 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Multiscale Structural Mapping with Supervertex Vision Transformer for the Detection of Alzheimer's Disease Neurodegeneration
Apr 16, 2026Alzheimer's disease (AD) confirmation often relies on positron emission tomography (PET) or cerebrospinal fluid (CSF) analysis, which are costly and invasive. Consequently, structural MRI biomarkers such as cortical thickness (CT) are widely used for non-invasive AD screening. Multiscale structural mapping (MSSM) was recently proposed to integrate gray-white matter contrasts (GWCs) with CT from a single T1-weighted MRI (T1w) scan. Building on this framework, we propose MSSM+, together with surface supervertex mapping (SSVM) and a Supervertex Vision Transformer (SV-ViT). 3D T1w images from individuals with AD and cognitively normal (CN) controls were analyzed. MSSM+ extends MSSM by incorporating sulcal depth and cortical curvature at the vertex level. SSVM partitions the cortical surface into supervertices (surface patches) that effectively represent inter- and intra-regional spatial relationships. SV-ViT is a Vision Transformer architecture operating on these supervertices, enabling anatomically informed learning from surface mesh representations. Compared with MSSM, MSSM+ identified more spatially extensive and statistically significant group differences between AD and CN. In AD vs. CN classification, MSSM+ achieved a 3%p higher area under the precision-recall curve than MSSM. Vendor-specific analyses further demonstrated reduced signal variability and consistently improved classification performance across MR manufacturers relative to CT, GWCs, and MSSM. These findings suggest that MSSM+ combined with SV-ViT is a promising MRI-based imaging marker for AD detection prior to CSF/PET confirmation.
SDnDTI: Self-supervised deep learning-based denoising for diffusion tensor MRI
Nov 14, 2021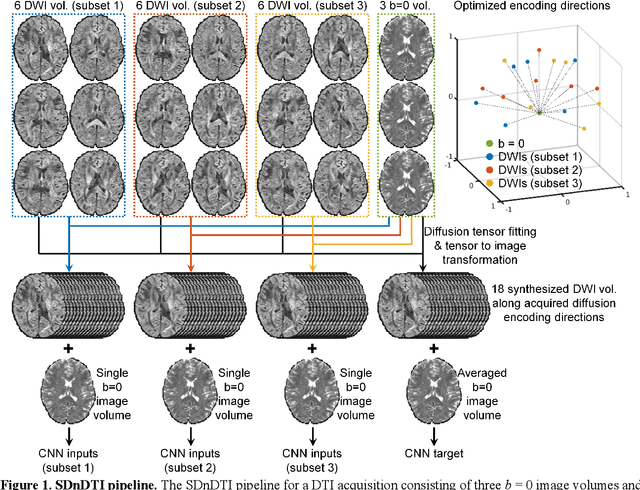
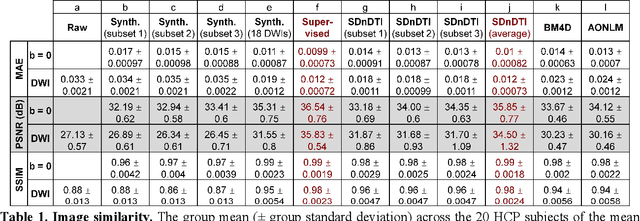
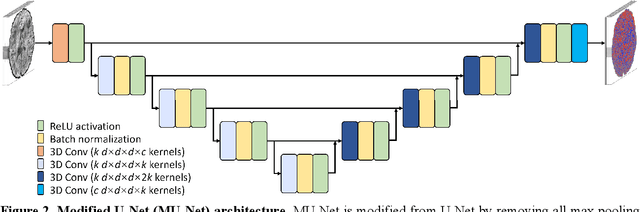
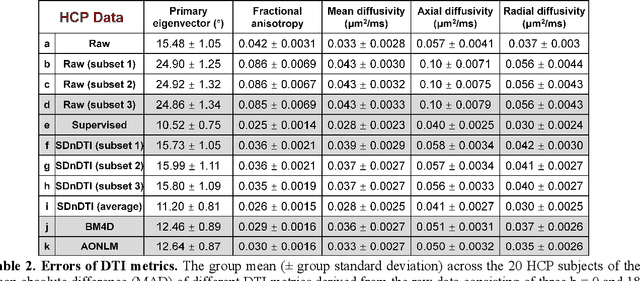
The noise in diffusion-weighted images (DWIs) decreases the accuracy and precision of diffusion tensor magnetic resonance imaging (DTI) derived microstructural parameters and leads to prolonged acquisition time for achieving improved signal-to-noise ratio (SNR). Deep learning-based image denoising using convolutional neural networks (CNNs) has superior performance but often requires additional high-SNR data for supervising the training of CNNs, which reduces the practical feasibility. We develop a self-supervised deep learning-based method entitled "SDnDTI" for denoising DTI data, which does not require additional high-SNR data for training. Specifically, SDnDTI divides multi-directional DTI data into many subsets, each consisting of six DWI volumes along optimally chosen diffusion-encoding directions that are robust to noise for the tensor fitting, and then synthesizes DWI volumes along all acquired directions from the diffusion tensors fitted using each subset of the data as the input data of CNNs. On the other hand, SDnDTI synthesizes DWI volumes along acquired diffusion-encoding directions with higher SNR from the diffusion tensors fitted using all acquired data as the training target. SDnDTI removes noise from each subset of synthesized DWI volumes using a deep 3-dimensional CNN to match the quality of the cleaner target DWI volumes and achieves even higher SNR by averaging all subsets of denoised data. The denoising efficacy of SDnDTI is demonstrated on two datasets provided by the Human Connectome Project (HCP) and the Lifespan HCP in Aging. The SDnDTI results preserve image sharpness and textural details and substantially improve upon those from the raw data. The results of SDnDTI are comparable to those from supervised learning-based denoising and outperform those from state-of-the-art conventional denoising algorithms including BM4D, AONLM and MPPCA.