 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectricity Market Forecasting via Low-Rank Multi-Kernel Learning
Mar 05, 2014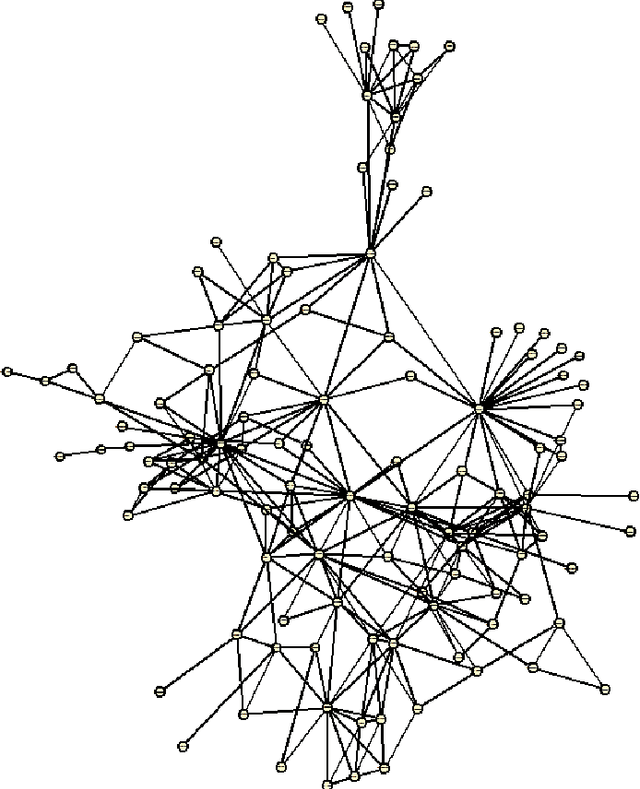
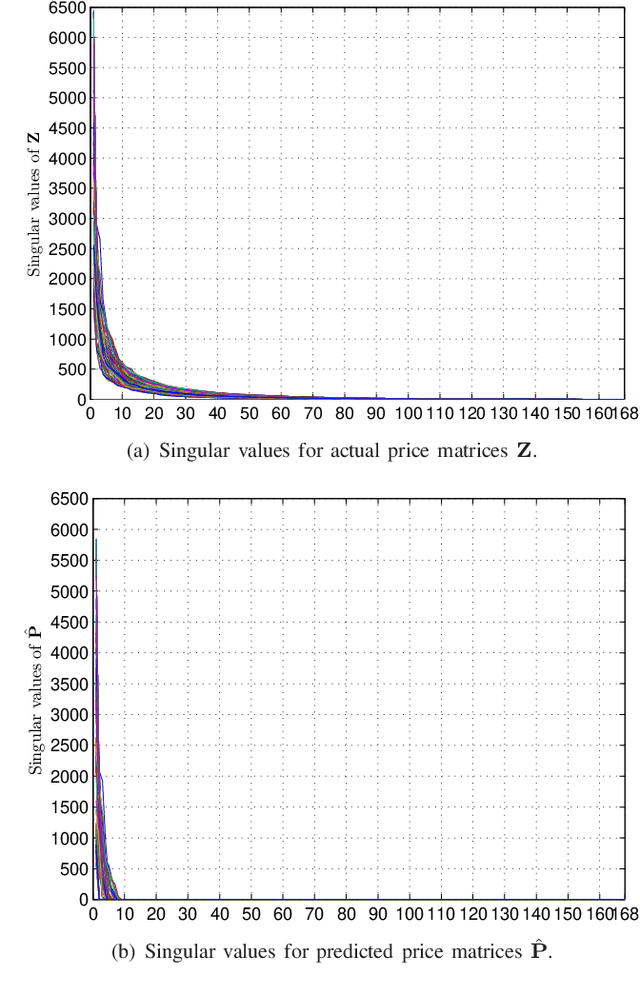
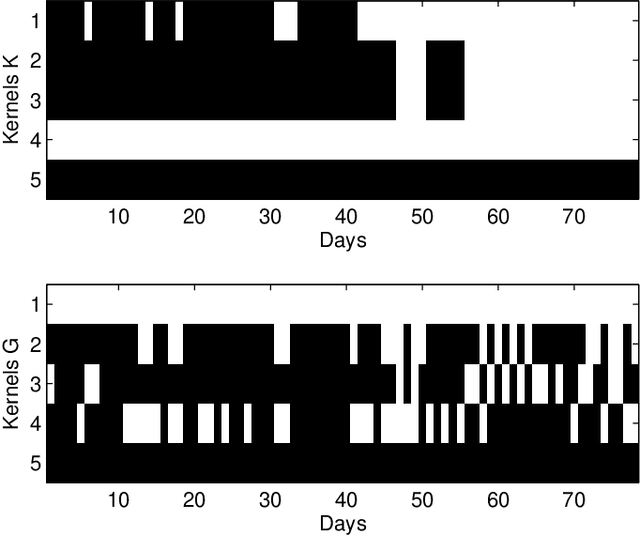
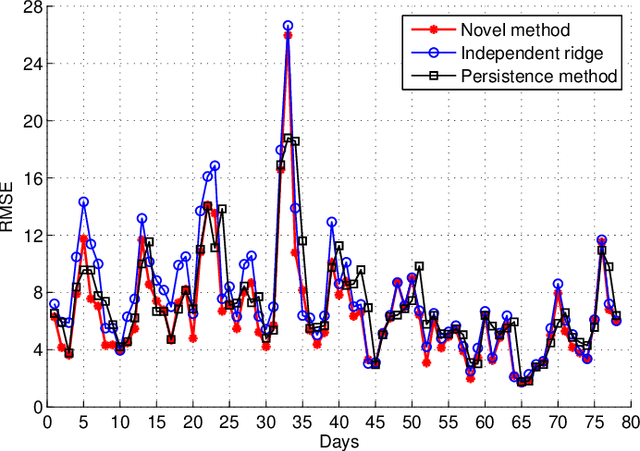
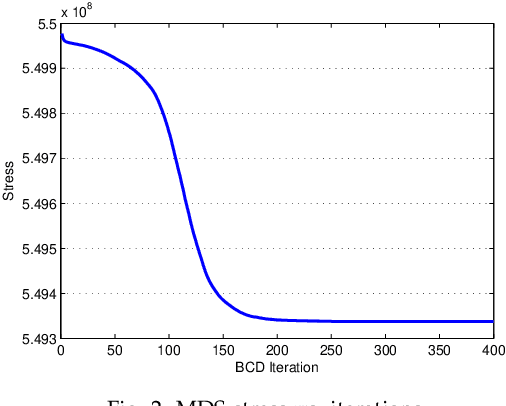
The smart grid vision entails advanced information technology and data analytics to enhance the efficiency, sustainability, and economics of the power grid infrastructure. Aligned to this end, modern statistical learning tools are leveraged here for electricity market inference. Day-ahead price forecasting is cast as a low-rank kernel learning problem. Uniquely exploiting the market clearing process, congestion patterns are modeled as rank-one components in the matrix of spatio-temporally varying prices. Through a novel nuclear norm-based regularization, kernels across pricing nodes and hours can be systematically selected. Even though market-wide forecasting is beneficial from a learning perspective, it involves processing high-dimensional market data. The latter becomes possible after devising a block-coordinate descent algorithm for solving the non-convex optimization problem involved. The algorithm utilizes results from block-sparse vector recovery and is guaranteed to converge to a stationary point. Numerical