 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGanesh Ramakrishnan
GLISTER: Generalization based Data Subset Selection for Efficient and Robust Learning
Dec 19, 2020


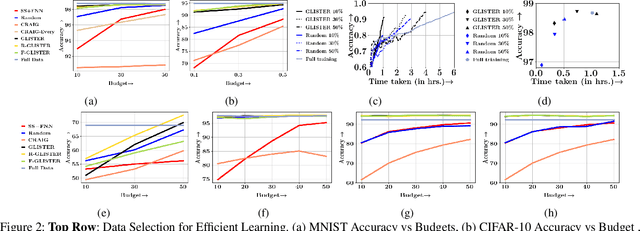
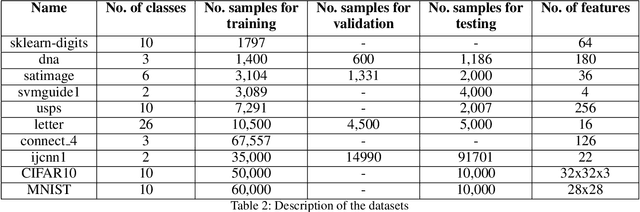
Large scale machine learning and deep models are extremely data-hungry. Unfortunately, obtaining large amounts of labeled data is expensive, and training state-of-the-art models (with hyperparameter tuning) requires significant computing resources and time. Secondly, real-world data is noisy and imbalanced. As a result, several recent papers try to make the training process more efficient and robust. However, most existing work either focuses on robustness or efficiency, but not both. In this work, we introduce Glister, a GeneraLIzation based data Subset selecTion for Efficient and Robust learning framework. We formulate Glister as a mixed discrete-continuous bi-level optimization problem to select a subset of the training data, which maximizes the log-likelihood on a held-out validation set. Next, we propose an iterative online algorithm Glister-Online, which performs data selection iteratively along with the parameter updates and can be applied to any loss-based learning algorithm. We then show that for a rich class of loss functions including cross-entropy, hinge-loss, squared-loss, and logistic-loss, the inner discrete data selection is an instance of (weakly) submodular optimization, and we analyze conditions for which Glister-Online reduces the validation loss and converges. Finally, we propose Glister-Active, an extension to batch active learning, and we empirically demonstrate the performance of Glister on a wide range of tasks including, (a) data selection to reduce training time, (b) robust learning under label noise and imbalance settings, and (c) batch-active learning with several deep and shallow models. We show that our framework improves upon state of the art both in efficiency and accuracy (in cases (a) and (c)) and is more efficient compared to other state-of-the-art robust learning algorithms in case (b).
LIGHTEN: Learning Interactions with Graph and Hierarchical TEmporal Networks for HOI in videos
Dec 17, 2020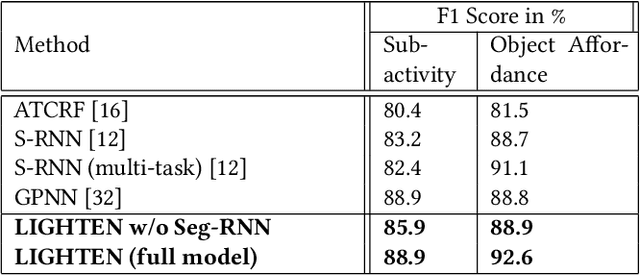
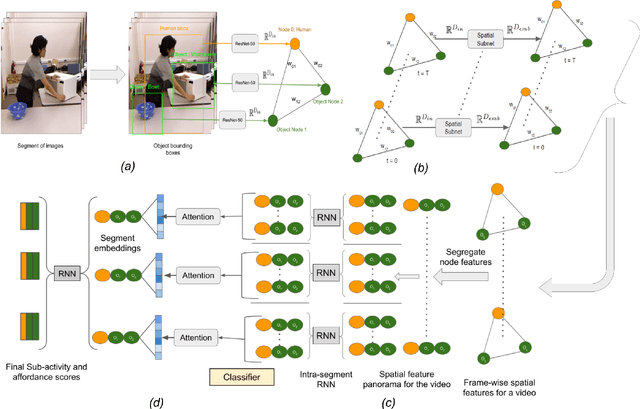

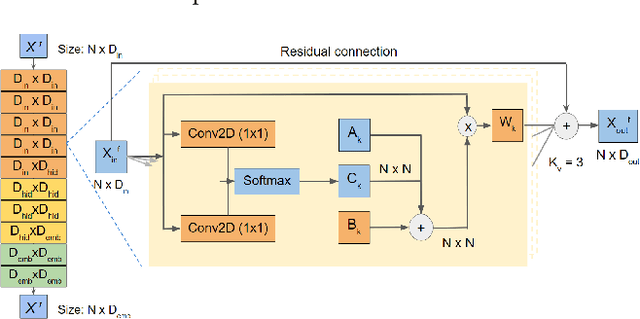
