 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Prognostics with Predictive Uncertainty Estimation using Ensemble of Deep Ordinal Regression Models
Apr 02, 2019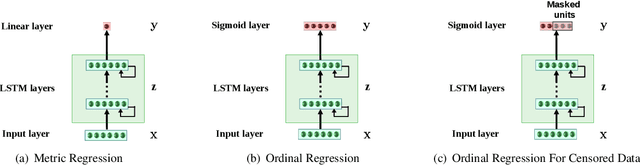
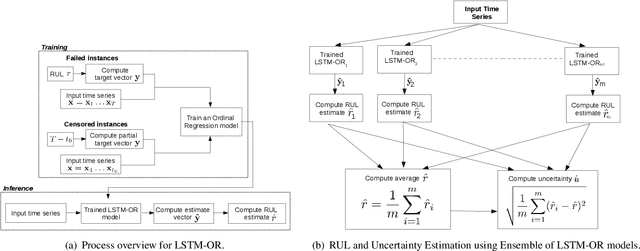
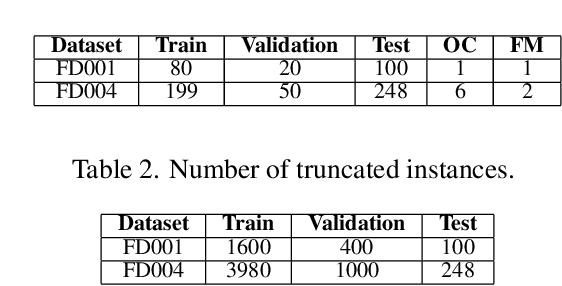
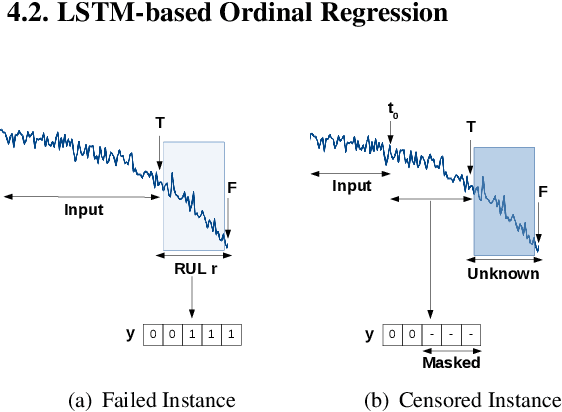
Prognostics or Remaining Useful Life (RUL) Estimation from multi-sensor time series data is useful to enable condition-based maintenance and ensure high operational availability of equipment. We propose a novel deep learning based approach for Prognostics with Uncertainty Quantification that is useful in scenarios where: (i) access to labeled failure data is scarce due to rarity of failures (ii) future operational conditions are unobserved and (iii) inherent noise is present in the sensor readings. All three scenarios mentioned are unavoidable sources of uncertainty in the RUL estimation process often resulting in unreliable RUL estimates. To address (i), we formulate RUL estimation as an Ordinal Regression (OR) problem, and propose LSTM-OR: deep Long Short Term Memory (LSTM) network based approach to learn the OR function. We show that LSTM-OR naturally allows for incorporation of censored operational instances in training along with the failed instances, leading to more robust learning. To address (ii), we propose a simple yet effective approach to quantify predictive uncertainty in the RUL estimation models by training an ensemble of LSTM-OR models. Through empirical evaluation on C-MAPSS turbofan engine benchmark datasets, we demonstrate that LSTM-OR is significantly better than the commonly used deep metric regression based approaches for RUL estimation, especially when failed training instances are scarce. Further, our uncertainty quantification approach yields high quality predictive uncertainty estimates while also leading to improved RUL estimates compared to single best LSTM-OR models.