tests on real data from the Midwest ISO (MISO) market corroborate the prediction accuracy, computational efficiency, and the interpretative merits of the developed approach over existing alternatives.
Grid Topology Identification using Electricity Prices
Feb 14, 2014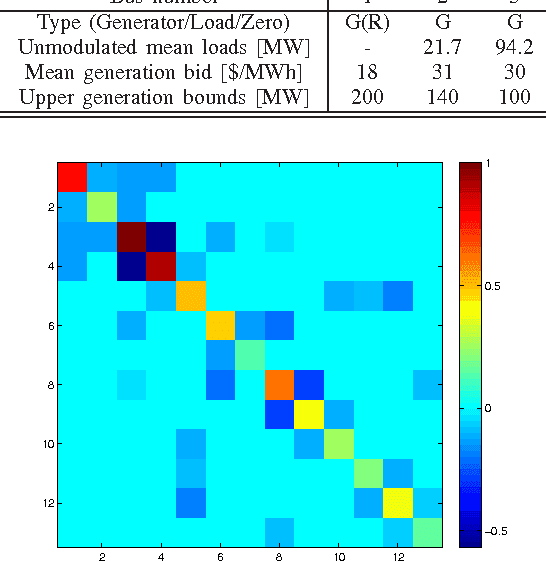
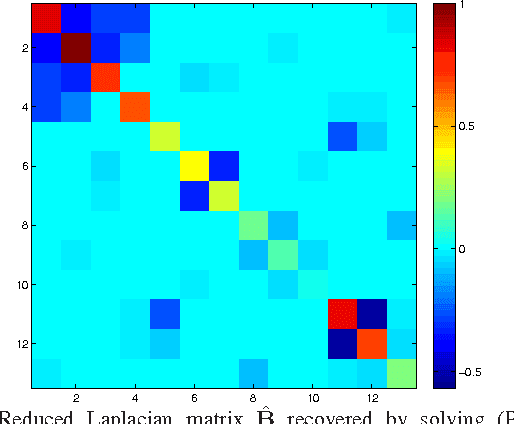

The potential of recovering the topology of a grid using solely publicly available market data is explored here. In contemporary whole-sale electricity markets, real-time prices are typically determined by solving the network-constrained economic dispatch problem. Under a linear DC model, locational marginal prices (LMPs) correspond to the Lagrange multipliers of the linear program involved. The interesting observation here is that the matrix of spatiotemporally varying LMPs exhibits the following property: Once premultiplied by the weighted grid Laplacian, it yields a low-rank and sparse matrix. Leveraging this rich structure, a regularized maximum likelihood estimator (MLE) is developed to recover the grid Laplacian from the LMPs. The convex optimization problem formulated includes low rank- and sparsity-promoting regularizers, and it is solved using a scalable algorithm. Numerical tests on prices generated for the IEEE 14-bus benchmark provide encouraging topology recovery results.
