 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterate Until Retrieved: Factual Nugget Optimization for Discoverable Continual Corrections in Agentic RAG
May 25, 2026Agentic retrieval-augmented generation (RAG) systems in complex B2B (business-to-business) settings may often receive free-form response feedback. Rather than generic feedback signals such as style, preference, or overall response quality, we focus on actionable factual corrections. We identify these instances and convert them into compact knowledge-base entries, which we call factual nuggets. We introduce Iterative Nugget Optimization (INO), an index-time optimization method that uses the production agentic RAG as a test harness: it creates an initial nugget, probes it with the triggering query and paraphrases, reflects over failed retrieval and answer traces, and revises the nugget until it is discoverable. We evaluate INO with two production B2B knowledge-assistance agents across multiple companies that use our system: a product support agent that answers questions over company-specific knowledge bases, and a support ticket agent that assists support engineers. INO consistently improves results over baselines in terms of discoverability and usage of factual corrections, in automated and human evaluations.
MuLER: Detailed and Scalable Reference-based Evaluation
May 24, 2023



We propose a novel methodology (namely, MuLER) that transforms any reference-based evaluation metric for text generation, such as machine translation (MT) into a fine-grained analysis tool. Given a system and a metric, MuLER quantifies how much the chosen metric penalizes specific error types (e.g., errors in translating names of locations). MuLER thus enables a detailed error analysis which can lead to targeted improvement efforts for specific phenomena. We perform experiments in both synthetic and naturalistic settings to support MuLER's validity and showcase its usability in MT evaluation, and other tasks, such as summarization. Analyzing all submissions to WMT in 2014-2020, we find consistent trends. For example, nouns and verbs are among the most frequent POS tags. However, they are among the hardest to translate. Performance on most POS tags improves with overall system performance, but a few are not thus correlated (their identity changes from language to language). Preliminary experiments with summarization reveal similar trends.
On Neurons Invariant to Sentence Structural Changes in Neural Machine Translation
Oct 06, 2021
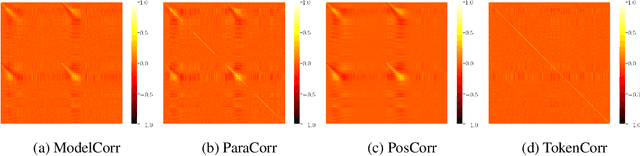

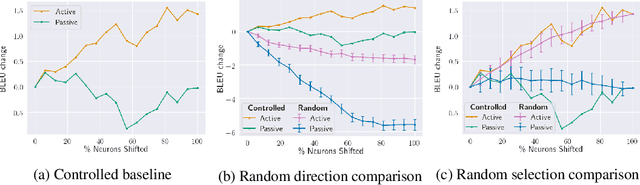
To gain insight into the role neurons play, we study the activation patterns corresponding to meaning-preserving paraphrases (e.g., active-passive). We compile a dataset of controlled syntactic paraphrases in English with their reference German translations and demonstrate our model-agnostic approach with the Transformer translation model. First, we identify neurons that correlate across paraphrases and dissect the observed correlation into possible confounds. Although lower-level components are found as the cause of similar activations, no sentence-level semantics or syntax are detected locally. Later, we manipulate neuron activations to influence translation towards a particular syntactic form. We find that a simple value shift is effective, and more so when many neurons are modified. These suggest that complex syntactic constructions are indeed encoded in the model. We conclude by discussing how to better manipulate it using the correlations we first obtained.