Transfer Learning for Clinical Time Series Analysis using Deep Neural Networks
Apr 01, 2019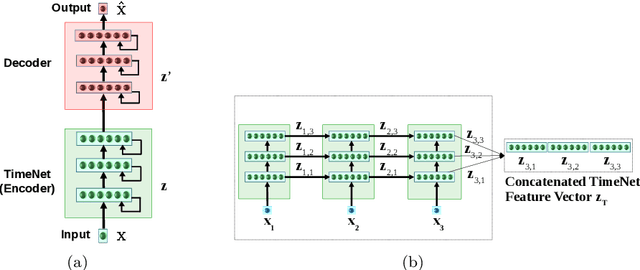
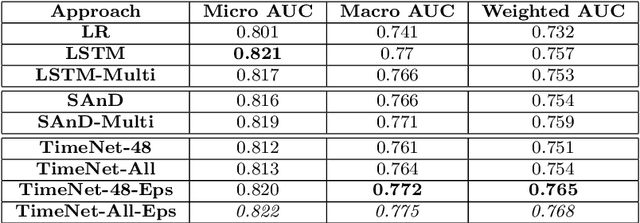
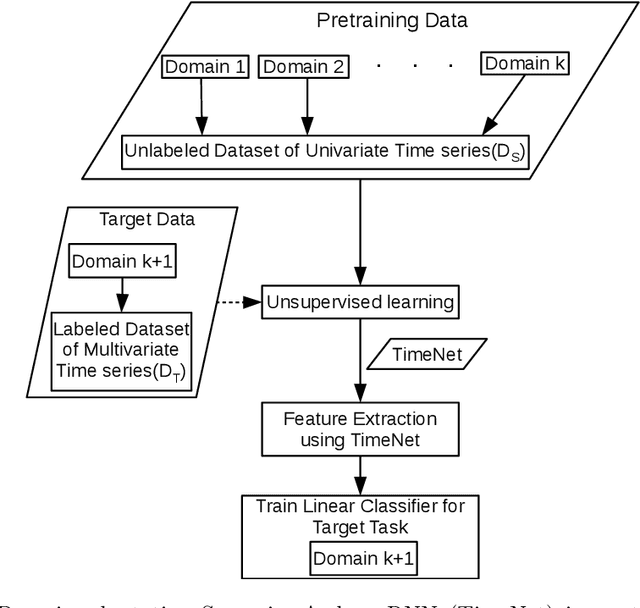
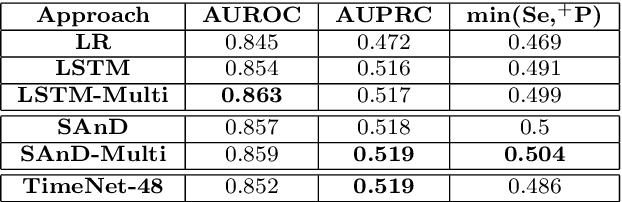
Deep neural networks have shown promising results for various clinical prediction tasks. However, training deep networks such as those based on Recurrent Neural Networks (RNNs) requires large labeled data, significant hyper-parameter tuning effort and expertise, and high computational resources. In this work, we investigate as to what extent can transfer learning address these issues when using deep RNNs to model multivariate clinical time series. We consider two scenarios for transfer learning using RNNs: i) domain-adaptation, i.e., leveraging a deep RNN - namely, TimeNet - pre-trained for feature extraction on time series from diverse domains, and adapting it for feature extraction and subsequent target tasks in healthcare domain, ii) task-adaptation, i.e., pre-training a deep RNN - namely, HealthNet - on diverse tasks in healthcare domain, and adapting it to new target tasks in the same domain. We evaluate the above approaches on publicly available MIMIC-III benchmark dataset, and demonstrate that (a) computationally-efficient linear models trained using features extracted via pre-trained RNNs outperform or, in the worst case, perform as well as deep RNNs and statistical hand-crafted features based models trained specifically for target task; (b) models obtained by adapting pre-trained models for target tasks are significantly more robust to the size of labeled data compared to task-specific RNNs, while also being computationally efficient. We, therefore, conclude that pre-trained deep models like TimeNet and HealthNet allow leveraging the advantages of deep learning for clinical time series analysis tasks, while also minimize dependence on hand-crafted features, deal robustly with scarce labeled training data scenarios without overfitting, as well as reduce dependence on expertise and resources required to train deep networks from scratch.