Embedding Graphs under Centrality Constraints for Network Visualization
Jan 17, 2014
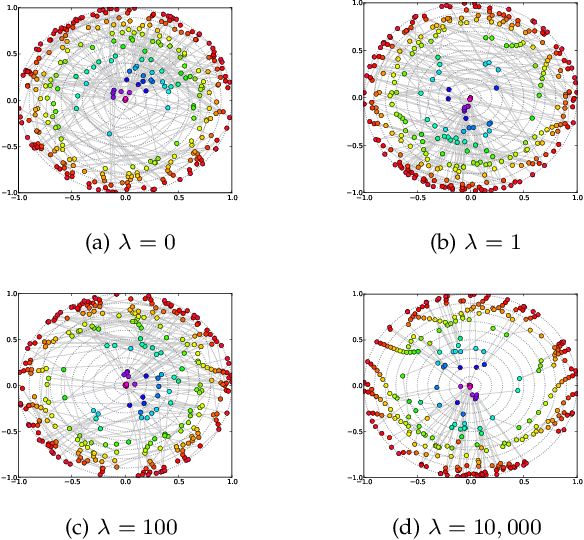
Visual rendering of graphs is a key task in the mapping of complex network data. Although most graph drawing algorithms emphasize aesthetic appeal, certain applications such as travel-time maps place more importance on visualization of structural network properties. The present paper advocates two graph embedding approaches with centrality considerations to comply with node hierarchy. The problem is formulated first as one of constrained multi-dimensional scaling (MDS), and it is solved via block coordinate descent iterations with successive approximations and guaranteed convergence to a KKT point. In addition, a regularization term enforcing graph smoothness is incorporated with the goal of reducing edge crossings. A second approach leverages the locally-linear embedding (LLE) algorithm which assumes that the graph encodes data sampled from a low-dimensional manifold. Closed-form solutions to the resulting centrality-constrained optimization problems are determined yielding meaningful embeddings. Experimental results demonstrate the efficacy of both approaches, especially for visualizing large networks on the order of thousands of nodes.
Nonparametric Basis Pursuit via Sparse Kernel-based Learning
Feb 21, 2013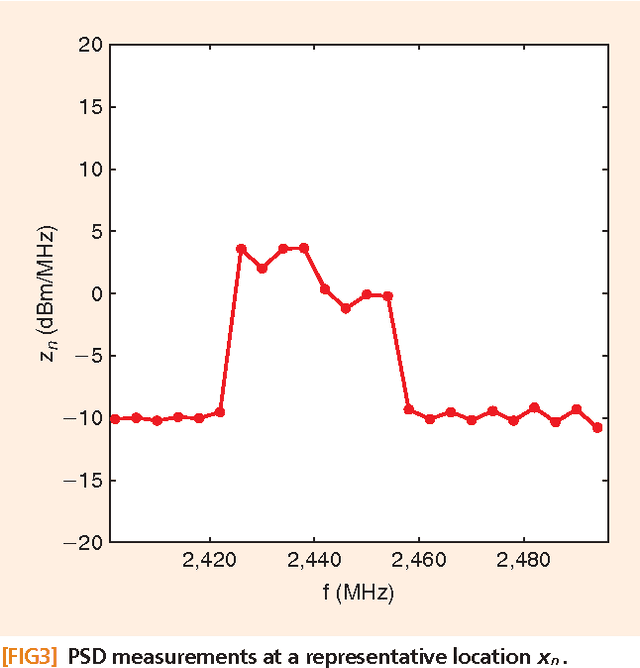
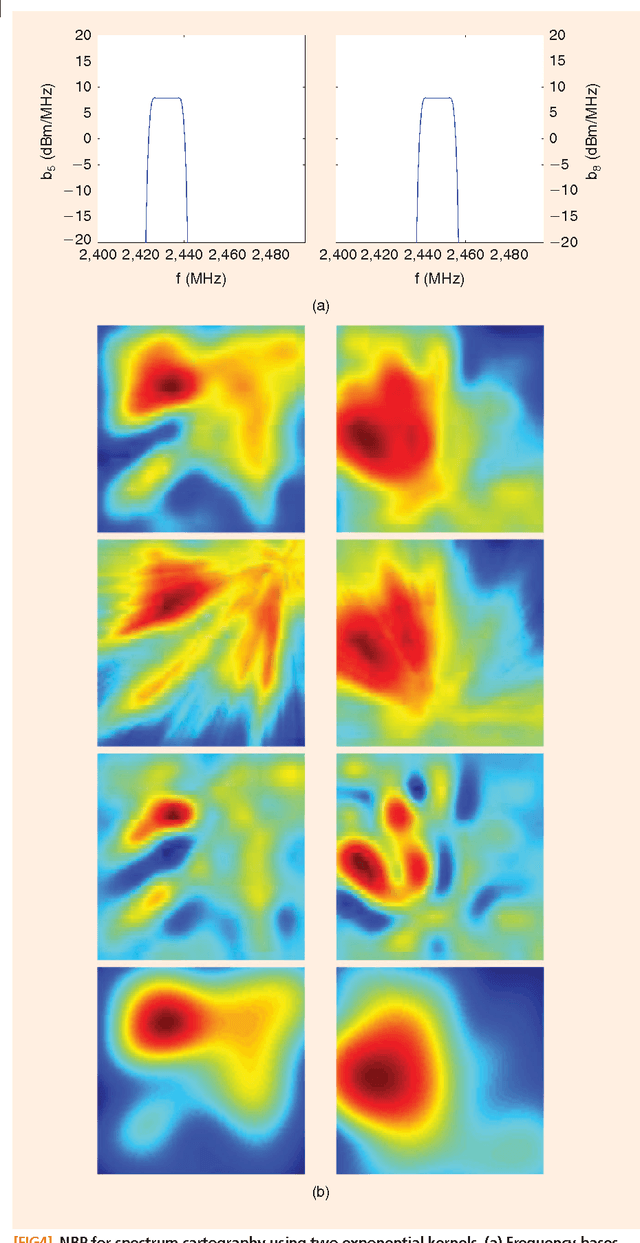
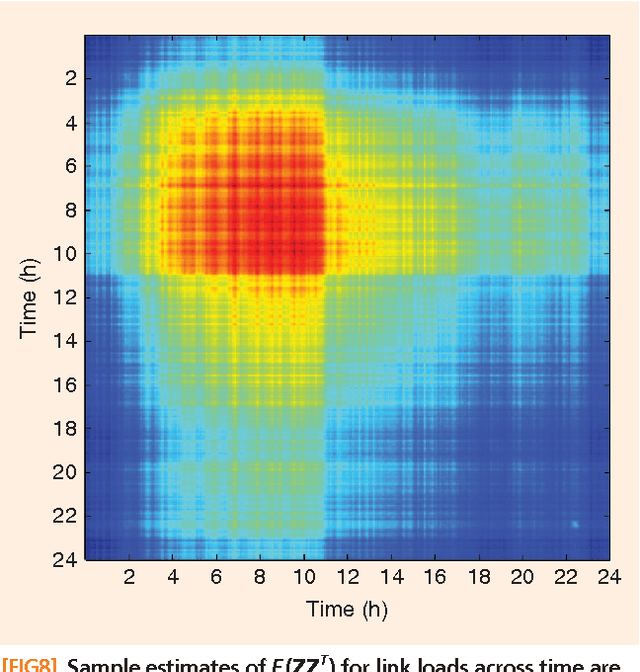
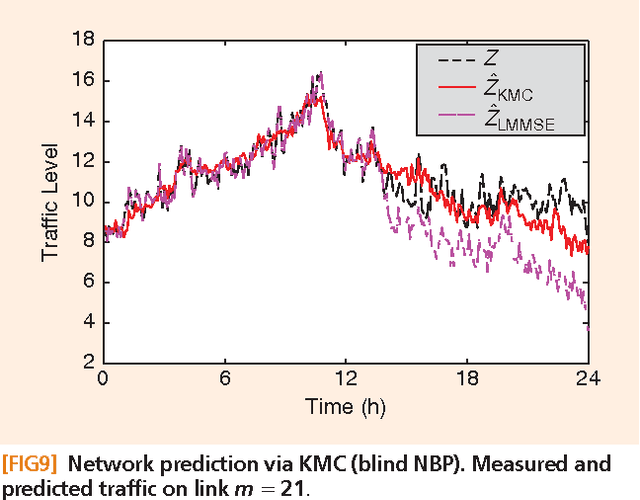
