 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Dropout: Deterministic Regularization for Transformer Architectures
Apr 22, 2026Dropout is a widely used regularization technique in deep learning, but its effects are typically realized through stochastic masking rather than explicit optimization objectives. We propose a deterministic formulation that expresses dropout as an additive regularizer directly incorporated into the training loss. The framework derives explicit regularization terms for Transformer architectures, covering attention query, key, value, and feed-forward components with independently controllable strengths. This formulation removes reliance on stochastic perturbations while providing clearer and fine-grained control over regularization strength. Experiments across image classification, temporal action detection, and audio classification show that explicit dropout matches or outperforms conventional implicit methods, with consistent gains when applied to attention and feed-forward network layers. Ablation studies demonstrate stable performance and controllable regularization through regularization coefficients and dropout rates. Overall, explicit dropout offers a practical and interpretable alternative to stochastic regularization while maintaining architectural flexibility across diverse tasks.
Near Lossless Time Series Data Compression Methods using Statistics and Deviation
Sep 30, 2022
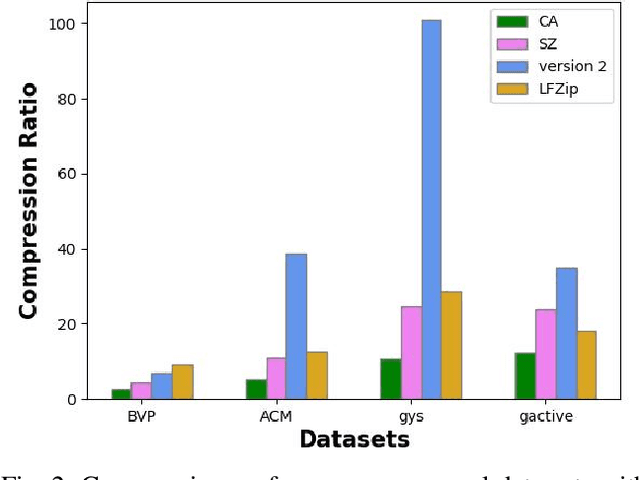

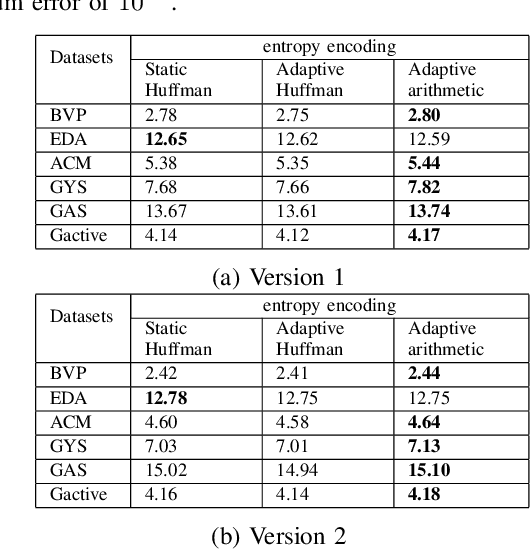
The last two decades have seen tremendous growth in data collections because of the realization of recent technologies, including the internet of things (IoT), E-Health, industrial IoT 4.0, autonomous vehicles, etc. The challenge of data transmission and storage can be handled by utilizing state-of-the-art data compression methods. Recent data compression methods are proposed using deep learning methods, which perform better than conventional methods. However, these methods require a lot of data and resources for training. Furthermore, it is difficult to materialize these deep learning-based solutions on IoT devices due to the resource-constrained nature of IoT devices. In this paper, we propose lightweight data compression methods based on data statistics and deviation. The proposed method performs better than the deep learning method in terms of compression ratio (CR). We simulate and compare the proposed data compression methods for various time series signals, e.g., accelerometer, gas sensor, gyroscope, electrical power consumption, etc. In particular, it is observed that the proposed method achieves 250.8\%, 94.3\%, and 205\% higher CR than the deep learning method for the GYS, Gactive, and ACM datasets, respectively. The code and data are available at https://github.com/vidhi0206/data-compression .