 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Multi Time-scale Constraints in Model-free Deep Reinforcement Learning for Autonomous Driving
Mar 20, 2020
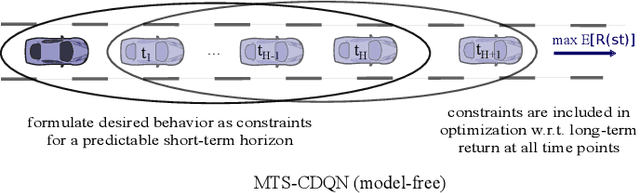
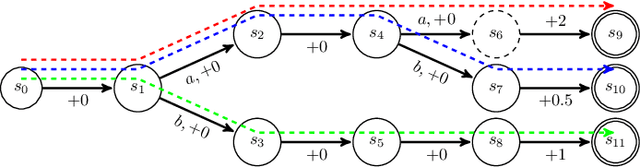
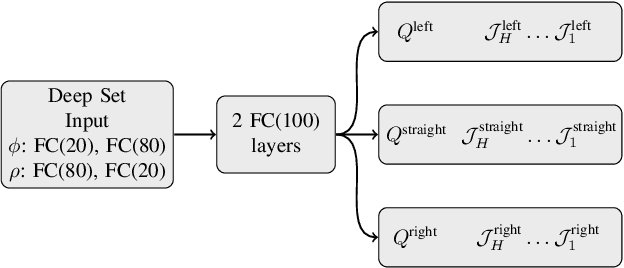
In many real world applications, reinforcement learning agents have to optimize multiple objectives while following certain rules or satisfying a list of constraints. Classical methods based on reward shaping, i.e. a weighted combination of different objectives in the reward signal, or Lagrangian methods, including constraints in the loss function, have no guarantees that the agent satisfies the constraints at all points in time and lack in interpretability. When a discrete policy is extracted from an action-value function, safe actions can be ensured by restricting the action space at maximization, but can lead to sub-optimal solutions among feasible alternatives. In this work, we propose Multi Time-scale Constrained DQN, a novel algorithm restricting the action space directly in the Q-update to learn the optimal Q-function for the constrained MDP and the corresponding safe policy. In addition to single-step constraints referring only to the next action, we introduce a formulation for approximate multi-step constraints under the current target policy based on truncated value-functions to enhance interpretability. We compare our algorithm to reward shaping and Lagrangian methods in the application of high-level decision making in autonomous driving, considering constraints for safety, keeping right and comfort. We train our agent in the open-source simulator SUMO and on the real HighD data set.
Adversarial Skill Networks: Unsupervised Robot Skill Learning from Video
Oct 21, 2019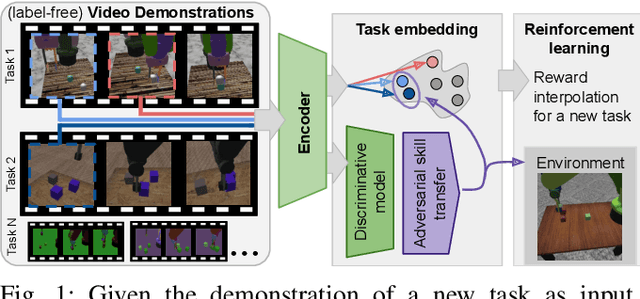
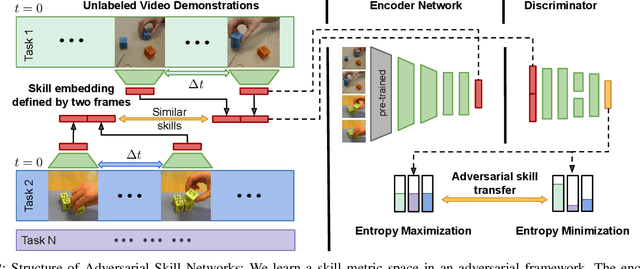

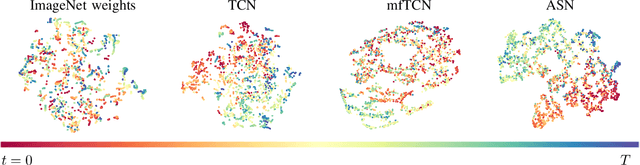
Key challenges for the deployment of reinforcement learning (RL) agents in the real world are the discovery, representation and reuse of skills in the absence of a reward function. To this end, we propose a novel approach to learn a task-agnostic skill embedding space from unlabeled multi-view videos. Our method learns a general skill embedding independently from the task context by using an adversarial loss. We combine a metric learning loss, which utilizes temporal video coherence to learn a state representation, with an entropy regularized adversarial skill-transfer loss. The metric learning loss learns a disentangled representation by attracting simultaneous viewpoints of the same observations and repelling visually similar frames from temporal neighbors. The adversarial skill-transfer loss enhances re-usability of learned skill embeddings over multiple task domains. We show that the learned embedding enables training of continuous control policies to solve novel tasks that require the interpolation of previously seen skills. Our extensive evaluation with both simulation and real world data demonstrates the effectiveness of our method in learning transferable skills from unlabeled interaction videos and composing them for new tasks.