Analyzing the interactions between humans and objects from a video includes identification of the relationships between humans and the objects present in the video. It can be thought of as a specialized version of Visual Relationship Detection, wherein one of the objects must be a human. While traditional methods formulate the problem as inference on a sequence of video segments, we present a hierarchical approach, LIGHTEN, to learn visual features to effectively capture spatio-temporal cues at multiple granularities in a video. Unlike current approaches, LIGHTEN avoids using ground truth data like depth maps or 3D human pose, thus increasing generalization across non-RGBD datasets as well. Furthermore, we achieve the same using only the visual features, instead of the commonly used hand-crafted spatial features. We achieve state-of-the-art results in human-object interaction detection (88.9% and 92.6%) and anticipation tasks of CAD-120 and competitive results on image based HOI detection in V-COCO dataset, setting a new benchmark for visual features based approaches. Code for LIGHTEN is available at https://github.com/praneeth11009/LIGHTEN-Learning-Interactions-with-Graphs-and-Hierarchical-TEmporal-Networks-for-HOI
* 9 pages, 6 figures, ACM Multimedia Conference 2020
A Unified Framework for Generic, Query-Focused, Privacy Preserving and Update Summarization using Submodular Information Measures
Oct 12, 2020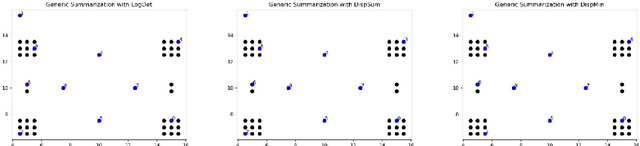
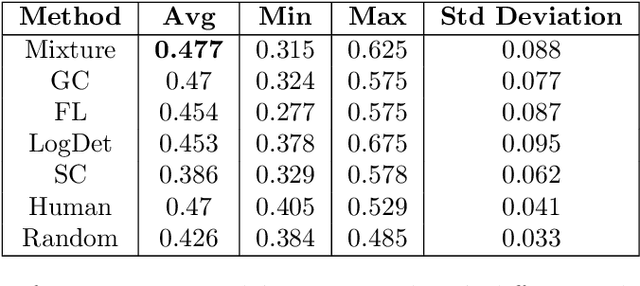
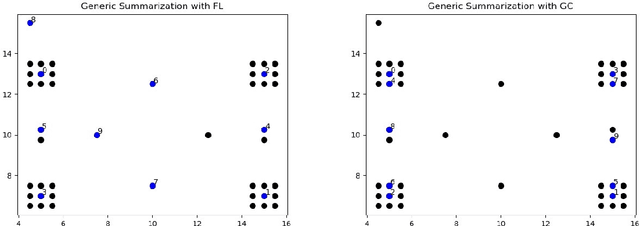
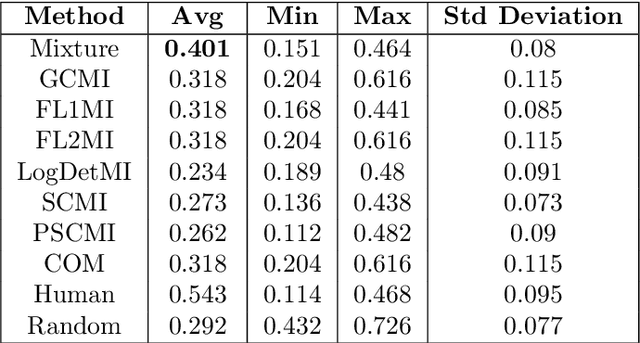
We study submodular information measures as a rich framework for generic, query-focused, privacy sensitive, and update summarization tasks. While past work generally treats these problems differently ({\em e.g.}, different models are often used for generic and query-focused summarization), the submodular information measures allow us to study each of these problems via a unified approach. We first show that several previous query-focused and update summarization techniques have, unknowingly, used various instantiations of the aforesaid submodular information measures, providing evidence for the benefit and naturalness of these models. We then carefully study and demonstrate the modelling capabilities of the proposed functions in different settings and empirically verify our findings on both a synthetic dataset and an existing real-world image collection dataset (that has been extended by adding concept annotations to each image making it suitable for this task) and will be publicly released. We employ a max-margin framework to learn a mixture model built using the proposed instantiations of submodular information measures and demonstrate the effectiveness of our approach. While our experiments are in the context of image summarization, our framework is generic and can be easily extended to other summarization settings (e.g., videos or documents).
