 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGyan: An Explainable Neuro-Symbolic Language Model
May 06, 2026Transformer based pre-trained large language models have become ubiquitous. There is increasing evidence to suggest that even with large scale pre-training, these models do not capture complete compositional context and certainly not, the full human analogous context. Besides, by the very nature of the architecture, these models hallucinate, are difficult to maintain, are not easily interpretable and require enormous compute resources for training and inference. Here, we describe Gyan, an explainable language model based on a novel non-transformer architecture, without any of these limitations. Gyan achieves SOTA performance on 3 widely cited data sets and superior performance on two proprietary data sets. The novel architecture decouples the language model from knowledge acquisition and representation. The model draws on rhetorical structure theory, semantic role theory and knowledge-based computational linguistics. Gyan's meaning representation structure captures the complete compositional context and attempts to mimic humans by expanding the context to a 'world model'. AI model adoption critically depends on trust and transparency especially in mission critical use cases. Collectively, our results demonstrate that it is possible to create models which are trustable and reliable for mission critical tasks. We believe our work has tremendous potential for guiding the development of transparent and trusted architectures for language models.
On the Performance of an Explainable Language Model on PubMedQA
Apr 07, 2025



Large language models (LLMs) have shown significant abilities in retrieving medical knowledge, reasoning over it and answering medical questions comparably to physicians. However, these models are not interpretable, hallucinate, are difficult to maintain and require enormous compute resources for training and inference. In this paper, we report results from Gyan, an explainable language model based on an alternative architecture, on the PubmedQA data set. The Gyan LLM is a compositional language model and the model is decoupled from knowledge. Gyan is trustable, transparent, does not hallucinate and does not require significant training or compute resources. Gyan is easily transferable across domains. Gyan-4.3 achieves SOTA results on PubmedQA with 87.1% accuracy compared to 82% by MedPrompt based on GPT-4 and 81.8% by Med-PaLM 2 (Google and DeepMind). We will be reporting results for other medical data sets - MedQA, MedMCQA, MMLU - Medicine in the future.
Crop Planning using Stochastic Visual Optimization
Oct 25, 2017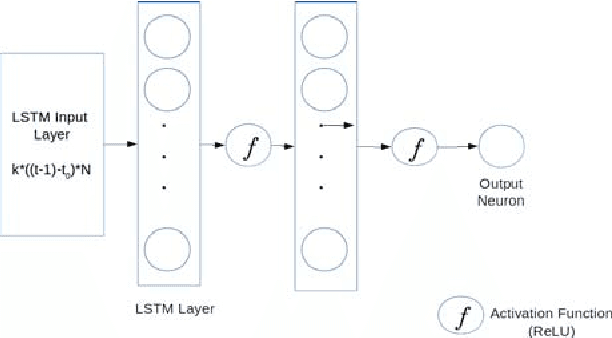
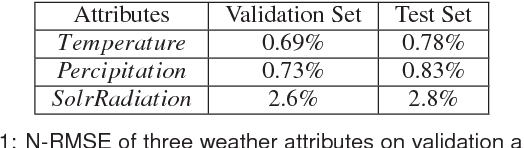
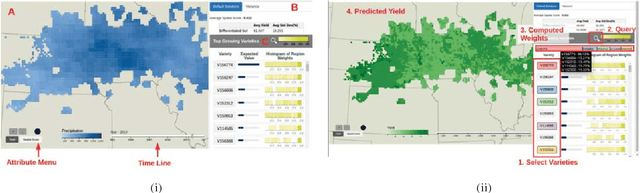
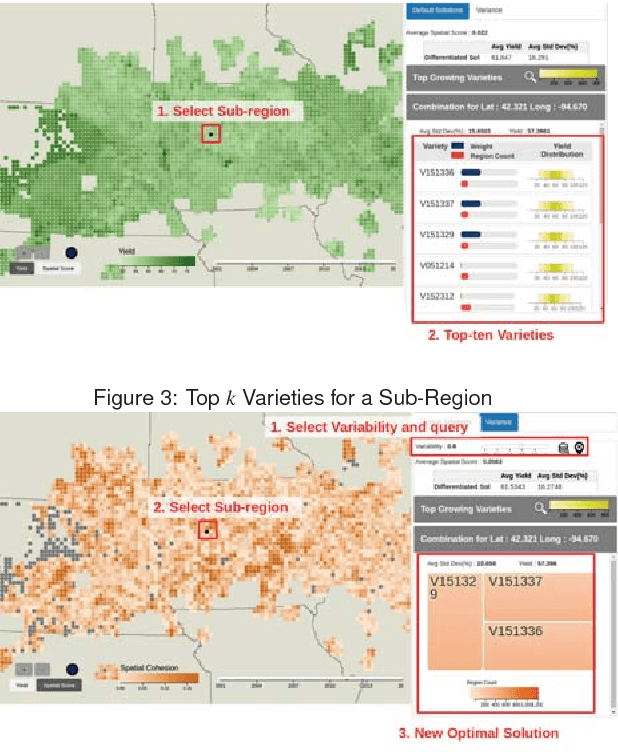
As the world population increases and arable land decreases, it becomes vital to improve the productivity of the agricultural land available. Given the weather and soil properties, farmers need to take critical decisions such as which seed variety to plant and in what proportion, in order to maximize productivity. These decisions are irreversible and any unusual behavior of external factors, such as weather, can have catastrophic impact on the productivity of crop. A variety which is highly desirable to a farmer might be unavailable or in short supply, therefore, it is very critical to evaluate which variety or varieties are more likely to be chosen by farmers from a growing region in order to meet demand. In this paper, we present our visual analytics tool, ViSeed, showcased on the data given in Syngenta 2016 crop data challenge 1 . This tool helps to predict optimal soybean seed variety or mix of varieties in appropriate proportions which is more likely to be chosen by farmers from a growing region. It also allows to analyse solutions generated from our approach and helps in the decision making process by providing insightful visualizations