MEETING BOT: Reinforcement Learning for Dialogue Based Meeting Scheduling
Dec 28, 2018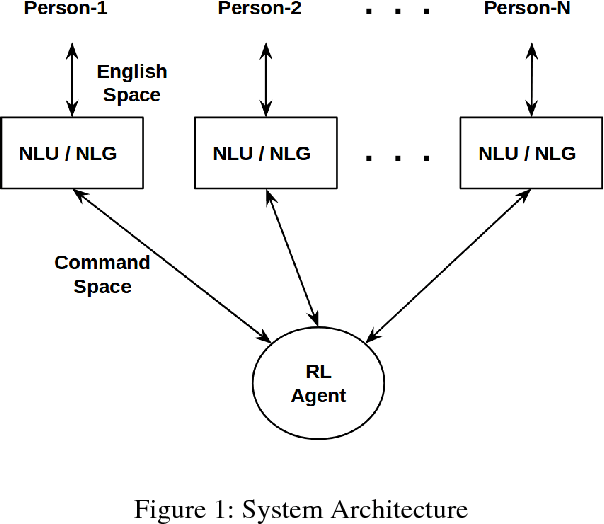
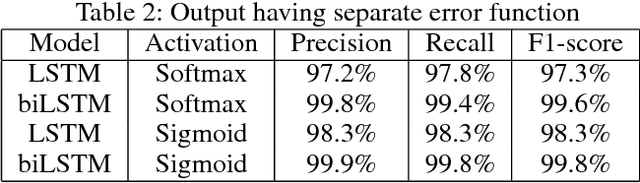
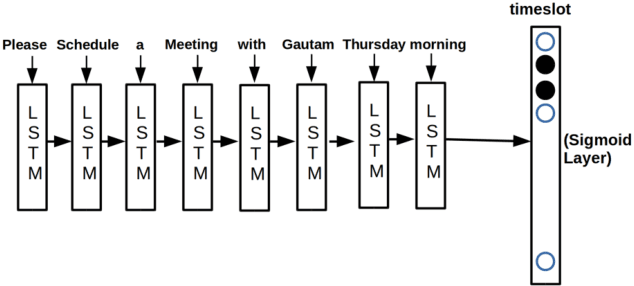
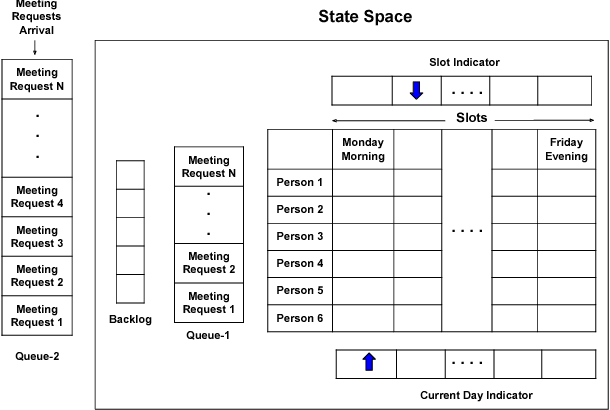
In this paper we present Meeting Bot, a reinforcement learning based conversational system that interacts with multiple users to schedule meetings. The system is able to interpret user utterences and map them to preferred time slots, which are then fed to a reinforcement learning (RL) system with the goal of converging on an agreeable time slot. The RL system is able to adapt to user preferences and environmental changes in meeting arrival rate while still scheduling effectively. Learning is performed via policy gradient with exploration, by utilizing an MLP as an approximator of the policy function. Results demonstrate that the system outperforms standard scheduling algorithms in terms of overall scheduling efficiency. Additionally, the system is able to adapt its strategy to situations when users consistently reject or accept meetings in certain slots (such as Friday afternoon versus Thursday morning), or when the meeting is called by members who are at a more senior designation.
