 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sea of Words: An In-Depth Analysis of Anchors for Text Data
May 27, 2022

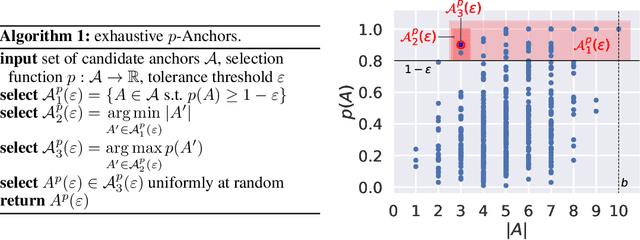
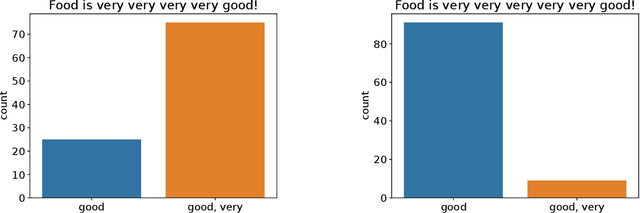
Anchors [Ribeiro et al. (2018)] is a post-hoc, rule-based interpretability method. For text data, it proposes to explain a decision by highlighting a small set of words (an anchor) such that the model to explain has similar outputs when they are present in a document. In this paper, we present the first theoretical analysis of Anchors, considering that the search for the best anchor is exhaustive. We leverage this analysis to gain insights on the behavior of Anchors on simple models, including elementary if-then rules and linear classifiers.
SMACE: A New Method for the Interpretability of Composite Decision Systems
Nov 16, 2021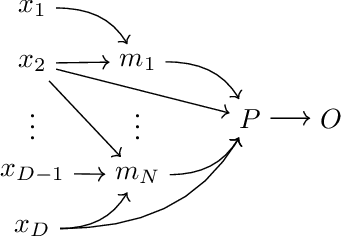
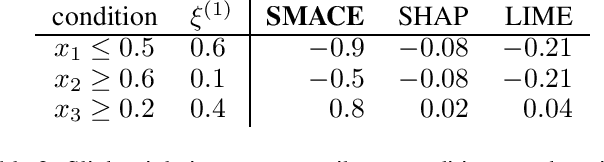
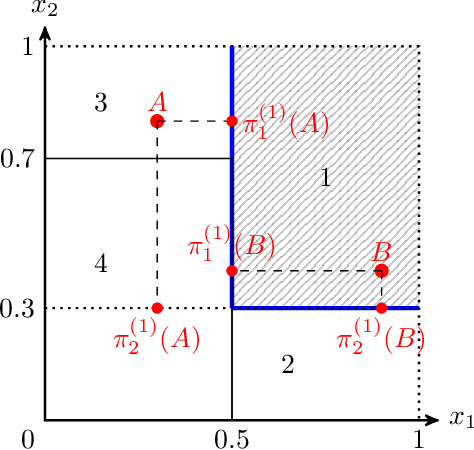
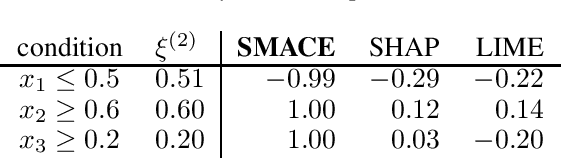
Interpretability is a pressing issue for decision systems. Many post hoc methods have been proposed to explain the predictions of any machine learning model. However, business processes and decision systems are rarely centered around a single, standalone model. These systems combine multiple models that produce key predictions, and then apply decision rules to generate the final decision. To explain such decision, we present SMACE, Semi-Model-Agnostic Contextual Explainer, a novel interpretability method that combines a geometric approach for decision rules with existing post hoc solutions for machine learning models to generate an intuitive feature ranking tailored to the end user. We show that established model-agnostic approaches produce poor results in this framework.
