 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Flows on Tori and Spheres
Feb 06, 2020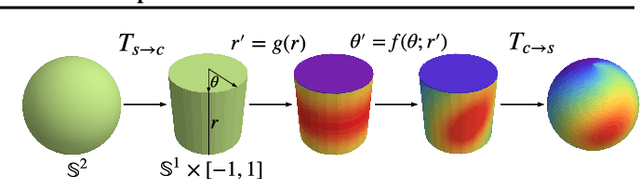


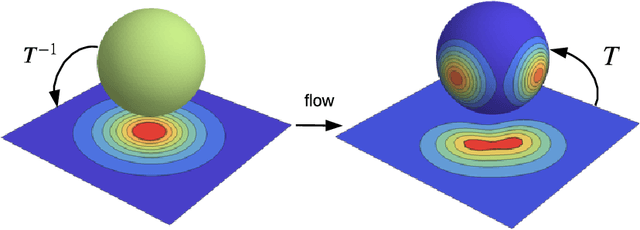
Normalizing flows are a powerful tool for building expressive distributions in high dimensions. So far, most of the literature has concentrated on learning flows on Euclidean spaces. Some problems however, such as those involving angles, are defined on spaces with more complex geometries, such as tori or spheres. In this paper, we propose and compare expressive and numerically stable flows on such spaces. Our flows are built recursively on the dimension of the space, starting from flows on circles, closed intervals or spheres.
Normalizing Flows for Probabilistic Modeling and Inference
Dec 05, 2019
Normalizing flows provide a general mechanism for defining expressive probability distributions, only requiring the specification of a (usually simple) base distribution and a series of bijective transformations. There has been much recent work on normalizing flows, ranging from improving their expressive power to expanding their application. We believe the field has now matured and is in need of a unified perspective. In this review, we attempt to provide such a perspective by describing flows through the lens of probabilistic modeling and inference. We place special emphasis on the fundamental principles of flow design, and discuss foundational topics such as expressive power and computational trade-offs. We also broaden the conceptual framing of flows by relating them to more general probability transformations. Lastly, we summarize the use of flows for tasks such as generative modeling, approximate inference, and supervised learning.
Neural Density Estimation and Likelihood-free Inference
Oct 29, 2019
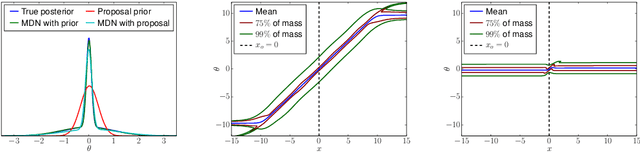
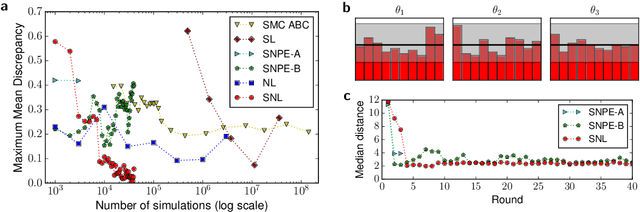
I consider two problems in machine learning and statistics: the problem of estimating the joint probability density of a collection of random variables, known as density estimation, and the problem of inferring model parameters when their likelihood is intractable, known as likelihood-free inference. The contribution of the thesis is a set of new methods for addressing these problems that are based on recent advances in neural networks and deep learning.