Deep Reader: Information extraction from Document images via relation extraction and Natural Language
Dec 14, 2018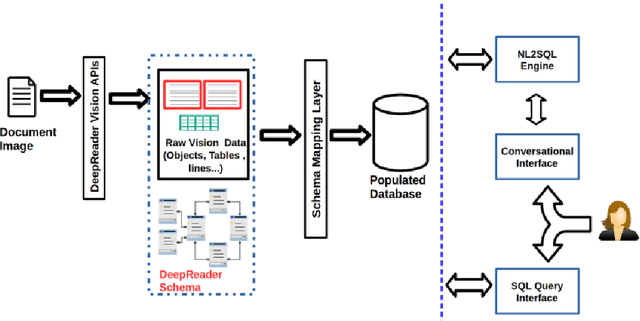
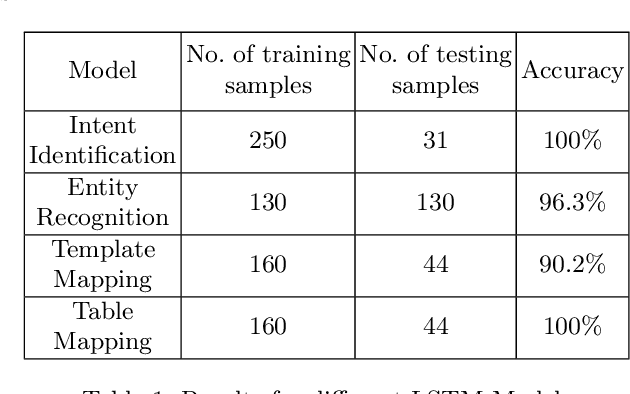
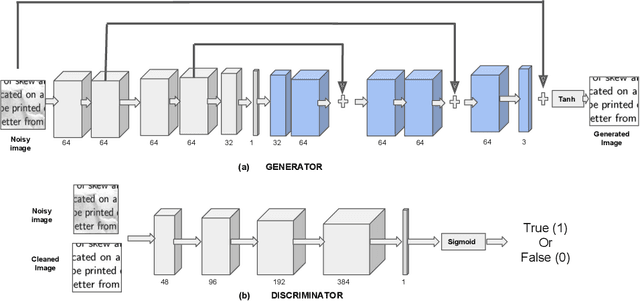

Recent advancements in the area of Computer Vision with state-of-art Neural Networks has given a boost to Optical Character Recognition (OCR) accuracies. However, extracting characters/text alone is often insufficient for relevant information extraction as documents also have a visual structure that is not captured by OCR. Extracting information from tables, charts, footnotes, boxes, headings and retrieving the corresponding structured representation for the document remains a challenge and finds application in a large number of real-world use cases. In this paper, we propose a novel enterprise based end-to-end framework called DeepReader which facilitates information extraction from document images via identification of visual entities and populating a meta relational model across different entities in the document image. The model schema allows for an easy to understand abstraction of the entities detected by the deep vision models and the relationships between them. DeepReader has a suite of state-of-the-art vision algorithms which are applied to recognize handwritten and printed text, eliminate noisy effects, identify the type of documents and detect visual entities like tables, lines and boxes. Deep Reader maps the extracted entities into a rich relational schema so as to capture all the relevant relationships between entities (words, textboxes, lines etc) detected in the document. Relevant information and fields can then be extracted from the document by writing SQL queries on top of the relationship tables. A natural language based interface is added on top of the relationship schema so that a non-technical user, specifying the queries in natural language, can fetch the information with minimal effort. In this paper, we also demonstrate many different capabilities of Deep Reader and report results on a real-world use case.
Prosocial or Selfish? Agents with different behaviors for Contract Negotiation using Reinforcement Learning
Sep 19, 2018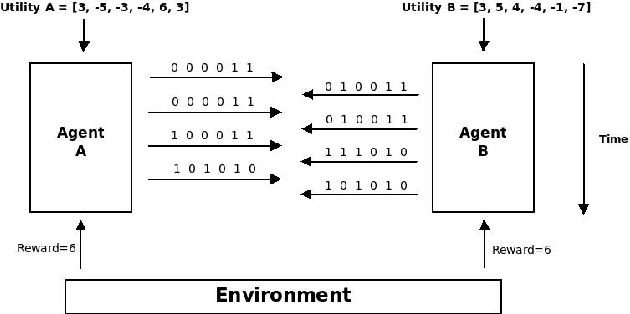
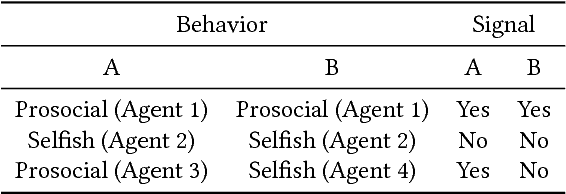
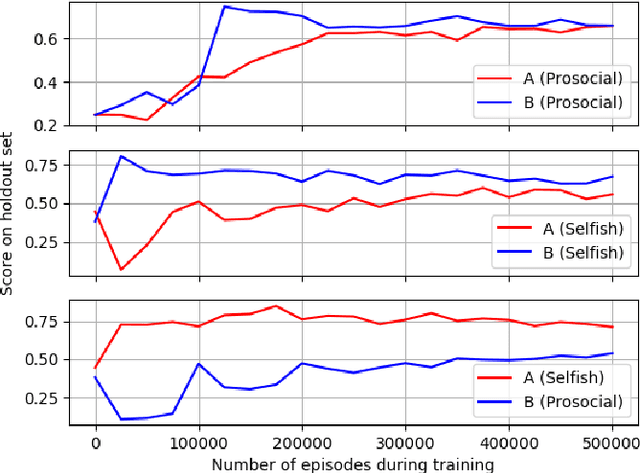
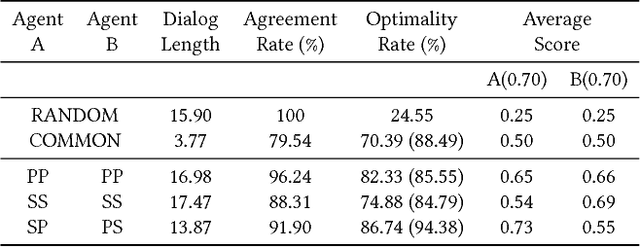