Signal processing tasks as fundamental as sampling, reconstruction, minimum mean-square error interpolation and prediction can be viewed under the prism of reproducing kernel Hilbert spaces. Endowing this vantage point with contemporary advances in sparsity-aware modeling and processing, promotes the nonparametric basis pursuit advocated in this paper as the overarching framework for the confluence of kernel-based learning (KBL) approaches leveraging sparse linear regression, nuclear-norm regularization, and dictionary learning. The novel sparse KBL toolbox goes beyond translating sparse parametric approaches to their nonparametric counterparts, to incorporate new possibilities such as multi-kernel selection and matrix smoothing. The impact of sparse KBL to signal processing applications is illustrated through test cases from cognitive radio sensing, microarray data imputation, and network traffic prediction.
Centrality-constrained graph embedding
Feb 04, 2013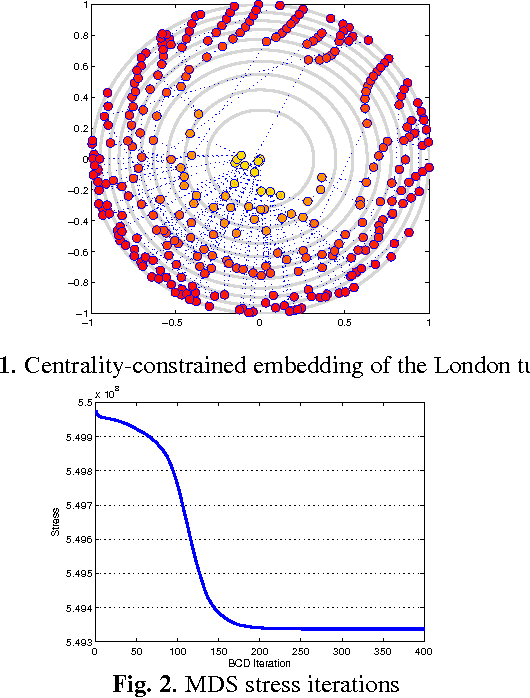
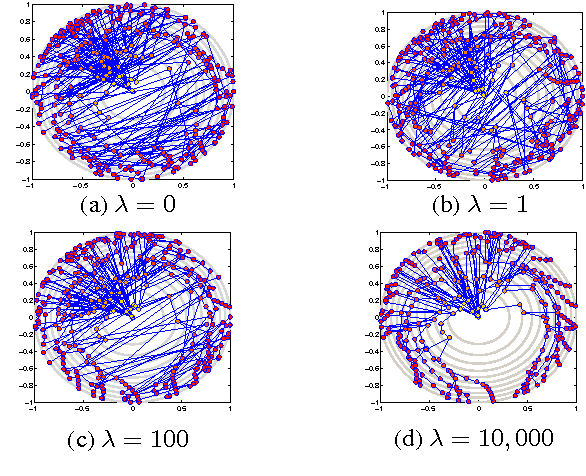
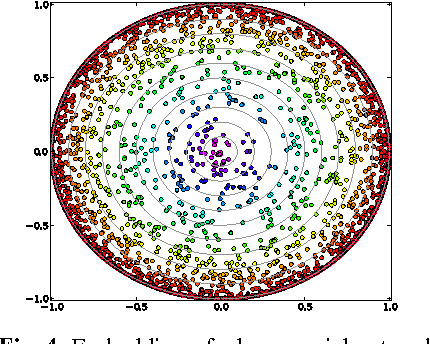
Visual rendering of graphs is a key task in the mapping of complex network data. Although most graph drawing algorithms emphasize aesthetic appeal, certain applications such as travel-time maps place more importance on visualization of structural network properties. The present paper advocates a graph embedding approach with centrality considerations to comply with node hierarchy. The problem is formulated as one of constrained multi-dimensional scaling (MDS), and it is solved via block coordinate descent iterations with successive approximations and guaranteed convergence to a KKT point. In addition, a regularization term enforcing graph smoothness is incorporated with the goal of reducing edge crossings. Experimental results demonstrate that the algorithm converges, and can be used to efficiently embed large graphs on the order of thousands of nodes.