Neural Spline Flows
Jun 10, 2019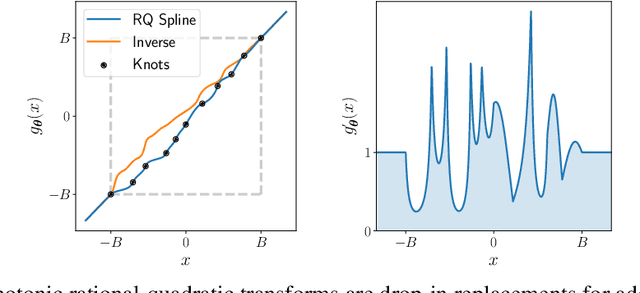
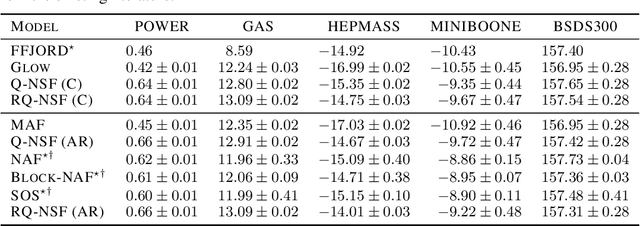
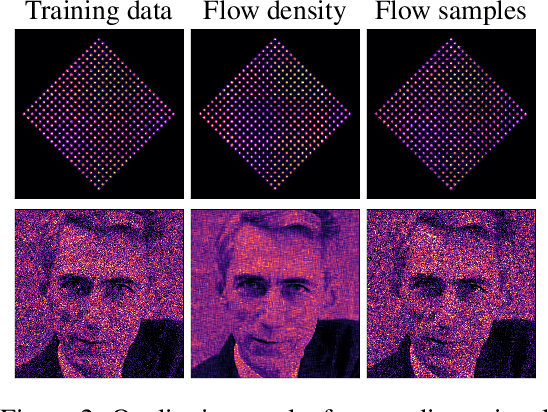
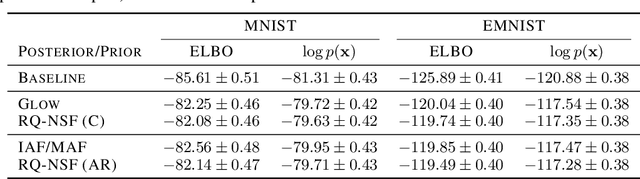
A normalizing flow models a complex probability density as an invertible transformation of a simple base density. Flows based on either coupling or autoregressive transforms both offer exact density evaluation and sampling, but rely on the parameterization of an easily invertible elementwise transformation, whose choice determines the flexibility of these models. Building upon recent work, we propose a fully-differentiable module based on monotonic rational-quadratic splines, which enhances the flexibility of both coupling and autoregressive transforms while retaining analytic invertibility. We demonstrate that neural spline flows improve density estimation, variational inference, and generative modeling of images.
Cubic-Spline Flows
Jun 05, 2019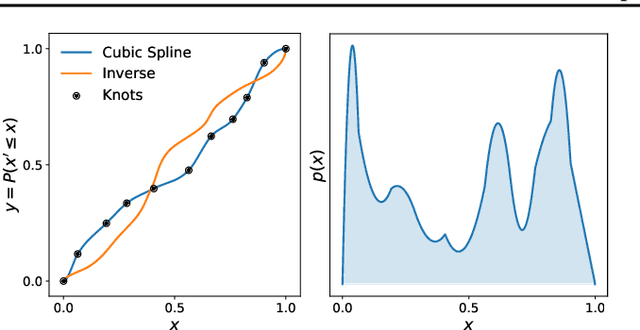
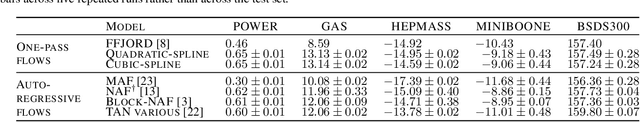
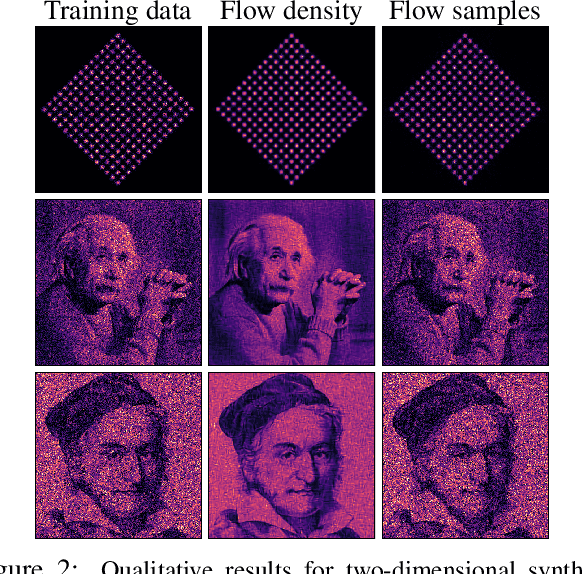

A normalizing flow models a complex probability density as an invertible transformation of a simple density. The invertibility means that we can evaluate densities and generate samples from a flow. In practice, autoregressive flow-based models are slow to invert, making either density estimation or sample generation slow. Flows based on coupling transforms are fast for both tasks, but have previously performed less well at density estimation than autoregressive flows. We stack a new coupling transform, based on monotonic cubic splines, with LU-decomposed linear layers. The resulting cubic-spline flow retains an exact one-pass inverse, can be used to generate high-quality images, and closes the gap with autoregressive flows on a suite of density-estimation tasks.