Knowledge-driven Active Learning
Oct 15, 2021


In the last few years, Deep Learning models have become increasingly popular. However, their deployment is still precluded in those contexts where the amount of supervised data is limited and manual labelling expensive. Active learning strategies aim at solving this problem by requiring supervision only on few unlabelled samples, which improve the most model performances after adding them to the training set. Most strategies are based on uncertain sample selection, and even often restricted to samples lying close to the decision boundary. Here we propose a very different approach, taking into consideration domain knowledge. Indeed, in the case of multi-label classification, the relationships among classes offer a way to spot incoherent predictions, i.e., predictions where the model may most likely need supervision. We have developed a framework where first-order-logic knowledge is converted into constraints and their violation is checked as a natural guide for sample selection. We empirically demonstrate that knowledge-driven strategy outperforms standard strategies, particularly on those datasets where domain knowledge is complete. Furthermore, we show how the proposed approach enables discovering data distributions lying far from training data. Finally, the proposed knowledge-driven strategy can be also easily used in object-detection problems where standard uncertainty-based techniques are difficult to apply.
Active Speaker Detection as a Multi-Objective Optimization with Uncertainty-based Multimodal Fusion
Jun 07, 2021
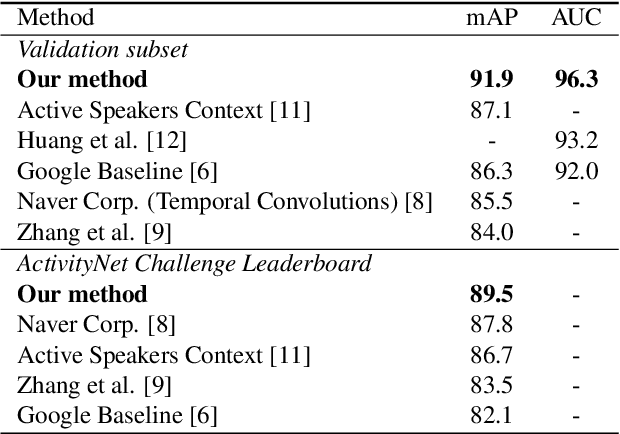
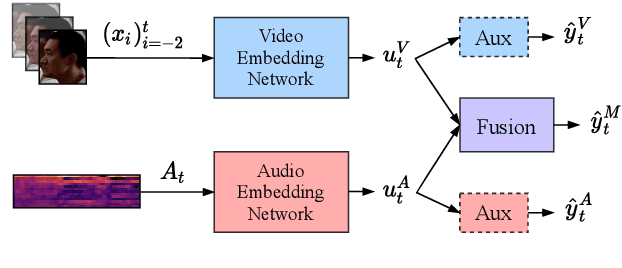
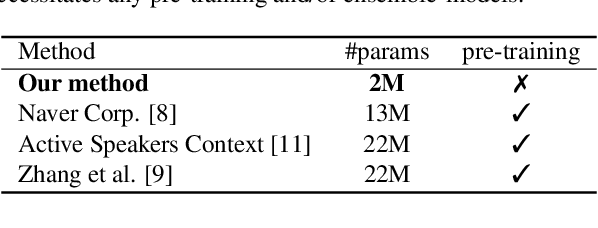
It is now well established from a variety of studies that there is a significant benefit from combining video and audio data in detecting active speakers. However, either of the modalities can potentially mislead audiovisual fusion by inducing unreliable or deceptive information. This paper outlines active speaker detection as a multi-objective learning problem to leverage best of each modalities using a novel self-attention, uncertainty-based multimodal fusion scheme. Results obtained show that the proposed multi-objective learning architecture outperforms traditional approaches in improving both mAP and AUC scores. We further demonstrate that our fusion strategy surpasses, in active speaker detection, other modality fusion methods reported in various disciplines. We finally show that the proposed method significantly improves the state-of-the-art on the AVA-ActiveSpeaker dataset.
