 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSV-ViT: A Vision Transformer with the Variable-sized Cortical Supervertices for Detection of Alzheimer's Disease Pathologies
May 26, 2026Confirming Alzheimer's disease (AD) typically relies on positron emission tomography (PET), which remains costly and invasive, motivating the use of structural MRI-based prescreening. Deep learning on non-Euclidean manifolds, particularly brain cortical surfaces, faces significant challenges due to the data's spherical topology. Recent surface models have enabled learning from cortical surface data; however, imposing face-based uniform patches often causes duplicate vertices at patch boundaries. In general, many surface-based models are limited in their awareness of the region of interest (ROI), which can result in non-cortical regions, such as the medial wall, being included. We propose a cortical surface tokenization that performs ROI-preserving, vertex-based, variable-sized patch partitioning. We refer to these cortical surface patches as cortical supervertices (CSVs). Building on this representation, we design the CSV Vision Transformer (CSV-ViT), a variable-size patch-tolerant Vision Transformer that uses padding and a mask-aware patch embedding. We used T1-weighted MRI and evaluated our framework by classifying AD-related status into three categories: AD diagnosis, amyloid positivity, and tau positivity. Across the experiments, CSV-ViT achieved higher classification performance than recent surface-based models. The results suggest that the proposed CSV-ViT may support MRI-based prediction of AD-related status prior to PET or CSF confirmation.
Improved Multiscale Structural Mapping with Supervertex Vision Transformer for the Detection of Alzheimer's Disease Neurodegeneration
Apr 16, 2026Alzheimer's disease (AD) confirmation often relies on positron emission tomography (PET) or cerebrospinal fluid (CSF) analysis, which are costly and invasive. Consequently, structural MRI biomarkers such as cortical thickness (CT) are widely used for non-invasive AD screening. Multiscale structural mapping (MSSM) was recently proposed to integrate gray-white matter contrasts (GWCs) with CT from a single T1-weighted MRI (T1w) scan. Building on this framework, we propose MSSM+, together with surface supervertex mapping (SSVM) and a Supervertex Vision Transformer (SV-ViT). 3D T1w images from individuals with AD and cognitively normal (CN) controls were analyzed. MSSM+ extends MSSM by incorporating sulcal depth and cortical curvature at the vertex level. SSVM partitions the cortical surface into supervertices (surface patches) that effectively represent inter- and intra-regional spatial relationships. SV-ViT is a Vision Transformer architecture operating on these supervertices, enabling anatomically informed learning from surface mesh representations. Compared with MSSM, MSSM+ identified more spatially extensive and statistically significant group differences between AD and CN. In AD vs. CN classification, MSSM+ achieved a 3%p higher area under the precision-recall curve than MSSM. Vendor-specific analyses further demonstrated reduced signal variability and consistently improved classification performance across MR manufacturers relative to CT, GWCs, and MSSM. These findings suggest that MSSM+ combined with SV-ViT is a promising MRI-based imaging marker for AD detection prior to CSF/PET confirmation.
ADP-DiT: Text-Guided Diffusion Transformer for Brain Image Generation in Alzheimer's Disease Progression
Apr 15, 2026Alzheimer's disease (AD) progresses heterogeneously across individuals, motivating subject-specific synthesis of follow-up magnetic resonance imaging (MRI) to support progression assessment. While Diffusion Transformers (DiT), an emerging transformer-based diffusion model, offer a scalable backbone for image synthesis, longitudinal AD MRI generation with clinically interpretable control over follow-up time and participant metadata remains underexplored. We present ADP-DiT, an interval-aware, clinically text-conditioned diffusion transformer for longitudinal AD MRI synthesis. ADP-DiT encodes follow-up interval together with multi-domain demographic, diagnostic (CN/MCI/AD), and neuropsychological information as a natural-language prompt, enabling time-specific control beyond coarse diagnostic stages. To inject this conditioning effectively, we use dual text encoders-OpenCLIP for vision-language alignment and T5 for richer clinical-language understanding. Their embeddings are fused into DiT through cross-attention for fine-grained guidance and adaptive layer normalization for global modulation. We further enhance anatomical fidelity by applying rotary positional embeddings to image tokens and performing diffusion in a pre-trained SDXL-VAE latent space to enable efficient high-resolution reconstruction. On 3,321 longitudinal 3T T1-weighted scans from 712 participants (259,038 image slices), ADP-DiT achieves SSIM 0.8739 and PSNR 29.32 dB, improving over a DiT baseline by +0.1087 SSIM and +6.08 dB PSNR while capturing progression-related changes such as ventricular enlargement and shrinking hippocampus. These results suggest that integrating comprehensive, subject-specific clinical conditions with architectures can improve longitudinal AD MRI synthesis.