We present an effective technique for training deep learning agents capable of negotiating on a set of clauses in a contract agreement using a simple communication protocol. We use Multi Agent Reinforcement Learning to train both agents simultaneously as they negotiate with each other in the training environment. We also model selfish and prosocial behavior to varying degrees in these agents. Empirical evidence is provided showing consistency in agent behaviors. We further train a meta agent with a mixture of behaviors by learning an ensemble of different models using reinforcement learning. Finally, to ascertain the deployability of the negotiating agents, we conducted experiments pitting the trained agents against human players. Results demonstrate that the agents are able to hold their own against human players, often emerging as winners in the negotiation. Our experiments demonstrate that the meta agent is able to reasonably emulate human behavior.
Transfer Learning for Clinical Time Series Analysis using Recurrent Neural Networks
Jul 04, 2018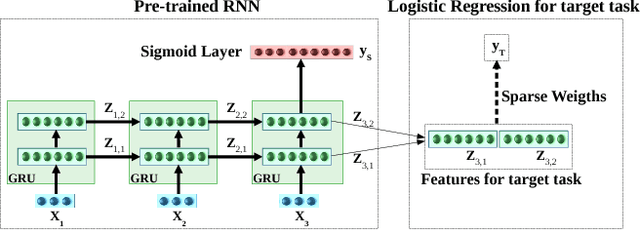

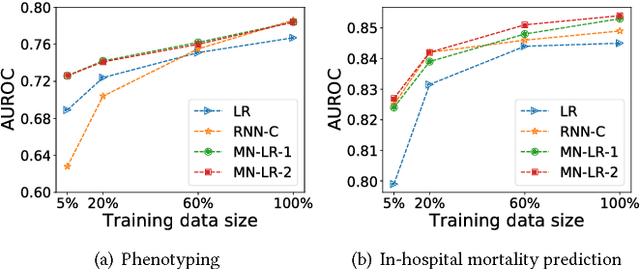

Deep neural networks have shown promising results for various clinical prediction tasks such as diagnosis, mortality prediction, predicting duration of stay in hospital, etc. However, training deep networks -- such as those based on Recurrent Neural Networks (RNNs) -- requires large labeled data, high computational resources, and significant hyperparameter tuning effort. In this work, we investigate as to what extent can transfer learning address these issues when using deep RNNs to model multivariate clinical time series. We consider transferring the knowledge captured in an RNN trained on several source tasks simultaneously using a large labeled dataset to build the model for a target task with limited labeled data. An RNN pre-trained on several tasks provides generic features, which are then used to build simpler linear models for new target tasks without training task-specific RNNs. For evaluation, we train a deep RNN to identify several patient phenotypes on time series from MIMIC-III database, and then use the features extracted using that RNN to build classifiers for identifying previously unseen phenotypes, and also for a seemingly unrelated task of in-hospital mortality. We demonstrate that (i) models trained on features extracted using pre-trained RNN outperform or, in the worst case, perform as well as task-specific RNNs; (ii) the models using features from pre-trained models are more robust to the size of labeled data than task-specific RNNs; and (iii) features extracted using pre-trained RNN are generic enough and perform better than typical statistical hand-crafted features.
