 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentLTV: An Agent-Based Unified Search-and-Evolution Framework for Automated Lifetime Value Prediction
Feb 25, 2026Lifetime Value (LTV) prediction is critical in advertising, recommender systems, and e-commerce. In practice, LTV data patterns vary across decision scenarios. As a result, practitioners often build complex, scenario-specific pipelines and iterate over feature processing, objective design, and tuning. This process is expensive and hard to transfer. We propose AgentLTV, an agent-based unified search-and-evolution framework for automated LTV modeling. AgentLTV treats each candidate solution as an {executable pipeline program}. LLM-driven agents generate code, run and repair pipelines, and analyze execution feedback. Two decision agents coordinate a two-stage search. The Monte Carlo Tree Search (MCTS) stage explores a broad space of modeling choices under a fixed budget, guided by the Polynomial Upper Confidence bounds for Trees criterion and a Pareto-aware multi-metric value function. The Evolutionary Algorithm (EA) stage refines the best MCTS program via island-based evolution with crossover, mutation, and migration. Experiments on a large-scale proprietary dataset and a public benchmark show that AgentLTV consistently discovers strong models across ranking and error metrics. Online bucket-level analysis further indicates improved ranking consistency and value calibration, especially for high-value and negative-LTV segments. We summarize practitioner-oriented takeaways: use MCTS for rapid adaptation to new data patterns, use EA for stable refinement, and validate deployment readiness with bucket-level ranking and calibration diagnostics. The proposed AgentLTV has been successfully deployed online.
Intelligent Design 4.0: Paradigm Evolution Toward the Agentic AI Era
Jun 11, 2025Research and practice in Intelligent Design (ID) have significantly enhanced engineering innovation, efficiency, quality, and productivity over recent decades, fundamentally reshaping how engineering designers think, behave, and interact with design processes. The recent emergence of Foundation Models (FMs), particularly Large Language Models (LLMs), has demonstrated general knowledge-based reasoning capabilities, and open new paths and avenues for further transformation in engineering design. In this context, this paper introduces Intelligent Design 4.0 (ID 4.0) as an emerging paradigm empowered by agentic AI systems. We review the historical evolution of ID across four distinct stages: rule-based expert systems, task-specific machine learning models, large-scale foundation AI models, and the recent emerging paradigm of multi-agent collaboration. We propose a conceptual framework for ID 4.0 and discuss its potential to support end-to-end automation of engineering design processes through coordinated, autonomous multi-agent-based systems. Furthermore, we discuss future perspectives to enhance and fully realize ID 4.0's potential, including more complex design scenarios, more practical design implementations, novel agent coordination mechanisms, and autonomous design goal-setting with better human value alignment. In sum, these insights lay a foundation for advancing Intelligent Design toward greater adaptivity, autonomy, and effectiveness in addressing increasingly complex design challenges.
Product Segmentation Newsvendor Problems: A Robust Learning Approach
Jul 08, 2022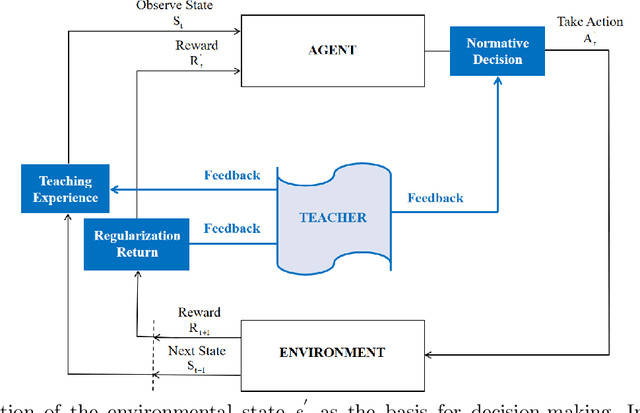
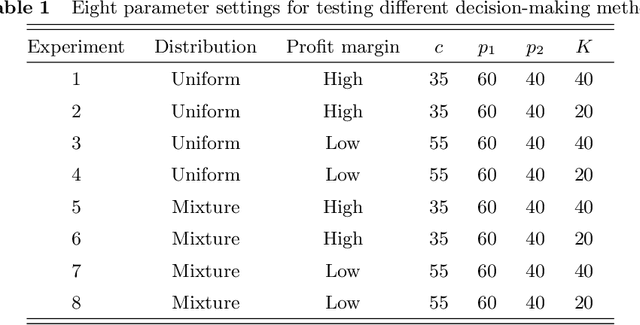
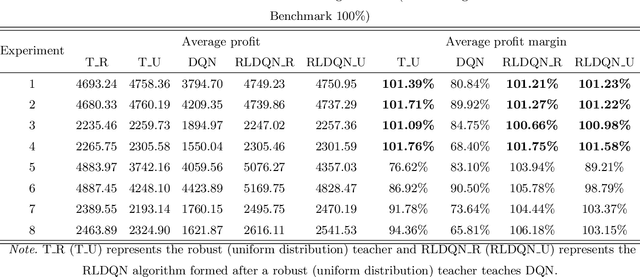
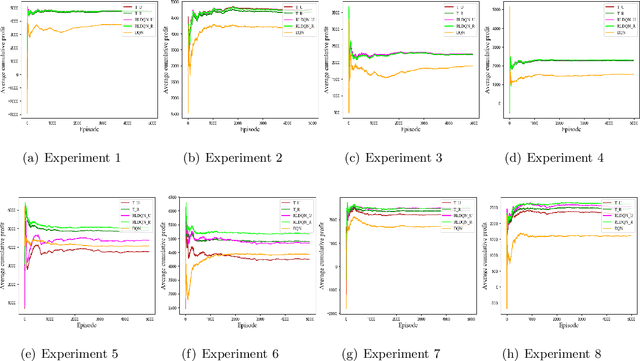
We propose and analyze a product segmentation newsvendor problem, which generalizes the phenomenon of segmentation sales of a class of perishable items. The product segmentation newsvendor problem is a new variant of the newsvendor problem, reflecting that sellers maximize profits by determining the inventory of the whole item in the context of uncertain demand for sub-items. We derive the closed-form robust ordering decision by assuming that the means and covariance matrix of stochastic demand are available but not the distributions. However, robust approaches that always trade-off in the worst-case demand scenario face a concern in solution conservatism; thus, the traditional robust schemes offer unsatisfactory. In this paper, we integrate robust and deep reinforcement learning (DRL) techniques and propose a new paradigm termed robust learning to increase the attractiveness of robust policies. Notably, we take the robust decision as human domain knowledge and implement it into the training process of DRL by designing a full-process human-machine collaborative mechanism of teaching experience, normative decision, and regularization return. Simulation results confirm that our approach effectively improves robust performance and can generalize to various problems that require robust but less conservative solutions. Simultaneously, fewer training episodes, increased training stability, and interpretability of behavior may have the opportunity to facilitate the deployment of DRL algorithms in operational practice. Furthermore, the successful attempt of RLDQN to solve the 1000-dimensional demand scenarios reveals that the algorithm provides a path to solve complex operational problems through human-machine collaboration and may have potential significance for solving other complex operational management problems.