Revisiting Deep Architectures for Head Motion Prediction in 360° Videos
Nov 26, 2019
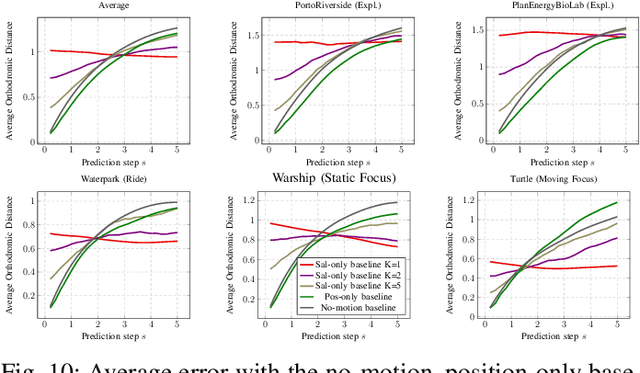
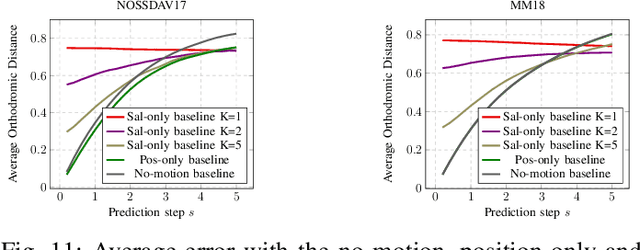
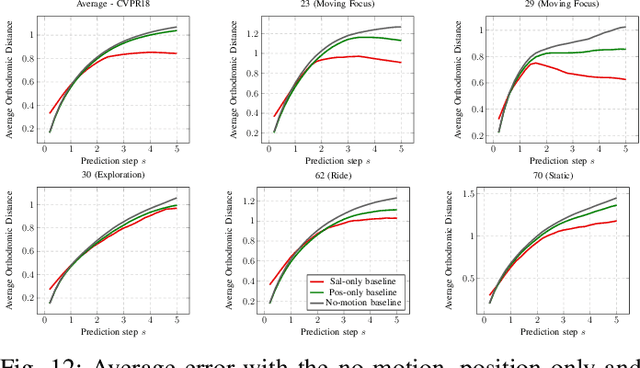
Head motion prediction is an important problem with 360\degree\ videos, in particular to inform the streaming decisions. Various methods tackling this problem with deep neural networks have been proposed recently. In this article we first show the startling result that all such existing methods, which attempt to benefit both from the history of past positions and knowledge of the video content, perform worse than a simple no-motion baseline. We then propose an LSTM-based architecture which processes the positional information only. It is able to establish state-of-the-art performance and we consider it our position-only baseline. Through a thorough root cause analysis, we first show that the content can indeed inform the head position prediction for horizons longer than 2 to 3s, the trajectory inertia being predominant earlier. We also identify that a sequence-to-sequence auto-regressive framework is crucial to improve the prediction accuracy over longer prediction windows, and that a dedicated recurrent network handling the time series of positions is necessary to reach the performance of the position-only baseline in the early prediction steps. This allows to make the most of the positional information and ground-truth saliency. Finally we show how the level of noise in the estimated saliency impacts the architecture's performance, and we propose a new architecture establishing state-of-the-art performance with estimated saliency, supporting its assets with an ablation study.