OurDB: Ouroboric Domain Bridging for Multi-Target Domain Adaptive Semantic Segmentation
Mar 18, 2024



Multi-target domain adaptation (MTDA) for semantic segmentation poses a significant challenge, as it involves multiple target domains with varying distributions. The goal of MTDA is to minimize the domain discrepancies among a single source and multi-target domains, aiming to train a single model that excels across all target domains. Previous MTDA approaches typically employ multiple teacher architectures, where each teacher specializes in one target domain to simplify the task. However, these architectures hinder the student model from fully assimilating comprehensive knowledge from all target-specific teachers and escalate training costs with increasing target domains. In this paper, we propose an ouroboric domain bridging (OurDB) framework, offering an efficient solution to the MTDA problem using a single teacher architecture. This framework dynamically cycles through multiple target domains, aligning each domain individually to restrain the biased alignment problem, and utilizes Fisher information to minimize the forgetting of knowledge from previous target domains. We also propose a context-guided class-wise mixup (CGMix) that leverages contextual information tailored to diverse target contexts in MTDA. Experimental evaluations conducted on four urban driving datasets (i.e., GTA5, Cityscapes, IDD, and Mapillary) demonstrate the superiority of our method over existing state-of-the-art approaches.
itKD: Interchange Transfer-based Knowledge Distillation for 3D Object Detection
May 31, 2022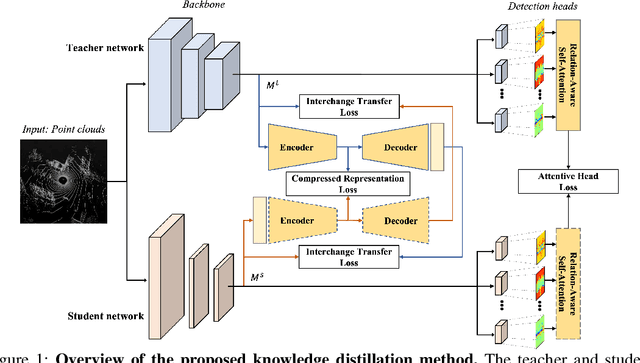
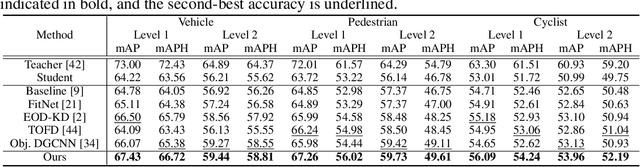
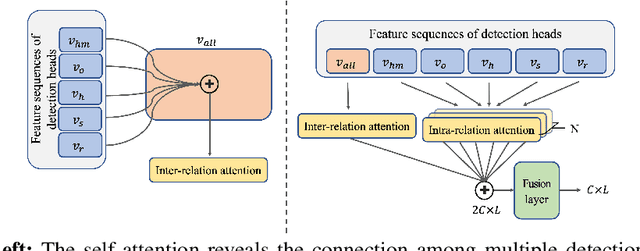
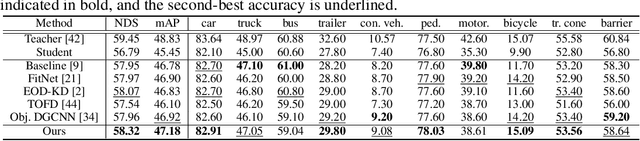
Recently, point-cloud based 3D object detectors have achieved remarkable progress. However, most studies are limited to the development of deep learning architectures for improving only their accuracy. In this paper, we propose an autoencoder-style framework comprising channel-wise compression and decompression via interchange transfer for knowledge distillation. To learn the map-view feature of a teacher network, the features from a teacher and student network are independently passed through the shared autoencoder; here, we use a compressed representation loss that binds the channel-wised compression knowledge from both the networks as a kind of regularization. The decompressed features are transferred in opposite directions to reduce the gap in the interchange reconstructions. Lastly, we present an attentive head loss for matching the pivotal detection information drawn by the multi-head self-attention mechanism. Through extensive experiments, we verify that our method can learn the lightweight model that is well-aligned with the 3D point cloud detection task and we demonstrate its superiority using the well-known public datasets Waymo and nuScenes.