Realistic Video Summarization through VISIOCITY: A New Benchmark and Evaluation Framework
Aug 25, 2020
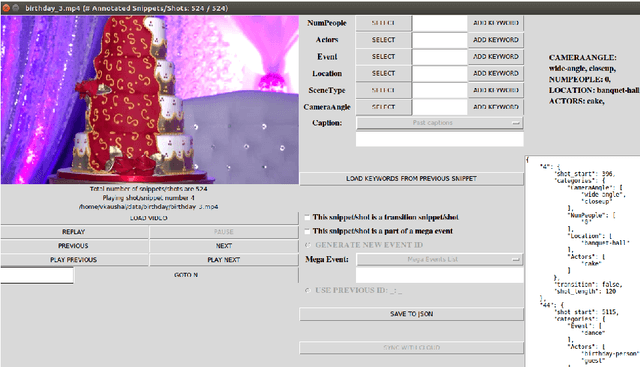
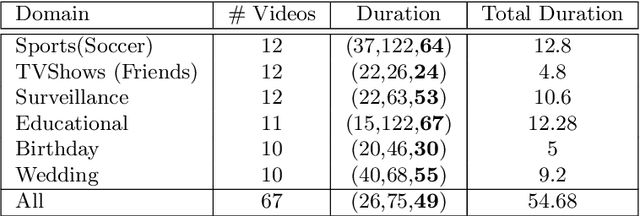
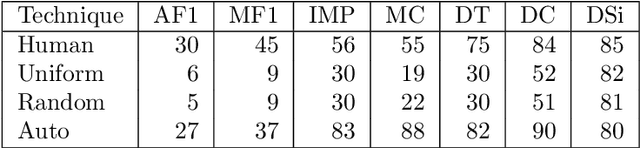
Automatic video summarization is still an unsolved problem due to several challenges. We take steps towards making automatic video summarization more realistic by addressing them. Firstly, the currently available datasets either have very short videos or have few long videos of only a particular type. We introduce a new benchmarking dataset VISIOCITY which comprises of longer videos across six different categories with dense concept annotations capable of supporting different flavors of video summarization and can be used for other vision problems. Secondly, for long videos, human reference summaries are difficult to obtain. We present a novel recipe based on pareto optimality to automatically generate multiple reference summaries from indirect ground truth present in VISIOCITY. We show that these summaries are at par with human summaries. Thirdly, we demonstrate that in the presence of multiple ground truth summaries (due to the highly subjective nature of the task), learning from a single combined ground truth summary using a single loss function is not a good idea. We propose a simple recipe VISIOCITY-SUM to enhance an existing model using a combination of losses and demonstrate that it beats the current state of the art techniques when tested on VISIOCITY. We also show that a single measure to evaluate a summary, as is the current typical practice, falls short. We propose a framework for better quantitative assessment of summary quality which is closer to human judgment than a single measure, say F1. We report the performance of a few representative techniques of video summarization on VISIOCITY assessed using various measures and bring out the limitation of the techniques and/or the assessment mechanism in modeling human judgment and demonstrate the effectiveness of our evaluation framework in doing so.