Rank regularization and Bayesian inference for tensor completion and extrapolation
Jan 31, 2013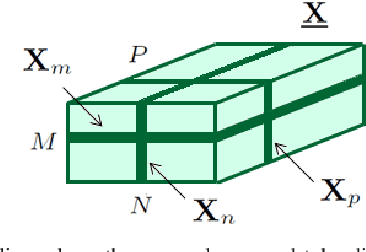
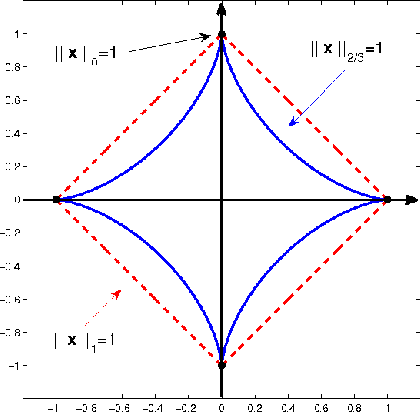
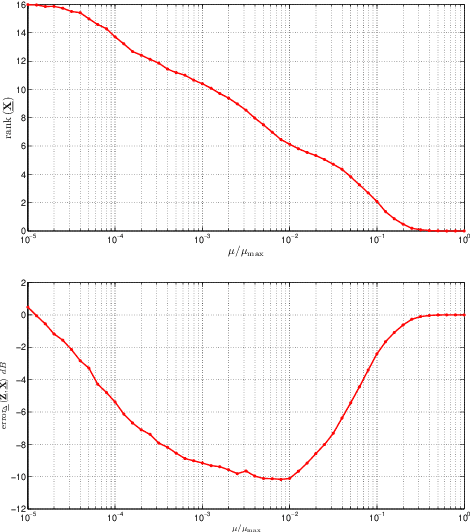
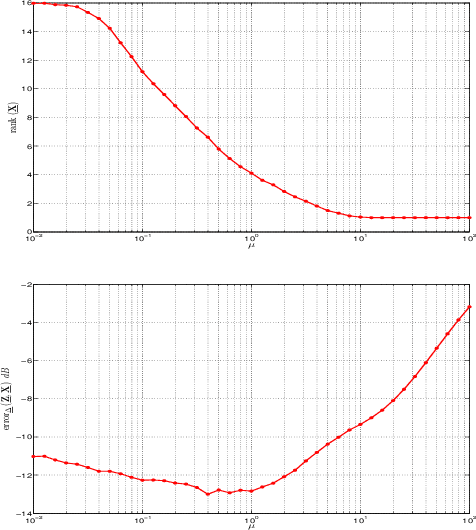
A novel regularizer of the PARAFAC decomposition factors capturing the tensor's rank is proposed in this paper, as the key enabler for completion of three-way data arrays with missing entries. Set in a Bayesian framework, the tensor completion method incorporates prior information to enhance its smoothing and prediction capabilities. This probabilistic approach can naturally accommodate general models for the data distribution, lending itself to various fitting criteria that yield optimum estimates in the maximum-a-posteriori sense. In particular, two algorithms are devised for Gaussian- and Poisson-distributed data, that minimize the rank-regularized least-squares error and Kullback-Leibler divergence, respectively. The proposed technique is able to recover the "ground-truth'' tensor rank when tested on synthetic data, and to complete brain imaging and yeast gene expression datasets with 50% and 15% of missing entries respectively, resulting in recovery errors at -10dB and -15dB.
Distributed Robust Power System State Estimation
Jun 30, 2012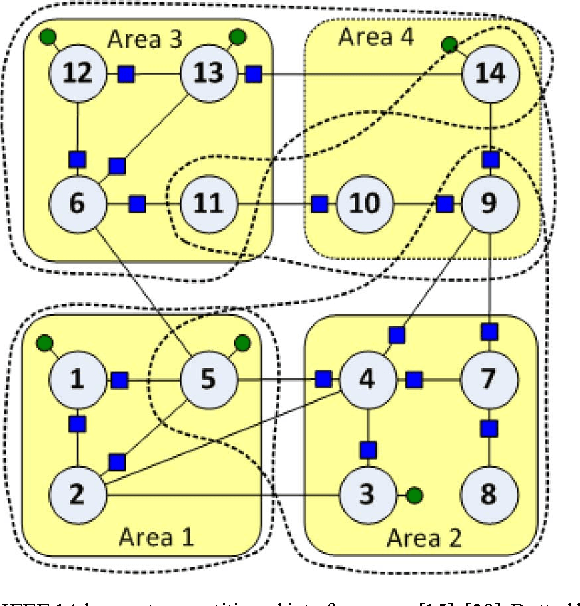
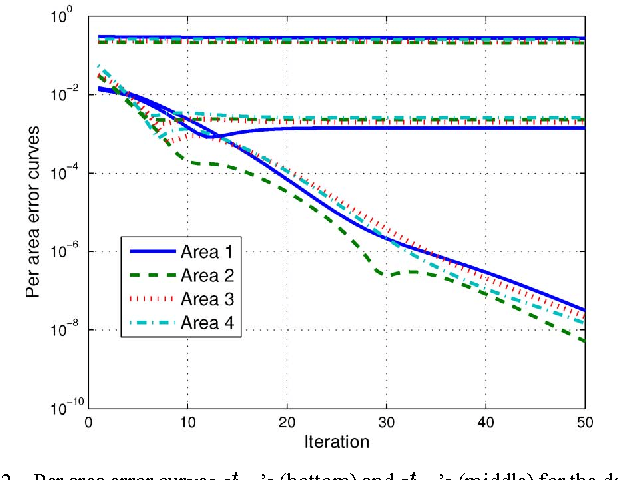
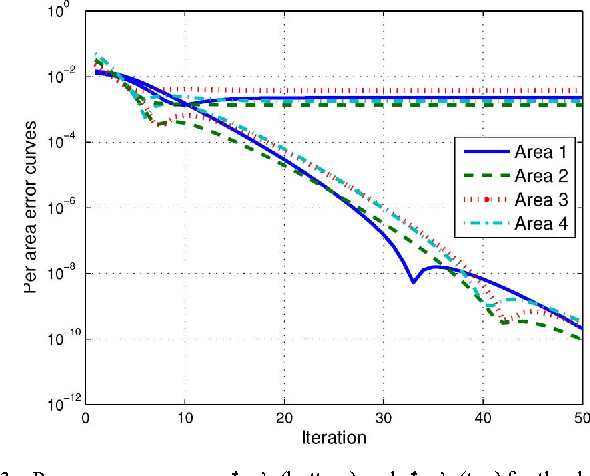
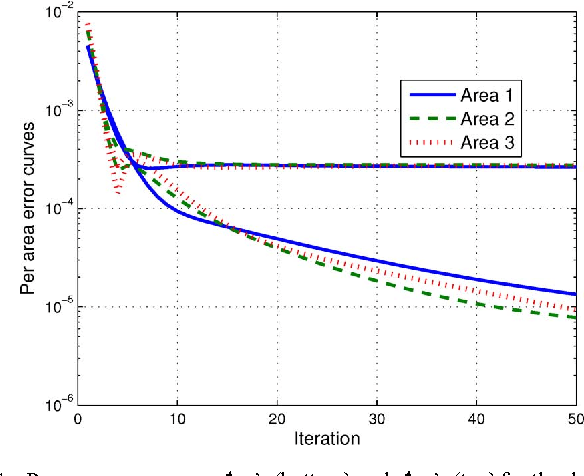
Deregulation of energy markets, penetration of renewables, advanced metering capabilities, and the urge for situational awareness, all call for system-wide power system state estimation (PSSE). Implementing a centralized estimator though is practically infeasible due to the complexity scale of an interconnection, the communication bottleneck in real-time monitoring, regional disclosure policies, and reliability issues. In this context, distributed PSSE methods are treated here under a unified and systematic framework. A novel algorithm is developed based on the alternating direction method of multipliers. It leverages existing PSSE solvers, respects privacy