Sequential Neural Methods for Likelihood-free Inference
Nov 21, 2018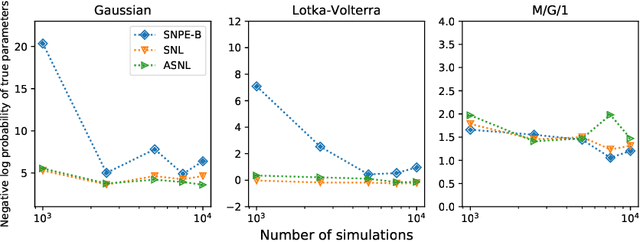
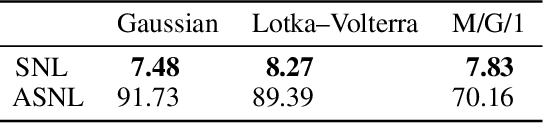
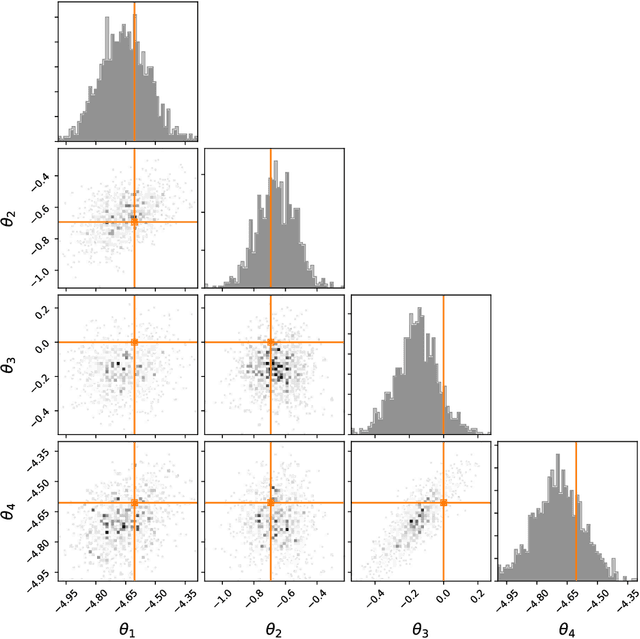
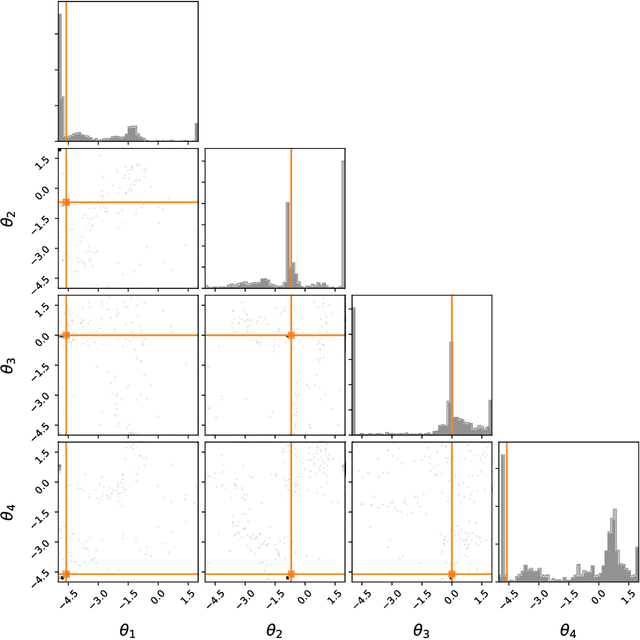
Likelihood-free inference refers to inference when a likelihood function cannot be explicitly evaluated, which is often the case for models based on simulators. Most of the literature is based on sample-based `Approximate Bayesian Computation' methods, but recent work suggests that approaches based on deep neural conditional density estimators can obtain state-of-the-art results with fewer simulations. The neural approaches vary in how they choose which simulations to run and what they learn: an approximate posterior or a surrogate likelihood. This work provides some direct controlled comparisons between these choices.