Data Programming using Semi-Supervision and Subset Selection
Aug 22, 2020
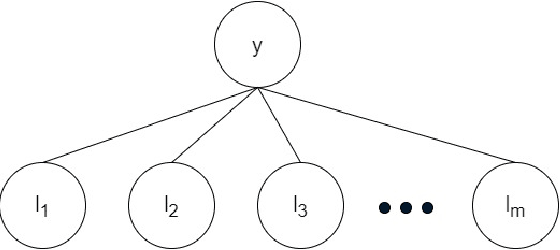
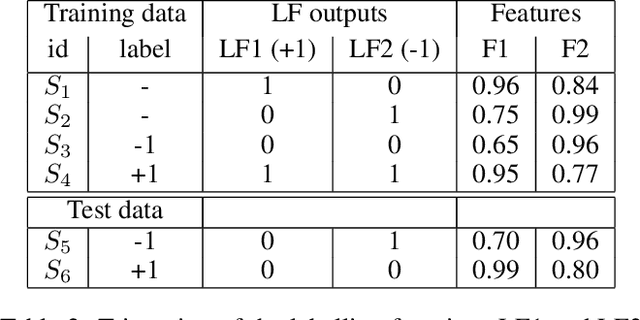
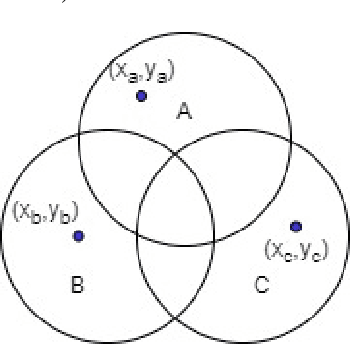
The paradigm of data programming~\cite{bach2019snorkel} has shown a lot of promise in using weak supervision in the form of rules and labelling functions to learn in scenarios where labelled data is not available. Another approach which has shown a lot of promise is that of semi-supervised learning where we augment small amounts of labelled data with a large unlabelled dataset. In this work, we argue that by not using any labelled data, data programming based approaches can yield sub-optimal performance, particularly, in cases when the labelling functions are noisy. The first contribution of this work is to study a framework of joint learning which combines un-supervised consensus from labelling functions with semi-supervised learning and \emph{jointly learns a model} to efficiently use the rules/labelling functions along with semi-supervised loss functions on the feature space. Next, we also study a subset selection approach to \emph{select} the set of examples which can be used as the labelled set. We evaluate our techniques on synthetic data as well as four publicly available datasets and show improvement over state-of-the-art techniques\footnote{Source code of the paper at \url{https://github.com/ayushbits/Semi-Supervised-LFs-Subset-Selection}}.
Data Programming using Continuous and Quality-Guided Labeling Functions
Nov 22, 2019
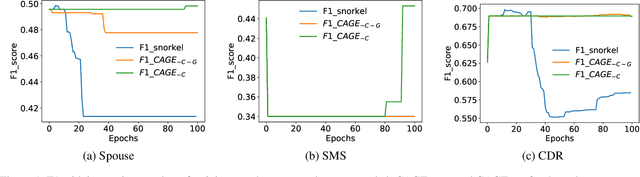


Scarcity of labeled data is a bottleneck for supervised learning models. A paradigm that has evolved for dealing with this problem is data programming. An existing data programming paradigm allows human supervision to be provided as a set of discrete labeling functions (LF) that output possibly noisy labels to input instances and a generative modelfor consolidating the weak labels. We enhance and generalize this paradigm by supporting functions that output a continuous score (instead of a hard label) that noisily correlates with labels. We show across five applications that continuous LFs are more natural to program and lead to improved recall. We also show that accuracy of existing generative models is unstable with respect to initialization, training epochs, and learning rates. We give control to the data programmer to guide the training process by providing intuitive quality guides with each LF. We propose an elegant method of incorporating these guides into the generative model. Our overall method, called CAGE, makes the data programming paradigm more reliable than other tricks based on initialization, sign-penalties, or soft-accuracy constraints.
