 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion Robustness of CLIP for Military Vehicle Classification
Aug 28, 2025Vision-language models (VLMs) like CLIP enable zero-shot classification by aligning images and text in a shared embedding space, offering advantages for defense applications with scarce labeled data. However, CLIP's robustness in challenging military environments, with partial occlusion and degraded signal-to-noise ratio (SNR), remains underexplored. We investigate CLIP variants' robustness to occlusion using a custom dataset of 18 military vehicle classes and evaluate using Normalized Area Under the Curve (NAUC) across occlusion percentages. Four key insights emerge: (1) Transformer-based CLIP models consistently outperform CNNs, (2) fine-grained, dispersed occlusions degrade performance more than larger contiguous occlusions, (3) despite improved accuracy, performance of linear-probed models sharply drops at around 35% occlusion, (4) by finetuning the model's backbone, this performance drop occurs at more than 60% occlusion. These results underscore the importance of occlusion-specific augmentations during training and the need for further exploration into patch-level sensitivity and architectural resilience for real-world deployment of CLIP.
Textual Inversion for Efficient Adaptation of Open-Vocabulary Object Detectors Without Forgetting
Aug 07, 2025Recent progress in large pre-trained vision language models (VLMs) has reached state-of-the-art performance on several object detection benchmarks and boasts strong zero-shot capabilities, but for optimal performance on specific targets some form of finetuning is still necessary. While the initial VLM weights allow for great few-shot transfer learning, this usually involves the loss of the original natural language querying and zero-shot capabilities. Inspired by the success of Textual Inversion (TI) in personalizing text-to-image diffusion models, we propose a similar formulation for open-vocabulary object detection. TI allows extending the VLM vocabulary by learning new or improving existing tokens to accurately detect novel or fine-grained objects from as little as three examples. The learned tokens are completely compatible with the original VLM weights while keeping them frozen, retaining the original model's benchmark performance, and leveraging its existing capabilities such as zero-shot domain transfer (e.g., detecting a sketch of an object after training only on real photos). The storage and gradient calculations are limited to the token embedding dimension, requiring significantly less compute than full-model fine-tuning. We evaluated whether the method matches or outperforms the baseline methods that suffer from forgetting in a wide variety of quantitative and qualitative experiments.
Open-World Visual Reasoning by a Neuro-Symbolic Program of Zero-Shot Symbols
Jul 18, 2024



We consider the problem of finding spatial configurations of multiple objects in images, e.g., a mobile inspection robot is tasked to localize abandoned tools on the floor. We define the spatial configuration of objects by first-order logic in terms of relations and attributes. A neuro-symbolic program matches the logic formulas to probabilistic object proposals for the given image, provided by language-vision models by querying them for the symbols. This work is the first to combine neuro-symbolic programming (reasoning) and language-vision models (learning) to find spatial configurations of objects in images in an open world setting. We show the effectiveness by finding abandoned tools on floors and leaking pipes. We find that most prediction errors are due to biases in the language-vision model.
* 12 pages
Prediction of new outlinks for focused Web crawling
Nov 10, 2021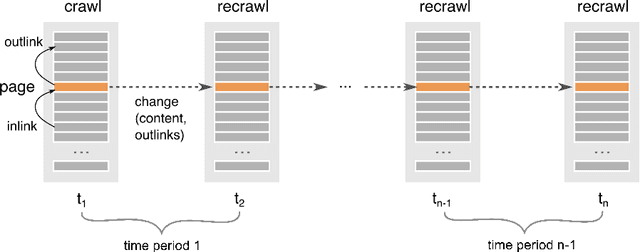
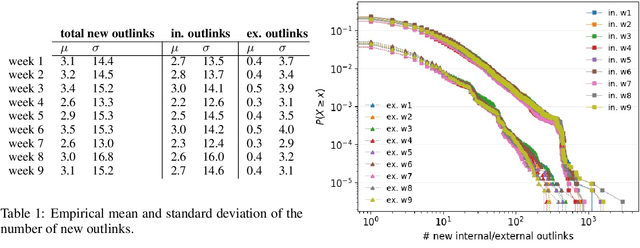