Masked Autoregressive Flow for Density Estimation
Jun 14, 2018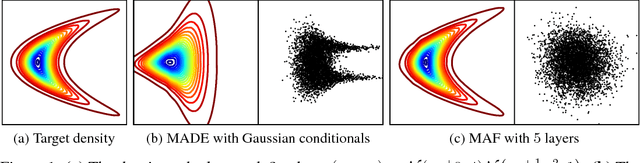

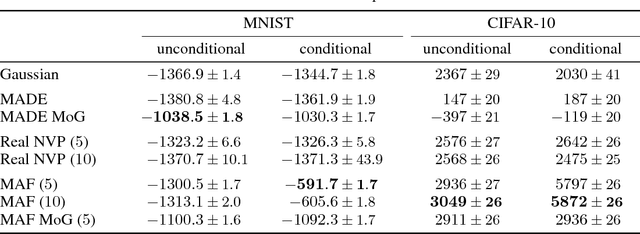
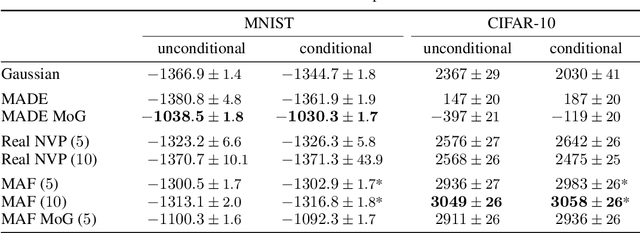
Autoregressive models are among the best performing neural density estimators. We describe an approach for increasing the flexibility of an autoregressive model, based on modelling the random numbers that the model uses internally when generating data. By constructing a stack of autoregressive models, each modelling the random numbers of the next model in the stack, we obtain a type of normalizing flow suitable for density estimation, which we call Masked Autoregressive Flow. This type of flow is closely related to Inverse Autoregressive Flow and is a generalization of Real NVP. Masked Autoregressive Flow achieves state-of-the-art performance in a range of general-purpose density estimation tasks.