Question Generation from Paragraphs: A Tale of Two Hierarchical Models
Nov 08, 2019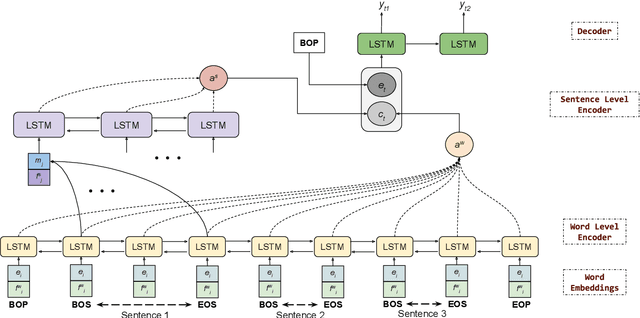
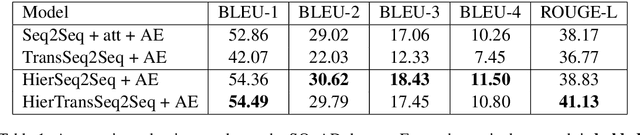
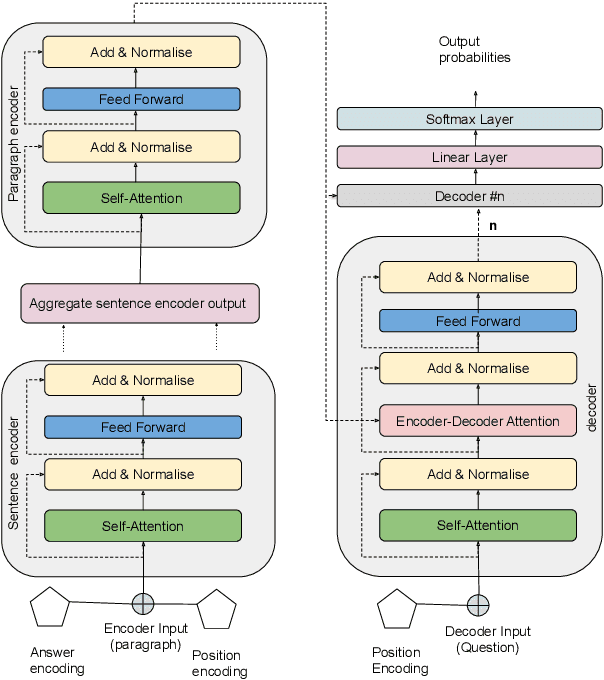

Automatic question generation from paragraphs is an important and challenging problem, particularly due to the long context from paragraphs. In this paper, we propose and study two hierarchical models for the task of question generation from paragraphs. Specifically, we propose (a) a novel hierarchical BiLSTM model with selective attention and (b) a novel hierarchical Transformer architecture, both of which learn hierarchical representations of paragraphs. We model a paragraph in terms of its constituent sentences, and a sentence in terms of its constituent words. While the introduction of the attention mechanism benefits the hierarchical BiLSTM model, the hierarchical Transformer, with its inherent attention and positional encoding mechanisms also performs better than flat transformer model. We conducted empirical evaluation on the widely used SQuAD and MS MARCO datasets using standard metrics. The results demonstrate the overall effectiveness of the hierarchical models over their flat counterparts. Qualitatively, our hierarchical models are able to generate fluent and relevant questions
Multi-Person 3D Human Pose Estimation from Monocular Images
Sep 24, 2019
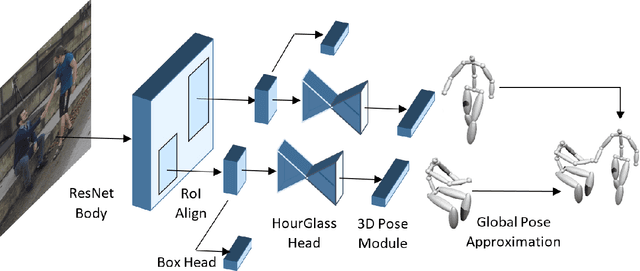

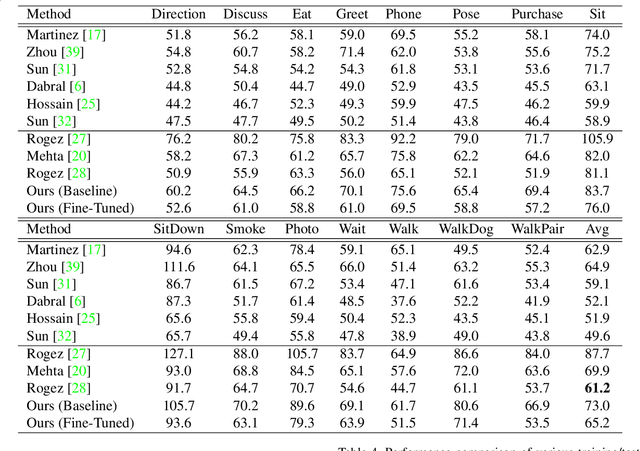
Multi-person 3D human pose estimation from a single image is a challenging problem, especially for in-the-wild settings due to the lack of 3D annotated data. We propose HG-RCNN, a Mask-RCNN based network that also leverages the benefits of the Hourglass architecture for multi-person 3D Human Pose Estimation. A