 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generic approach for reactive stateful mitigation of application failures in distributed robotics systems deployed with Kubernetes
Oct 24, 2024



Offloading computationally expensive algorithms to the edge or even cloud offers an attractive option to tackle limitations regarding on-board computational and energy resources of robotic systems. In cloud-native applications deployed with the container management system Kubernetes (K8s), one key problem is ensuring resilience against various types of failures. However, complex robotic systems interacting with the physical world pose a very specific set of challenges and requirements that are not yet covered by failure mitigation approaches from the cloud-native domain. In this paper, we therefore propose a novel approach for robotic system monitoring and stateful, reactive failure mitigation for distributed robotic systems deployed using Kubernetes (K8s) and the Robot Operating System (ROS2). By employing the generic substrate of Behaviour Trees, our approach can be applied to any robotic workload and supports arbitrarily complex monitoring and failure mitigation strategies. We demonstrate the effectiveness and application-agnosticism of our approach on two example applications, namely Autonomous Mobile Robot (AMR) navigation and robotic manipulation in a simulated environment.
Scenario Execution for Robotics: A generic, backend-agnostic library for running reproducible robotics experiments and tests
Sep 11, 2024



Testing and evaluation of robotics systems is a difficult and oftentimes tedious task due to the systems' complexity and a lack of tools to conduct reproducible robotics experiments. Additionally, almost all available tools are either tailored towards a specific application domain, simulator or middleware. Particularly scenario-based testing, a common practice in the domain of automated driving, is not sufficiently covered in the robotics domain. In this paper, we propose a novel backend- and middleware-agnostic approach for conducting systematic, reproducible and automatable robotics experiments called Scenario Execution for Robotics. Our approach is implemented as a Python library built on top of the generic scenario description language OpenSCENARIO 2 and Behavior Trees and is made publicly available on GitHub. In extensive experiments, we demonstrate that our approach supports multiple simulators as backend and can be used as a standalone Python-library or as part of the ROS2 ecosystem. Furthermore, we demonstrate how our approach enables testing over ranges of varying values. Finally, we show how Scenario Execution for Robotics allows to move from simulation-based to real-world experiments with minimal adaptations to the scenario description file.
The Importance of Balanced Data Sets: Analyzing a Vehicle Trajectory Prediction Model based on Neural Networks and Distributed Representations
Sep 30, 2020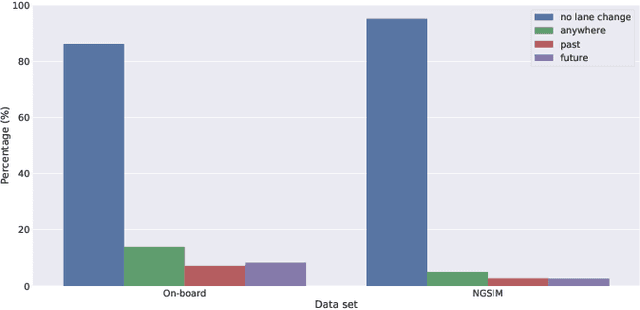
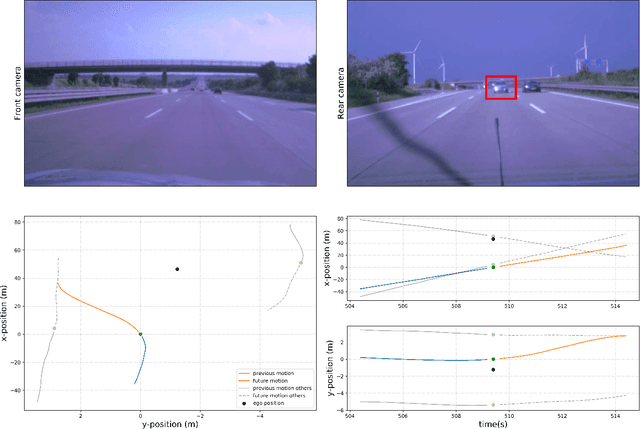
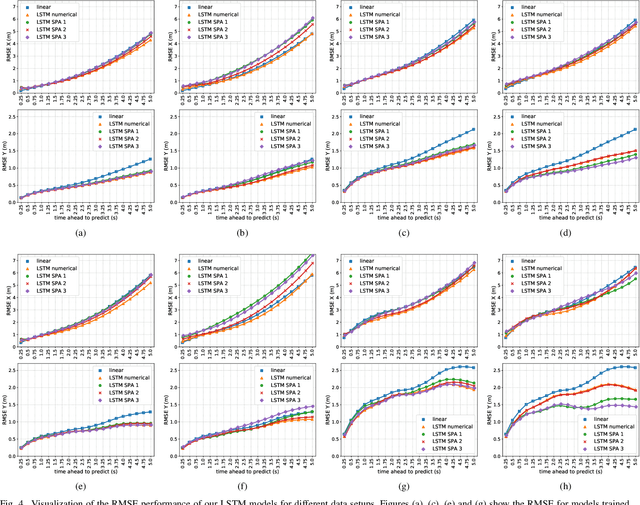
Predicting future behavior of other traffic participants is an essential task that needs to be solved by automated vehicles and human drivers alike to achieve safe and situationaware driving. Modern approaches to vehicles trajectory prediction typically rely on data-driven models like neural networks, in particular LSTMs (Long Short-Term Memorys), achieving promising results. However, the question of optimal composition of the underlying training data has received less attention. In this paper, we expand on previous work on vehicle trajectory prediction based on neural network models employing distributed representations to encode automotive scenes in a semantic vector substrate. We analyze the influence of variations in the training data on the performance of our prediction models. Thereby, we show that the models employing our semantic vector representation outperform the numerical model when trained on an adequate data set and thereby, that the composition of training data in vehicle trajectory prediction is crucial for successful training. We conduct our analysis on challenging real-world driving data.