Sequential Neural Likelihood: Fast Likelihood-free Inference with Autoregressive Flows
May 18, 2018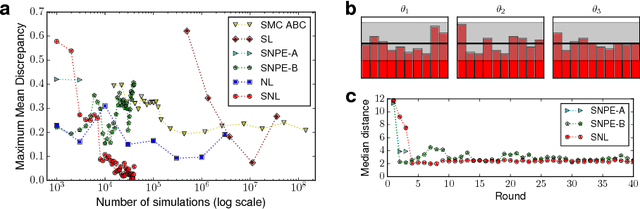
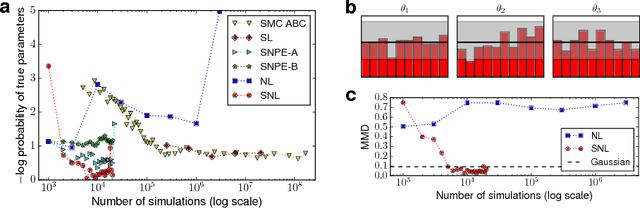
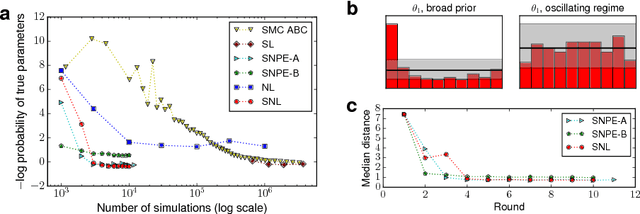
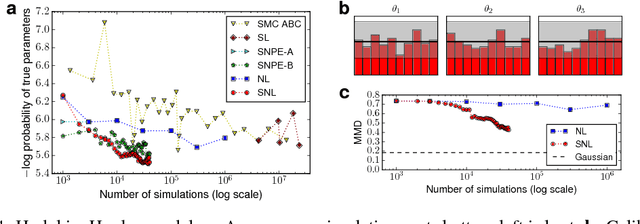
We present Sequential Neural Likelihood (SNL), a new method for Bayesian inference in simulator models, where the likelihood is intractable but simulating data from the model is possible. SNL trains an autoregressive flow on simulated data in order to learn a model of the likelihood in the region of high posterior density. A sequential training procedure guides simulations and reduces simulation cost by orders of magnitude. We show that SNL is more robust, more accurate and requires less tuning than related state-of-the-art methods which target the posterior, and discuss diagnostics for assessing calibration, convergence and goodness-of-fit.
Fast $ε$-free Inference of Simulation Models with Bayesian Conditional Density Estimation
Apr 02, 2018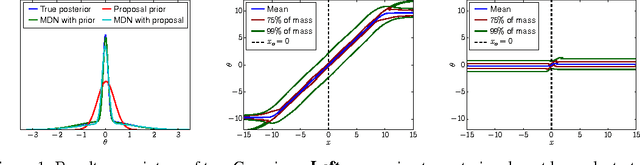
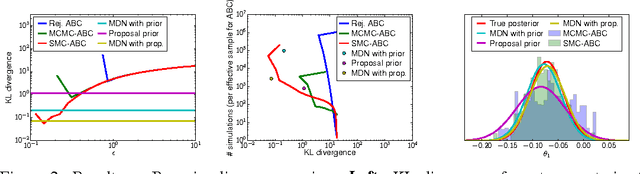
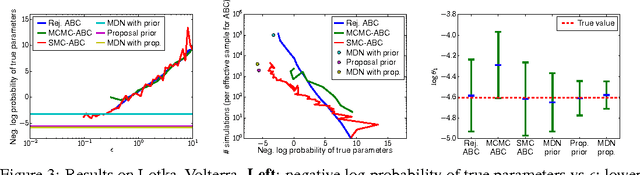
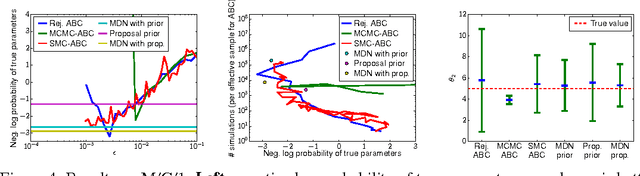
Many statistical models can be simulated forwards but have intractable likelihoods. Approximate Bayesian Computation (ABC) methods are used to infer properties of these models from data. Traditionally these methods approximate the posterior over parameters by conditioning on data being inside an $\epsilon$-ball around the observed data, which is only correct in the limit $\epsilon\!\rightarrow\!0$. Monte Carlo methods can then draw samples from the approximate posterior to approximate predictions or error bars on parameters. These algorithms critically slow down as $\epsilon\!\rightarrow\!0$, and in practice draw samples from a broader distribution than the posterior. We propose a new approach to likelihood-free inference based on Bayesian conditional density estimation. Preliminary inferences based on limited simulation data are used to guide later simulations. In some cases, learning an accurate parametric representation of the entire true posterior distribution requires fewer model simulations than Monte Carlo ABC methods need to produce a single sample from an approximate posterior.