Discovering new hyperlinks enables Web crawlers to find new pages that have not yet been indexed. This is especially important for focused crawlers because they strive to provide a comprehensive analysis of specific parts of the Web, thus prioritizing discovery of new pages over discovery of changes in content. In the literature, changes in hyperlinks and content have been usually considered simultaneously. However, there is also evidence suggesting that these two types of changes are not necessarily related. Moreover, many studies about predicting changes assume that long history of a page is available, which is unattainable in practice. The aim of this work is to provide a methodology for detecting new links effectively using a short history. To this end, we use a dataset of ten crawls at intervals of one week. Our study consists of three parts. First, we obtain insight in the data by analyzing empirical properties of the number of new outlinks. We observe that these properties are, on average, stable over time, but there is a large difference between emergence of hyperlinks towards pages within and outside the domain of a target page (internal and external outlinks, respectively). Next, we provide statistical models for three targets: the link change rate, the presence of new links, and the number of new links. These models include the features used earlier in the literature, as well as new features introduced in this work. We analyze correlation between the features, and investigate their informativeness. A notable finding is that, if the history of the target page is not available, then our new features, that represent the history of related pages, are most predictive for new links in the target page. Finally, we propose ranking methods as guidelines for focused crawlers to efficiently discover new pages, which achieve excellent performance with respect to the corresponding targets.
Independent Prototype Propagation for Zero-Shot Compositionality
Jun 12, 2021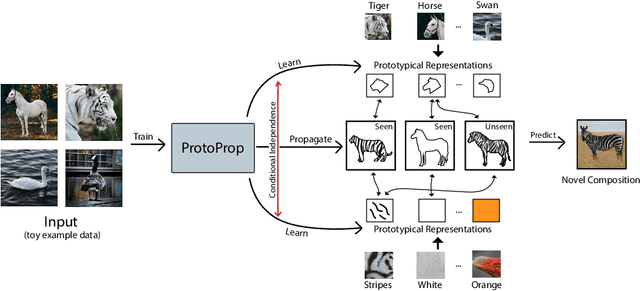
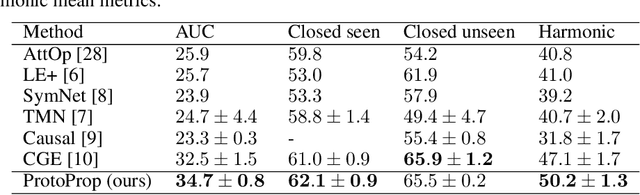
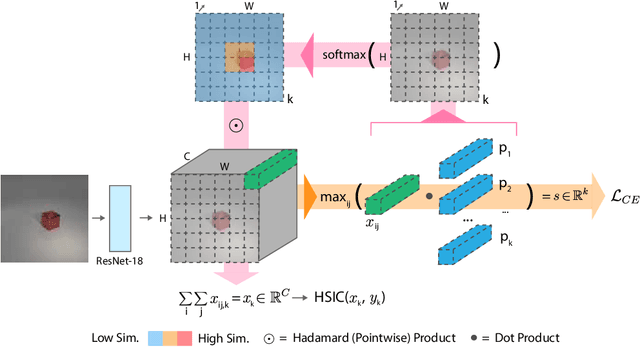

Humans are good at compositional zero-shot reasoning; someone who has never seen a zebra before could nevertheless recognize one when we tell them it looks like a horse with black and white stripes. Machine learning systems, on the other hand, usually leverage spurious correlations in the training data, and while such correlations can help recognize objects in context, they hurt generalization. To be able to deal with underspecified datasets while still leveraging contextual clues during classification, we propose ProtoProp, a novel prototype propagation graph method. First we learn prototypical representations of objects (e.g., zebra) that are conditionally independent w.r.t. their attribute labels (e.g., stripes) and vice versa. Next we propagate the independent prototypes through a compositional graph, to learn compositional prototypes of novel attribute-object combinations that reflect the dependencies of the target distribution. The method does not rely on any external data, such as class hierarchy graphs or pretrained word embeddings. We evaluate our approach on AO-Clever, a synthetic and strongly visual dataset with clean labels, and UT-Zappos, a noisy real-world dataset of fine-grained shoe types. We show that in the generalized compositional zero-shot setting we outperform state-of-the-art results, and through ablations we show the importance of each part of the method and their contribution to the final results.