policies, exhibits low communication load, and its convergence to the centralized estimates is guaranteed even in the absence of local observability. Beyond the conventional least-squares based PSSE, the decentralized framework accommodates a robust state estimator. By exploiting interesting links to the compressive sampling advances, the latter jointly estimates the state and identifies corrupted measurements. The novel algorithms are numerically evaluated using the IEEE 14-, 118-bus, and a 4,200-bus benchmarks. Simulations demonstrate that the attainable accuracy can be reached within a few inter-area exchanges, while largest residual tests are outperformed.
Recovery of Low-Rank Plus Compressed Sparse Matrices with Application to Unveiling Traffic Anomalies
Apr 30, 2012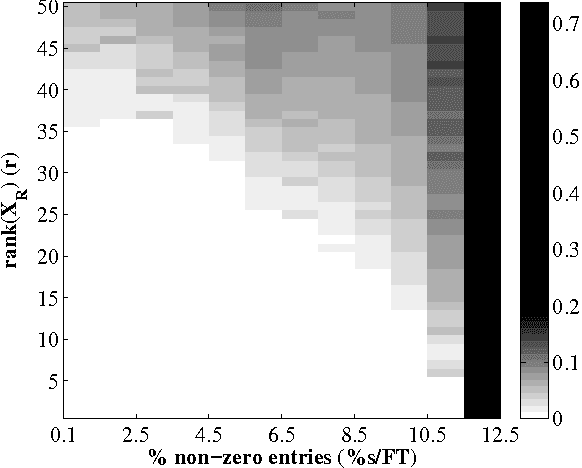
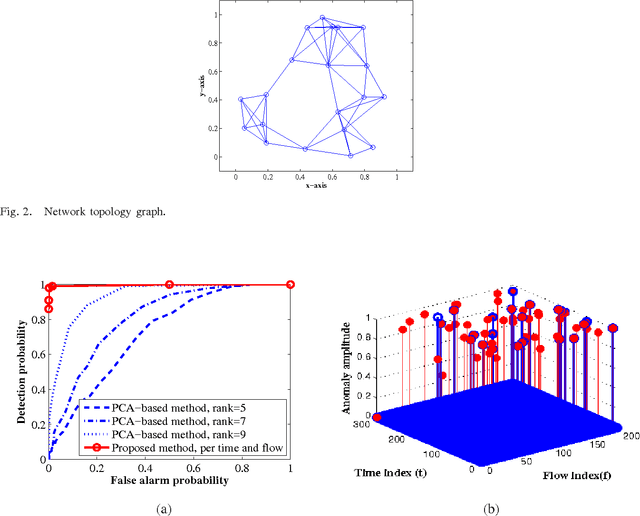
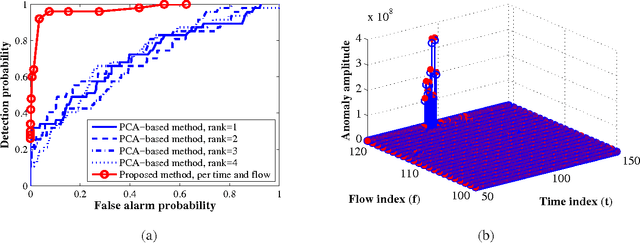
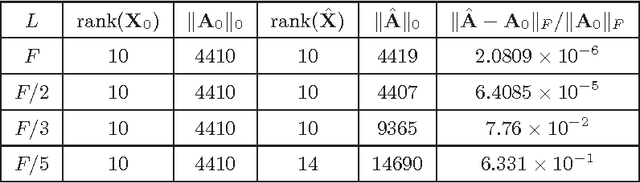
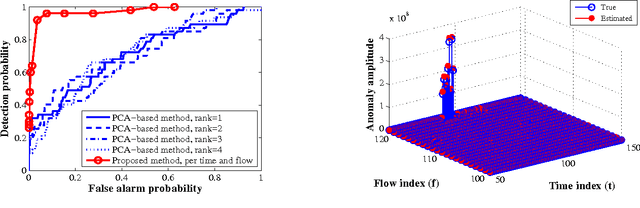
Given the superposition of a low-rank matrix plus the product of a known fat compression matrix times a sparse matrix, the goal of this paper is to establish deterministic conditions under which exact recovery of the low-rank and sparse components becomes possible. This fundamental identifiability issue arises with traffic anomaly detection in backbone networks, and subsumes compressed sensing as well as the timely low-rank plus sparse matrix recovery tasks encountered in matrix decomposition problems. Leveraging the ability of $\ell_1$- and nuclear norms to recover sparse and low-rank matrices, a convex program is formulated to estimate the unknowns. Analysis and simulations confirm that the said convex program can recover the unknowns for sufficiently low-rank and sparse enough components, along with a compression matrix possessing an isometry property when restricted to operate on sparse vectors. When the low-rank, sparse, and compression matrices are drawn from certain random ensembles, it is established that exact recovery is possible with high probability. First-order algorithms are developed to solve the nonsmooth convex optimization problem with provable iteration complexity guarantees. Insightful tests with synthetic and real network data corroborate the effectiveness of the novel approach in unveiling traffic anomalies across flows and time, and its ability to outperform existing alternatives.