Adaptive Bayesian Linear Regression for Automated Machine Learning
Apr 18, 2019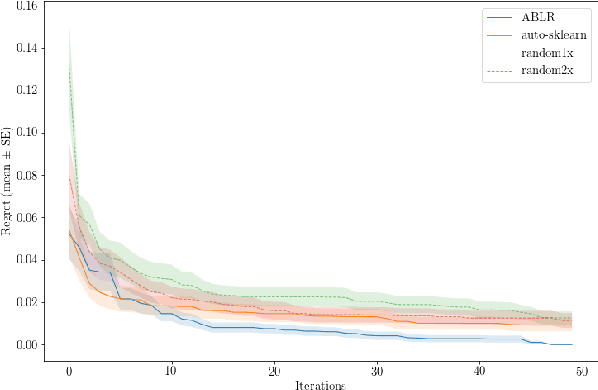
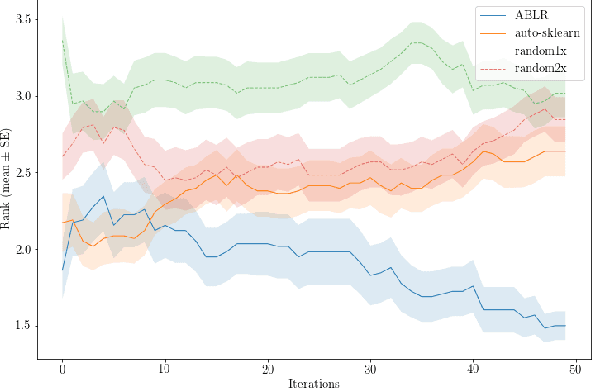
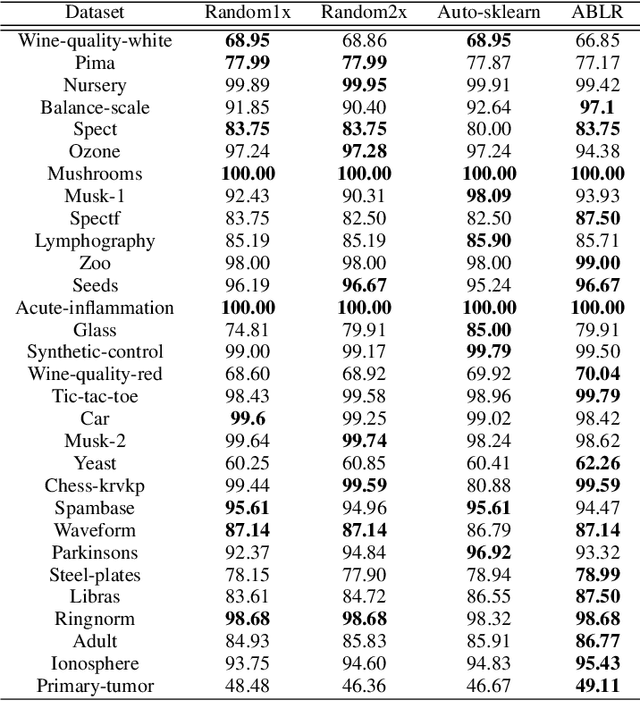
To solve a machine learning problem, one typically needs to perform data preprocessing, modeling, and hyperparameter tuning, which is known as model selection and hyperparameter optimization.The goal of automated machine learning (AutoML) is to design methods that can automatically perform model selection and hyperparameter optimization without human interventions for a given dataset. In this paper, we propose a meta-learning method that can search for a high-performance machine learning pipeline from the predefined set of candidate pipelines for supervised classification datasets in an efficient way by leveraging meta-data collected from previous experiments. More specifically, our method combines an adaptive Bayesian regression model with a neural network basis function and the acquisition function from Bayesian optimization. The adaptive Bayesian regression model is able to capture knowledge from previous meta-data and thus make predictions of the performances of machine learning pipelines on a new dataset. The acquisition function is then used to guide the search of possible pipelines based on the predictions.The experiments demonstrate that our approach can quickly identify high-performance pipelines for a range of test datasets and outperforms the baseline methods.