Crop Planning using Stochastic Visual Optimization
Oct 25, 2017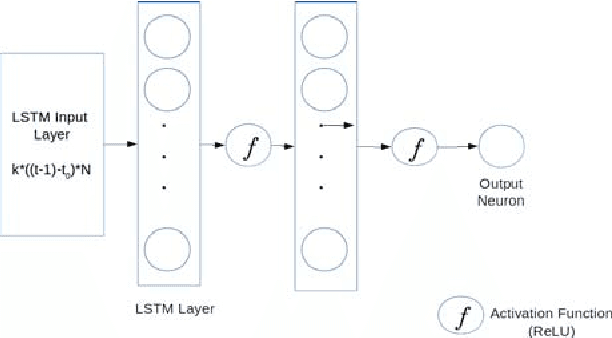
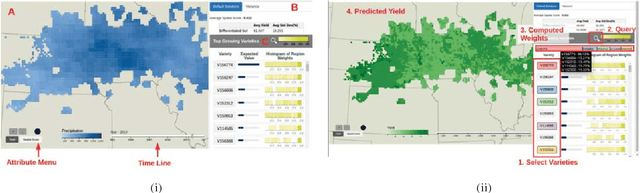
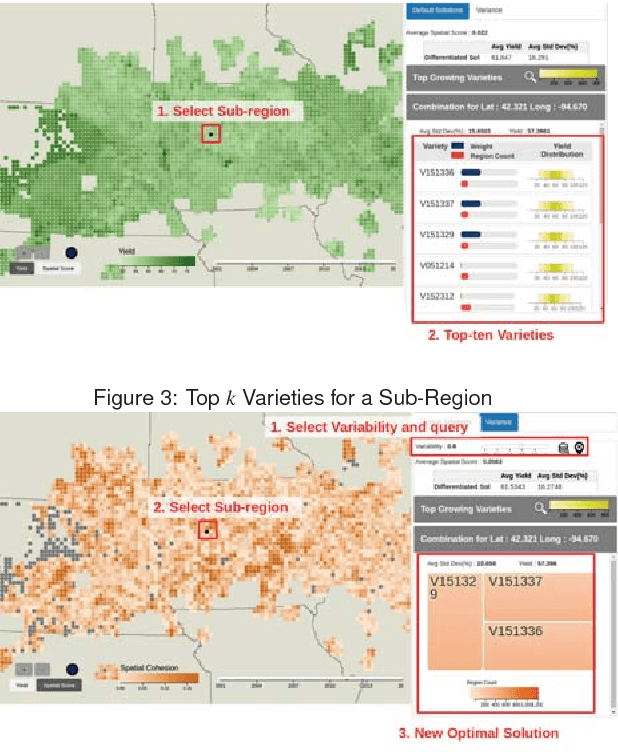
As the world population increases and arable land decreases, it becomes vital to improve the productivity of the agricultural land available. Given the weather and soil properties, farmers need to take critical decisions such as which seed variety to plant and in what proportion, in order to maximize productivity. These decisions are irreversible and any unusual behavior of external factors, such as weather, can have catastrophic impact on the productivity of crop. A variety which is highly desirable to a farmer might be unavailable or in short supply, therefore, it is very critical to evaluate which variety or varieties are more likely to be chosen by farmers from a growing region in order to meet demand. In this paper, we present our visual analytics tool, ViSeed, showcased on the data given in Syngenta 2016 crop data challenge 1 . This tool helps to predict optimal soybean seed variety or mix of varieties in appropriate proportions which is more likely to be chosen by farmers from a growing region. It also allows to analyse solutions generated from our approach and helps in the decision making process by providing insightful visualizations
Predicting Remaining Useful Life using Time Series Embeddings based on Recurrent Neural Networks
Oct 06, 2017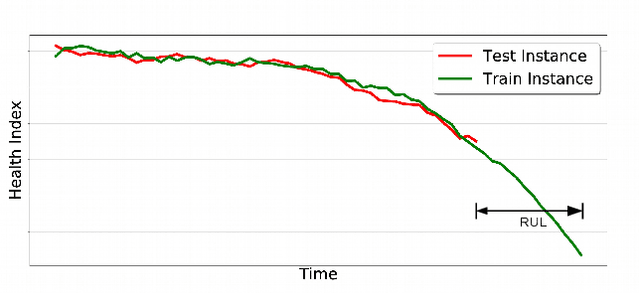
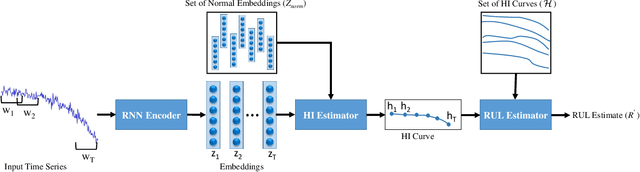

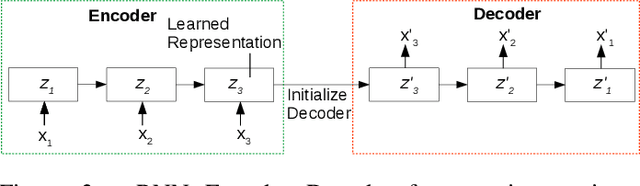