Dynamic Interaction-Aware Scene Understanding for Reinforcement Learning in Autonomous Driving
Sep 30, 2019
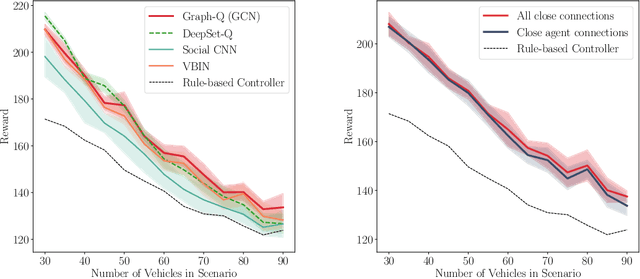


The common pipeline in autonomous driving systems is highly modular and includes a perception component which extracts lists of surrounding objects and passes these lists to a high-level decision component. In this case, leveraging the benefits of deep reinforcement learning for high-level decision making requires special architectures to deal with multiple variable-length sequences of different object types, such as vehicles, lanes or traffic signs. At the same time, the architecture has to be able to cover interactions between traffic participants in order to find the optimal action to be taken. In this work, we propose the novel Deep Scenes architecture, that can learn complex interaction-aware scene representations based on extensions of either 1) Deep Sets or 2) Graph Convolutional Networks. We present the Graph-Q and DeepScene-Q off-policy reinforcement learning algorithms, both outperforming state-of-the-art methods in evaluations with the publicly available traffic simulator SUMO.
Off-policy Multi-step Q-learning
Sep 30, 2019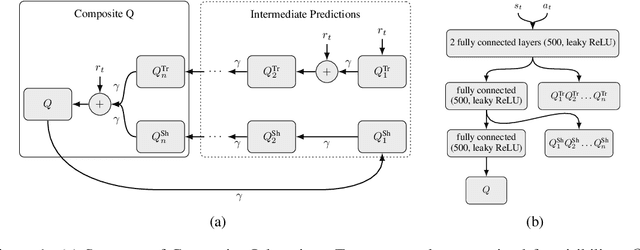

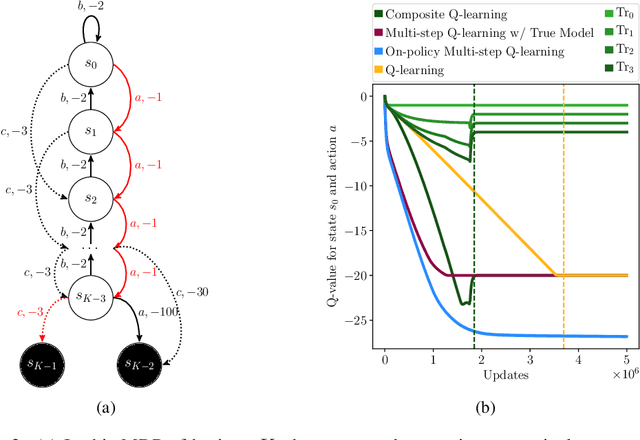
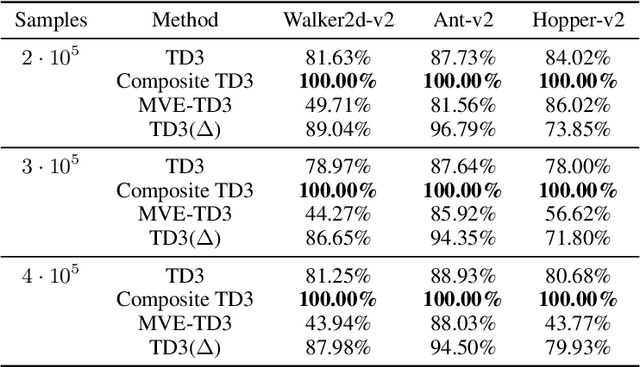
In the past few years, off-policy reinforcement learning methods have shown promising results in their application for robot control. Deep Q-learning, however, still suffers from poor data-efficiency which is limiting with regard to real-world applications. We follow the idea of multi-step TD-learning to enhance data-efficiency while remaining off-policy by proposing two novel Temporal-Difference formulations: (1) Truncated Q-functions which represent the return for the first n steps of a policy rollout and (2) Shifted Q-functions, acting as the farsighted return after this truncated rollout. We prove that the combination of these short- and long-term predictions is a representation of the full return, leading to the Composite Q-learning algorithm. We show the efficacy of Composite Q-learning in the tabular case and compare our approach in the function-approximation setting with TD3, Model-based Value Expansion and TD3(Delta), which we introduce as an off-policy variant of TD(Delta). We show on three simulated robot tasks that Composite TD3 outperforms TD3 as well as state-of-the-art off-policy multi-step approaches in terms of data-efficiency.