Adversarial Active Learning for Deep Networks: a Margin Based Approach
Feb 27, 2018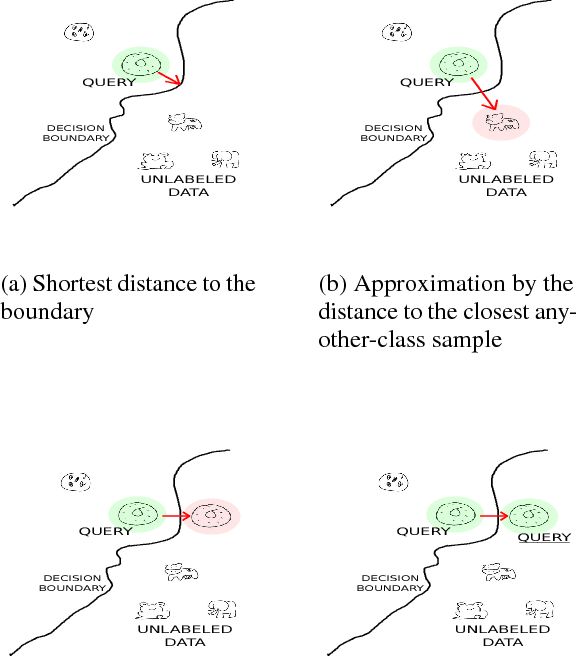
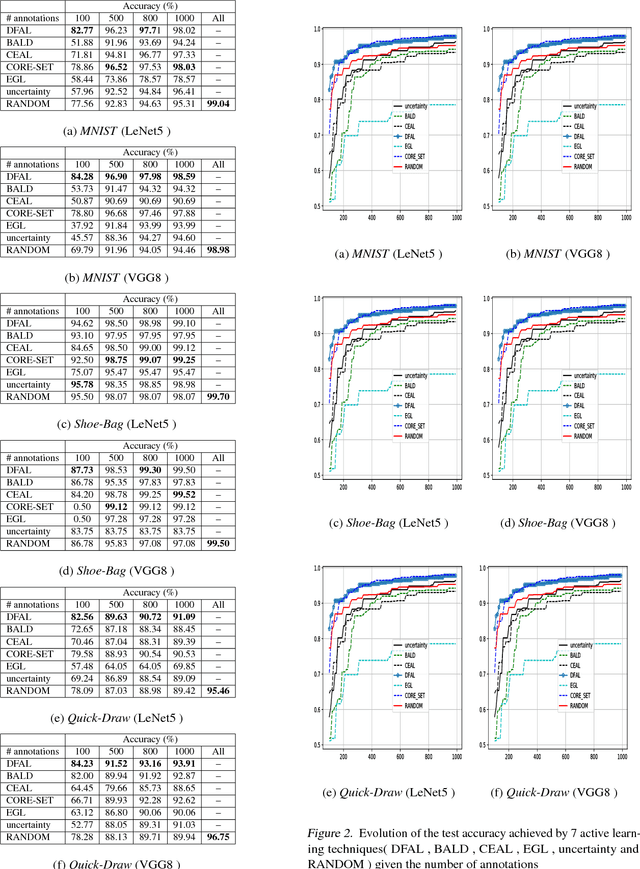
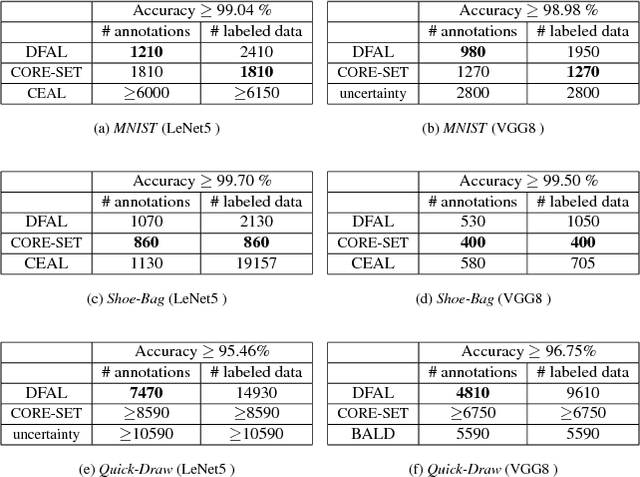

We propose a new active learning strategy designed for deep neural networks. The goal is to minimize the number of data annotation queried from an oracle during training. Previous active learning strategies scalable for deep networks were mostly based on uncertain sample selection. In this work, we focus on examples lying close to the decision boundary. Based on theoretical works on margin theory for active learning, we know that such examples may help to considerably decrease the number of annotations. While measuring the exact distance to the decision boundaries is intractable, we propose to rely on adversarial examples. We do not consider anymore them as a threat instead we exploit the information they provide on the distribution of the input space in order to approximate the distance to decision boundaries. We demonstrate empirically that adversarial active queries yield faster convergence of CNNs trained on MNIST, the Shoe-Bag and the Quick-Draw datasets.