We consider the problem of estimating the remaining useful life (RUL) of a system or a machine from sensor data. Many approaches for RUL estimation based on sensor data make assumptions about how machines degrade. Additionally, sensor data from machines is noisy and often suffers from missing values in many practical settings. We propose Embed-RUL: a novel approach for RUL estimation from sensor data that does not rely on any degradation-trend assumptions, is robust to noise, and handles missing values. Embed-RUL utilizes a sequence-to-sequence model based on Recurrent Neural Networks (RNNs) to generate embeddings for multivariate time series subsequences. The embeddings for normal and degraded machines tend to be different, and are therefore found to be useful for RUL estimation. We show that the embeddings capture the overall pattern in the time series while filtering out the noise, so that the embeddings of two machines with similar operational behavior are close to each other, even when their sensor readings have significant and varying levels of noise content. We perform experiments on publicly available turbofan engine dataset and a proprietary real-world dataset, and demonstrate that Embed-RUL outperforms the previously reported state-of-the-art on several metrics.
Comparative Benchmarking of Causal Discovery Techniques
Sep 12, 2017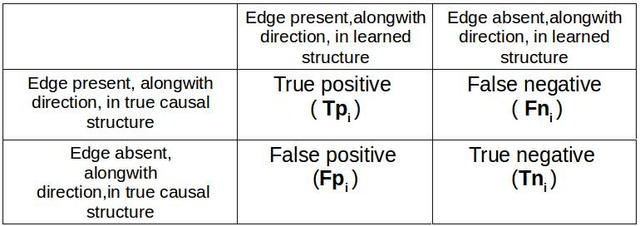
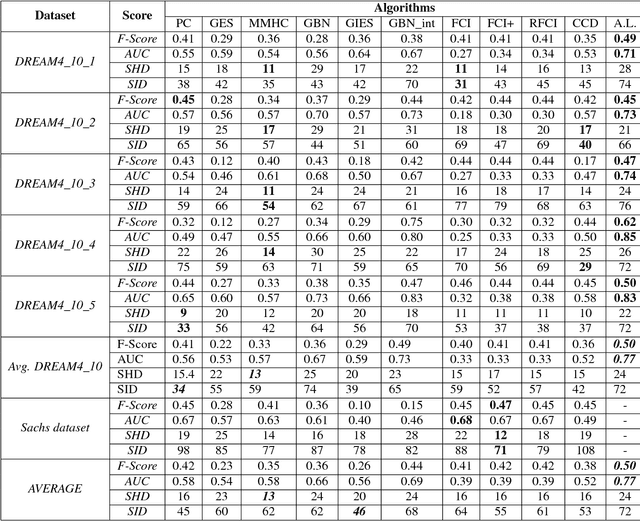
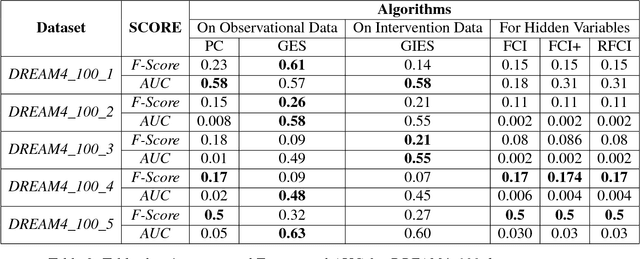
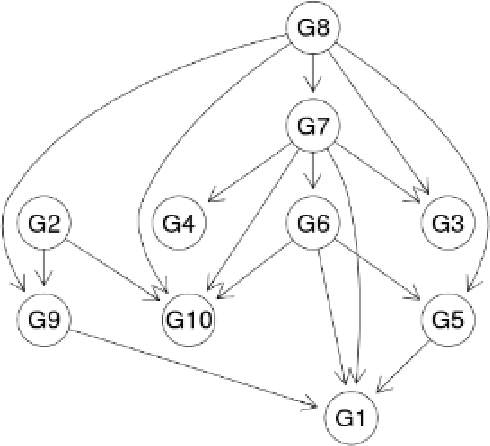
In this paper we present a comprehensive view of prominent causal discovery algorithms, categorized into two main categories (1) assuming acyclic and no latent variables, and (2) allowing both cycles and latent variables, along with experimental results comparing them from three perspectives: (a) structural accuracy, (b) standard predictive accuracy, and (c) accuracy of counterfactual inference. For (b) and (c) we train causal Bayesian networks with structures as predicted by each causal discovery technique to