. In particular, to reformulate the query cases aiming to make them shorter, we extract unigrams using three different statistical methods: KLI, PLM, IDF-r, as well as models that leverage embeddings (e.g., KeyBERT). Moreover, we investigate if automatic summarization using Longformer-Encoder-Decoder (LED) can produce an effective query representation for this retrieval task. Furthermore, we propose a novel re-ranking cluster-driven approach, which leverages Sentence-BERT models that are pre-tuned on large amounts of data for embedding sentences from query and candidate documents. Finally, we employ a linear aggregation method to combine the relevance scores obtained by traditional IR models and neural-based models, aiming to incorporate the semantic understanding of neural models and the statistically measured topical relevance. We show that aggregating these relevance scores can improve the overall retrieval effectiveness.