QBDC: Query by dropout committee for training deep supervised architecture
Nov 26, 2015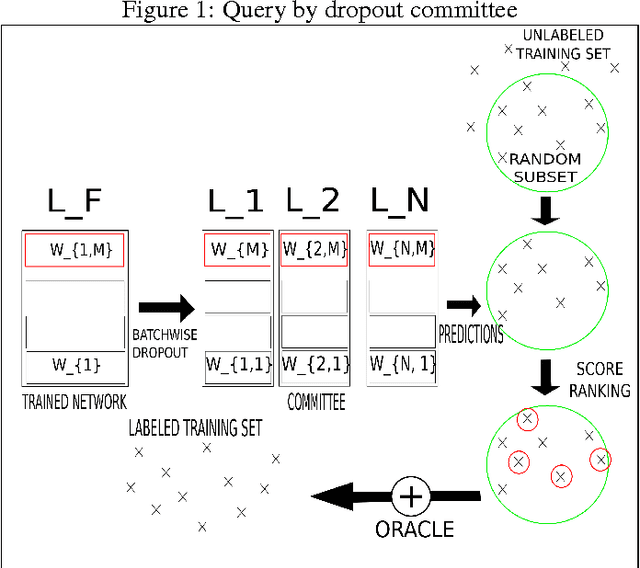

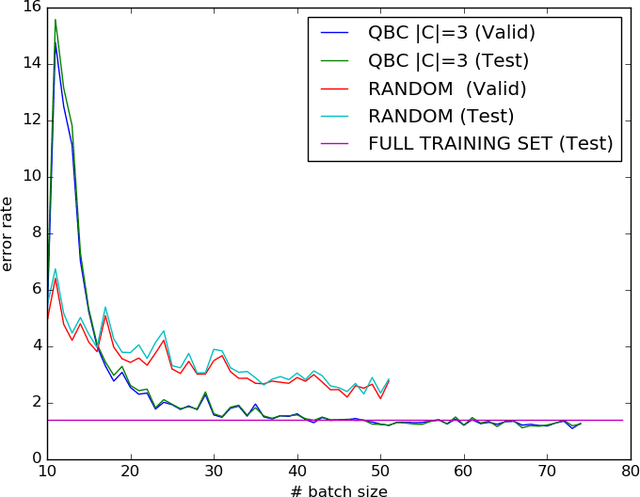

While the current trend is to increase the depth of neural networks to increase their performance, the size of their training database has to grow accordingly. We notice an emergence of tremendous databases, although providing labels to build a training set still remains a very expensive task. We tackle the problem of selecting the samples to be labelled in an online fashion. In this paper, we present an active learning strategy based on query by committee and dropout technique to train a Convolutional Neural Network (CNN). We derive a commmittee of partial CNNs resulting from batchwise dropout runs on the initial CNN. We evaluate our active learning strategy for CNN on MNIST benchmark, showing in particular that selecting less than 30 % from the annotated database is enough to get similar error rate as using the full training set on MNIST. We also studied the robustness of our method against adversarial examples.