In-network Sparsity-regularized Rank Minimization: Algorithms and Applications
Mar 07, 2012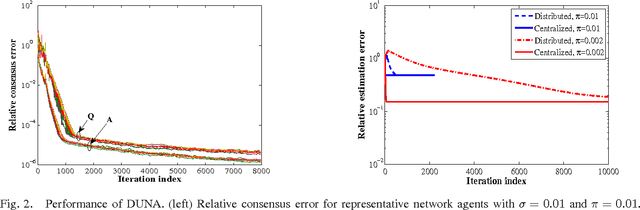
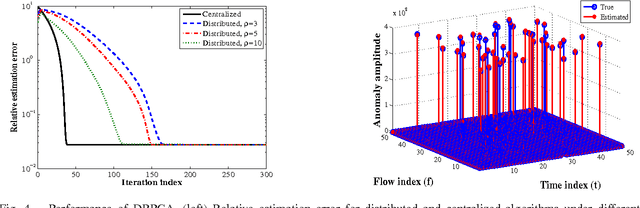
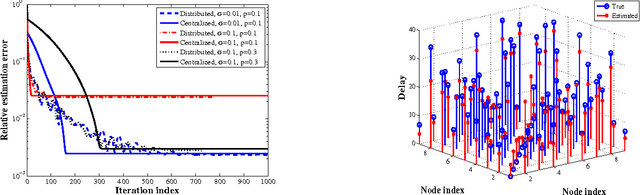
Given a limited number of entries from the superposition of a low-rank matrix plus the product of a known fat compression matrix times a sparse matrix, recovery of the low-rank and sparse components is a fundamental task subsuming compressed sensing, matrix completion, and principal components pursuit. This paper develops algorithms for distributed sparsity-regularized rank minimization over networks, when the nuclear- and $\ell_1$-norm are used as surrogates to the rank and nonzero entry counts of the sought matrices, respectively. While nuclear-norm minimization has well-documented merits when centralized processing is viable, non-separability of the singular-value sum challenges its distributed minimization. To overcome this limitation, an alternative characterization of the nuclear norm is adopted which leads to a separable, yet non-convex cost minimized via the alternating-direction method of multipliers. The novel distributed iterations entail reduced-complexity per-node tasks, and affordable message passing among single-hop neighbors. Interestingly, upon convergence the distributed (non-convex) estimator provably attains the global optimum of its centralized counterpart, regardless of initialization. Several application domains are outlined to highlight the generality and impact of the proposed framework. These include unveiling traffic anomalies in backbone networks, predicting networkwide path latencies, and mapping the RF ambiance using wireless cognitive radios. Simulations with synthetic and real network data corroborate the convergence of the novel distributed algorithm, and its centralized performance guarantees.