Dynamic Input for Deep Reinforcement Learning in Autonomous Driving
Jul 25, 2019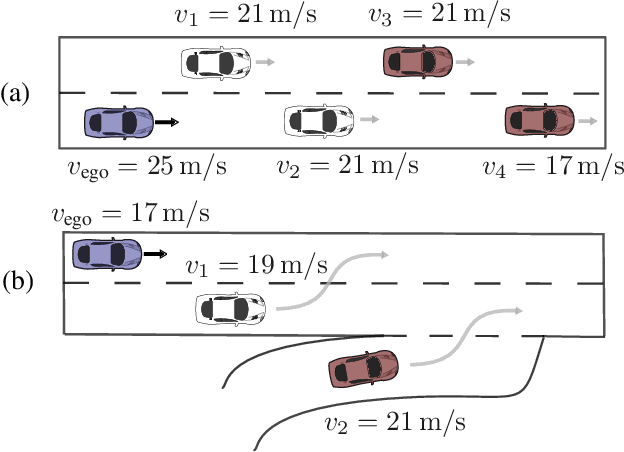
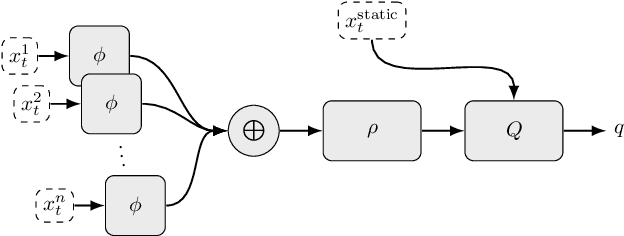
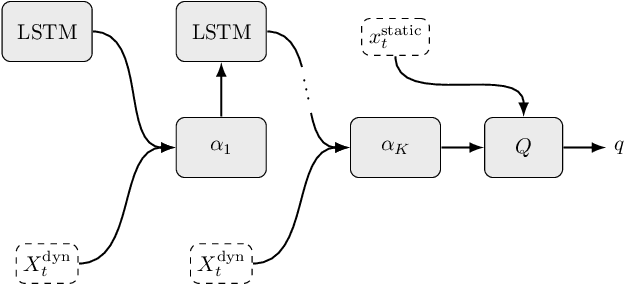

In many real-world decision making problems, reaching an optimal decision requires taking into account a variable number of objects around the agent. Autonomous driving is a domain in which this is especially relevant, since the number of cars surrounding the agent varies considerably over time and affects the optimal action to be taken. Classical methods that process object lists can deal with this requirement. However, to take advantage of recent high-performing methods based on deep reinforcement learning in modular pipelines, special architectures are necessary. For these, a number of options exist, but a thorough comparison of the different possibilities is missing. In this paper, we elaborate limitations of fully-connected neural networks and other established approaches like convolutional and recurrent neural networks in the context of reinforcement learning problems that have to deal with variable sized inputs. We employ the structure of Deep Sets in off-policy reinforcement learning for high-level decision making, highlight their capabilities to alleviate these limitations, and show that Deep Sets not only yield the best overall performance but also offer better generalization to unseen situations than the other approaches.