carry out counterfactual or standard predictive inference. We compare causal algorithms on two pub- licly available and one simulated datasets having different sample sizes: small, medium and large. Experiments show that structural accuracy of a technique does not necessarily correlate with higher accuracy of inferencing tasks. Fur- ther, surveyed structure learning algorithms do not perform well in terms of structural accuracy in case of datasets having large number of variables.
TimeNet: Pre-trained deep recurrent neural network for time series classification
Jun 23, 2017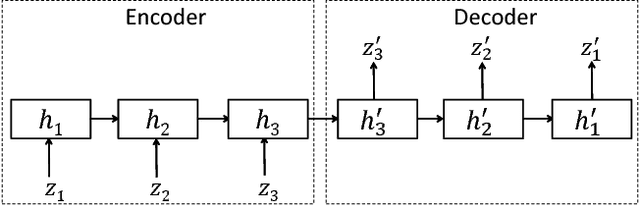
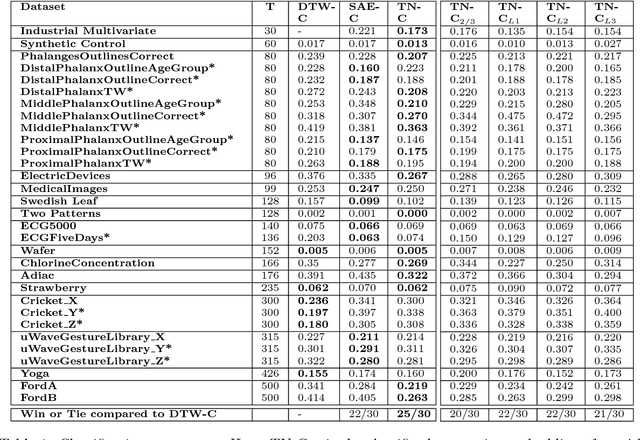

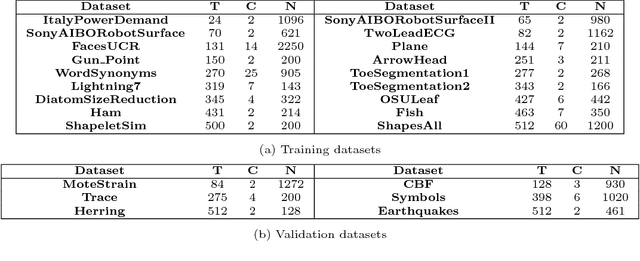
Inspired by the tremendous success of deep Convolutional Neural Networks as generic feature extractors for images, we propose TimeNet: a deep recurrent neural network (RNN) trained on diverse time series in an unsupervised manner using sequence to sequence (seq2seq) models to extract features from time series. Rather than relying on data from the problem domain, TimeNet attempts to generalize time series representation across domains by ingesting time series from several domains simultaneously. Once trained, TimeNet can be used as a generic off-the-shelf feature extractor for time series. The representations or embeddings given by a pre-trained TimeNet are found to be useful for time series classification (TSC). For several publicly available datasets from UCR TSC Archive and an industrial telematics sensor data from vehicles, we observe that a classifier learned over the TimeNet embeddings yields significantly better performance compared to (i) a classifier learned over the embeddings given by a domain-specific RNN, as well as (ii) a nearest neighbor classifier based on Dynamic Time Warping.