Robust PCA as Bilinear Decomposition with Outlier-Sparsity Regularization
Nov 08, 2011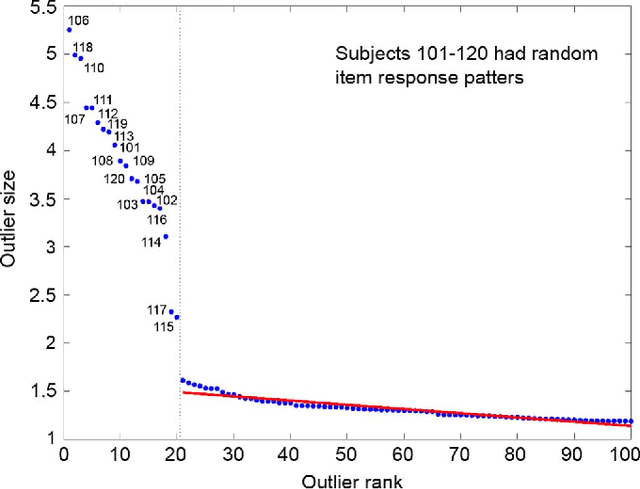
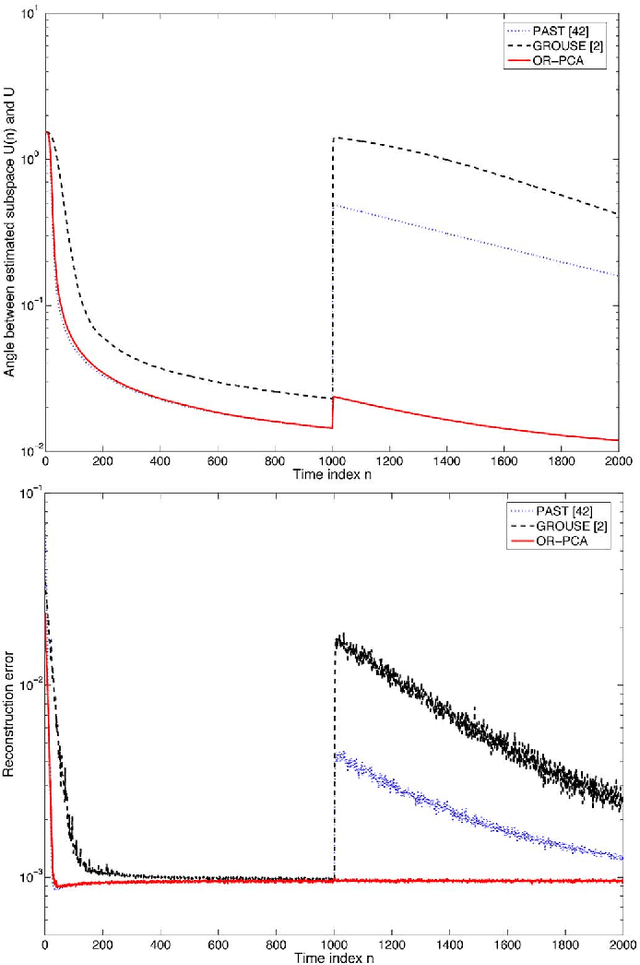
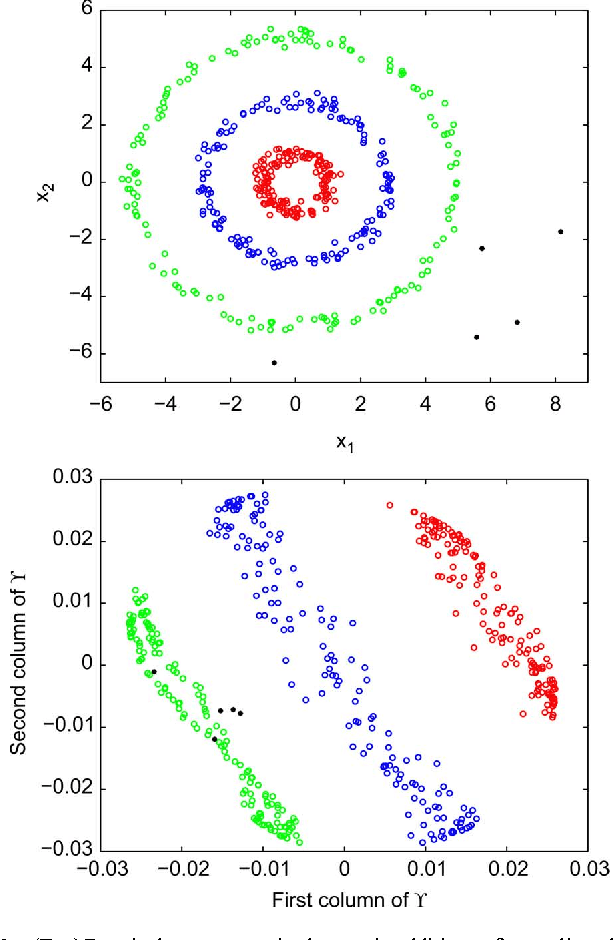

Principal component analysis (PCA) is widely used for dimensionality reduction, with well-documented merits in various applications involving high-dimensional data, including computer vision, preference measurement, and bioinformatics. In this context, the fresh look advocated here permeates benefits from variable selection and compressive sampling, to robustify PCA against outliers. A least-trimmed squares estimator of a low-rank bilinear factor analysis model is shown closely related to that obtained from an $\ell_0$-(pseudo)norm-regularized criterion encouraging sparsity in a matrix explicitly modeling the outliers. This connection suggests robust PCA schemes based on convex relaxation, which lead naturally to a family of robust estimators encompassing Huber's optimal M-class as a special case. Outliers are identified by tuning a regularization parameter, which amounts to controlling sparsity of the outlier matrix along the whole robustification path of (group) least-absolute shrinkage and selection operator (Lasso) solutions. Beyond its neat ties to robust statistics, the developed outlier-aware PCA framework is versatile to accommodate novel and scalable algorithms to: i) track the low-rank signal subspace robustly, as new data are acquired in real time; and ii) determine principal components robustly in (possibly) infinite-dimensional feature spaces. Synthetic and real data tests corroborate the effectiveness of the proposed robust PCA schemes, when used to identify aberrant responses in personality assessment surveys, as well as unveil communities in social networks, and intruders from video surveillance data.