two-staged approach is presented that first estimates the 2D keypoints in every Region of Interest (RoI) and then lifts the estimated keypoints to 3D. Finally, the estimated 3D poses are placed in camera-coordinates using weak-perspective projection assumption and joint optimization of focal length and root translations. The result is a simple and modular network for multi-person 3D human pose estimation that does not require any multi-person 3D pose dataset. Despite its simple formulation, HG-RCNN achieves the state-of-the-art results on MuPoTS-3D while also approximating the 3D pose in the camera-coordinate system.
ParaQG: A System for Generating Questions and Answers from Paragraphs
Sep 04, 2019
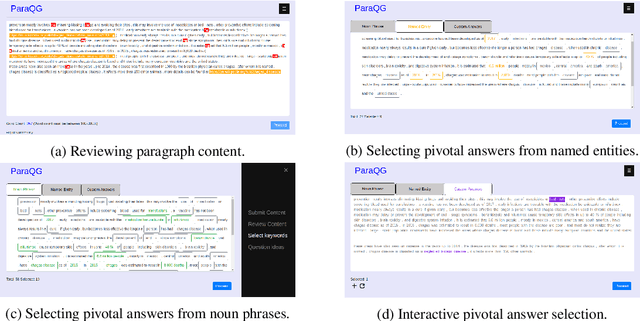
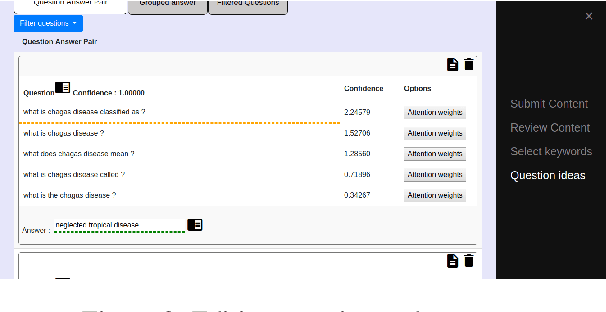
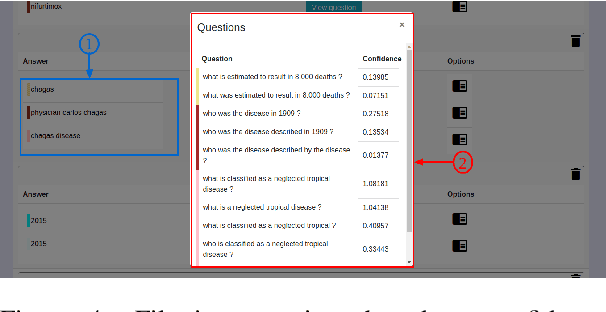
Generating syntactically and semantically valid and relevant questions from paragraphs is useful with many applications. Manual generation is a labour-intensive task, as it requires the reading, parsing and understanding of long passages of text. A number of question generation models based on sequence-to-sequence techniques have recently been proposed. Most of them generate questions from sentences only, and none of them is publicly available as an easy-to-use service. In this paper, we demonstrate ParaQG, a Web-based system for generating questions from sentences and paragraphs. ParaQG incorporates a number of novel functionalities to make the question generation process user-friendly. It provides an interactive interface for a user to select answers with visual insights on generation of questions. It also employs various faceted views to group similar questions as well as filtering techniques to eliminate unanswerable questions