Assessment of algorithms for mitosis detection in breast cancer histopathology images
Nov 21, 2014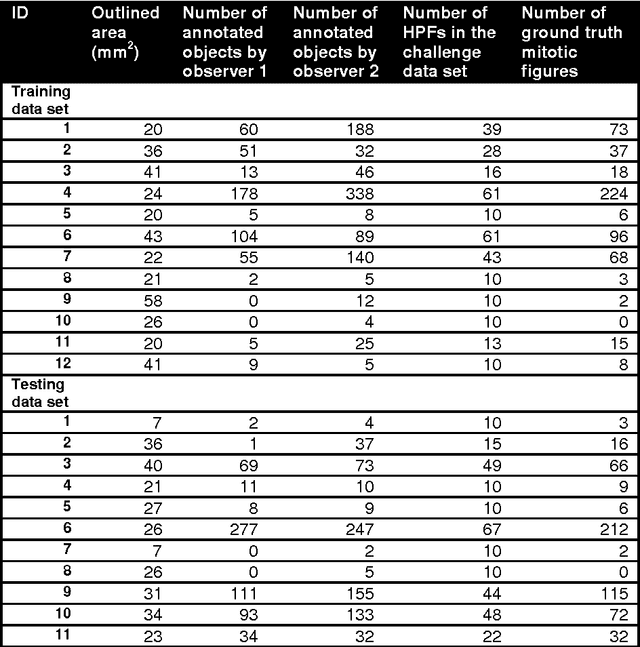

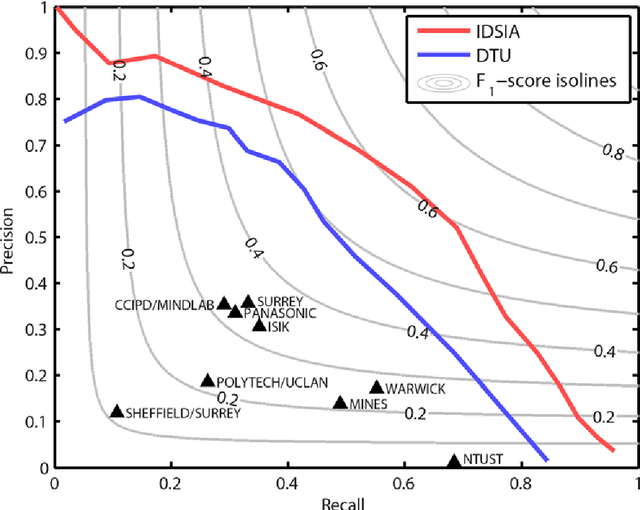
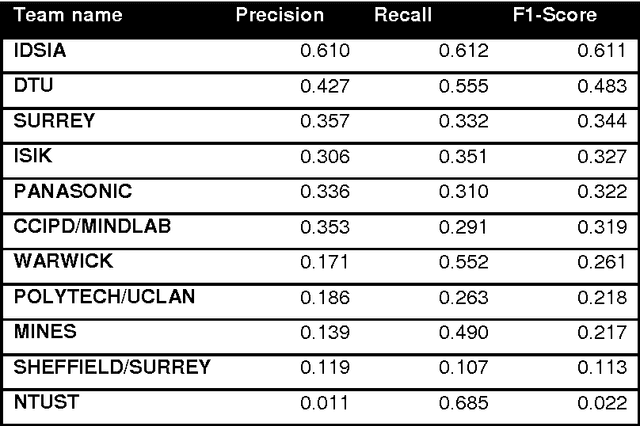
The proliferative activity of breast tumors, which is routinely estimated by counting of mitotic figures in hematoxylin and eosin stained histology sections, is considered to be one of the most important prognostic markers. However, mitosis counting is laborious, subjective and may suffer from low inter-observer agreement. With the wider acceptance of whole slide images in pathology labs, automatic image analysis has been proposed as a potential solution for these issues. In this paper, the results from the Assessment of Mitosis Detection Algorithms 2013 (AMIDA13) challenge are described. The challenge was based on a data set consisting of 12 training and 11 testing subjects, with more than one thousand annotated mitotic figures by multiple observers. Short descriptions and results from the evaluation of eleven methods are presented. The top performing method has an error rate that is comparable to the inter-observer agreement among pathologists.