Distilling Model Knowledge
Oct 08, 2015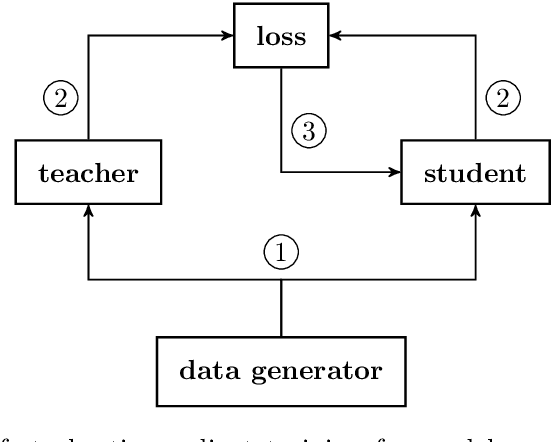
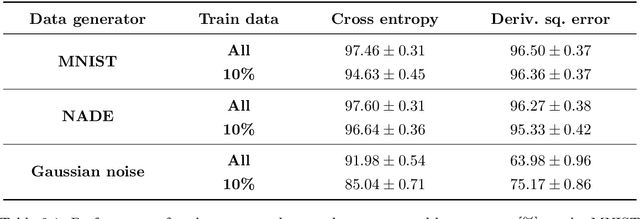
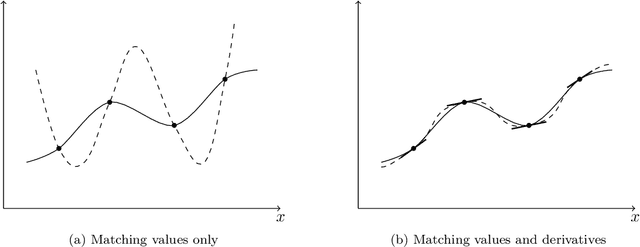
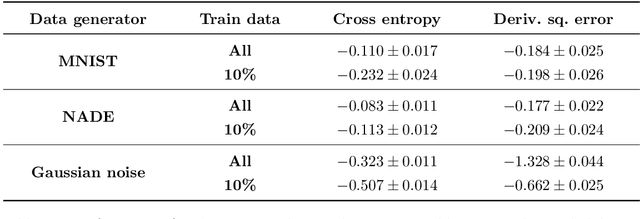
Top-performing machine learning systems, such as deep neural networks, large ensembles and complex probabilistic graphical models, can be expensive to store, slow to evaluate and hard to integrate into larger systems. Ideally, we would like to replace such cumbersome models with simpler models that perform equally well. In this thesis, we study knowledge distillation, the idea of extracting the knowledge contained in a complex model and injecting it into a more convenient model. We present a general framework for knowledge distillation, whereby a convenient model of our choosing learns how to mimic a complex model, by observing the latter's behaviour and being penalized whenever it fails to reproduce it. We develop our framework within the context of three distinct machine learning applications: (a) model compression, where we compress large discriminative models, such as ensembles of neural networks, into models of much smaller size; (b) compact predictive distributions for Bayesian inference, where we distil large bags of MCMC samples into compact predictive distributions in closed form; (c) intractable generative models, where we distil unnormalizable models such as RBMs into tractable models such as NADEs. We contribute to the state of the art with novel techniques and ideas. In model compression, we describe and implement derivative matching, which allows for better distillation when data is scarce. In compact predictive distributions, we introduce online distillation, which allows for significant savings in memory. Finally, in intractable generative models, we show how to use distilled models to robustly estimate intractable quantities of the original model, such as its intractable partition function.