 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic detection of surgical site infections from a clinical data warehouse
Sep 16, 2019
Reducing the incidence of surgical site infections (SSIs) is one of the objectives of the French nosocomial infection control program. Manual monitoring of SSIs is carried out each year by the hospital hygiene team and surgeons at the University Hospital of Bordeaux. Our goal was to develop an automatic detection algorithm based on hospital information system data. Three years (2015, 2016 and 2017) of manual spine surgery monitoring have been used as a gold standard to extract features and train machine learning algorithms. The dataset contained 22 SSIs out of 2133 spine surgeries. Two different approaches were compared. The first used several data sources and achieved the best performance but is difficult to generalize to other institutions. The second was based on free text only with semiautomatic extraction of discriminant terms. The algorithms managed to identify all the SSIs with 20 and 26 false positives respectively on the dataset. Another evaluation is underway. These results are encouraging for the development of semi-automated surveillance methods.
* in French
Neural Language Model for Automated Classification of Electronic Medical Records at the Emergency Room. The Significant Benefit of Unsupervised Generative Pre-training
Sep 13, 2019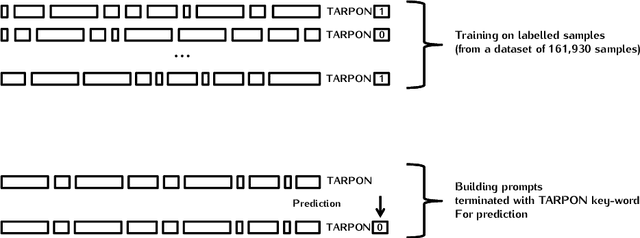
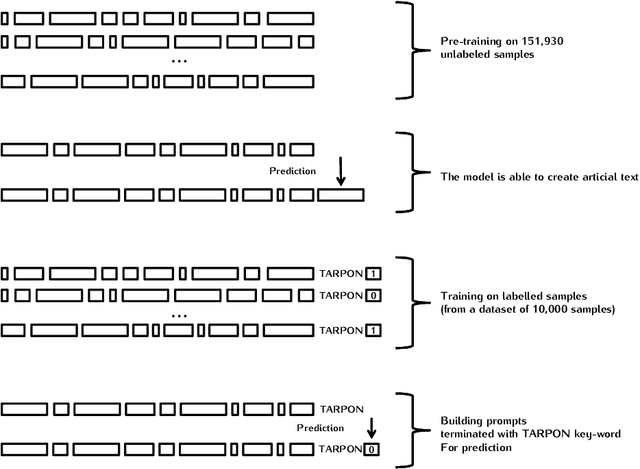
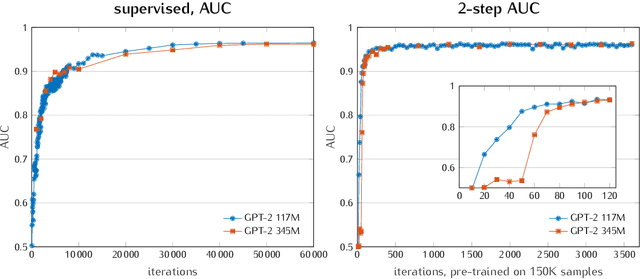
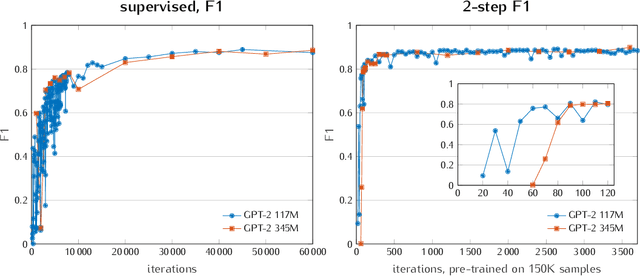
In order to build a national injury surveillance system based on emergency room (ER) visits we are developing a coding system to classify their causes from clinical notes content. Supervised learning techniques have shown good results in this area but require to manually build a large learning annotated dataset. New levels of performance have been recently achieved in neural language models (NLM) with the use of models based on the Transformer architecture with an unsupervised generative pre-training step. Our hypothesis is that methods involving a generative self-supervised pre-training step significantly reduce the number of annotated samples required for supervised fine-tuning. In this case study, we assessed whether we could predict from free text clinical notes whether a visit was the consequence of a traumatic or a non-traumatic event. We compared two strategies: Strategy A consisted in training the GPT-2 NLM on the full 161 930 samples dataset with all labels (trauma/non-trauma). In Strategy B, we split the training dataset in two parts, a large one of 151 930 samples without any label for the self-supervised pre-training phase and a smaller one (up to 10 000 samples) for the supervised fine-tuning with labels. While strategy A needed to process 40 000 samples to achieve good performance (AUC>0.95), strategy B needed only 500 samples, a gain of 80. Moreover, an AUC of 0.93 was measured with only 30 labeled samples processed 3 times (3 epochs). To conclude, it is possible to adapt a multi-purpose NLM model such as the GPT-2 to create a powerful tool for classification of free-text notes with the need of a very small number of labeled samples. Only two modalities (trauma/non-trauma) were predicted for this case study but the same method can be applied for multimodal classification tasks such as diagnosis/disease terminologies.
IAM at CLEF eHealth 2018: Concept Annotation and Coding in French Death Certificates
Jul 10, 2018



In this paper, we describe the approach and results for our participation in the task 1 (multilingual information extraction) of the CLEF eHealth 2018 challenge. We addressed the task of automatically assigning ICD-10 codes to French death certificates. We used a dictionary-based approach using materials provided by the task organizers. The terms of the ICD-10 terminology were normalized, tokenized and stored in a tree data structure. The Levenshtein distance was used to detect typos. Frequent abbreviations were detected by manually creating a small set of them. Our system achieved an F-score of 0.786 (precision: 0.794, recall: 0.779). These scores were substantially higher than the average score of the systems that participated in the challenge.