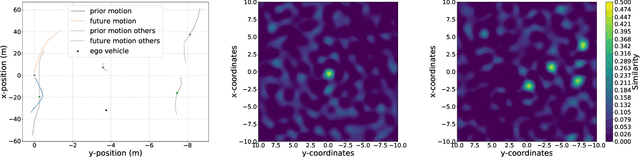
Analyzing the Capacity of Distributed Vector Representations to Encode Spatial Information
Sep 30, 2020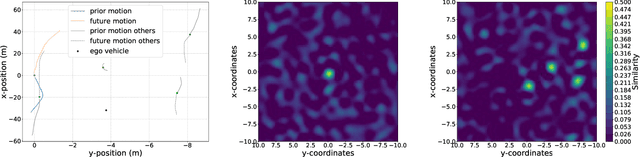
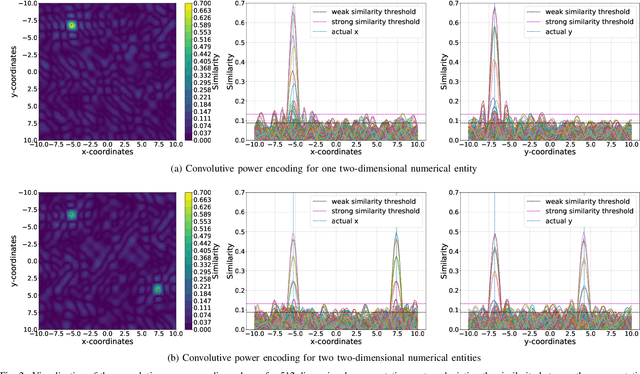
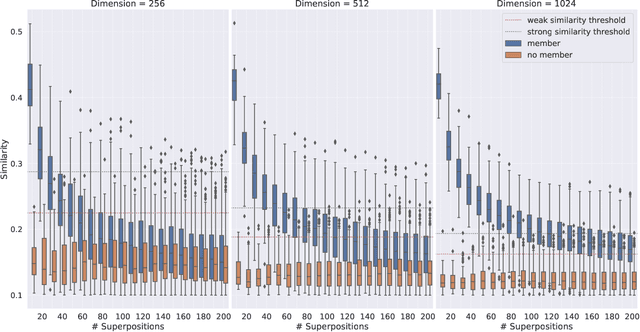
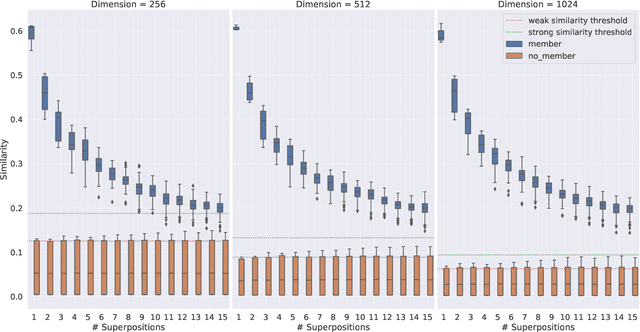
Vector Symbolic Architectures belong to a family of related cognitive modeling approaches that encode symbols and structures in high-dimensional vectors. Similar to human subjects, whose capacity to process and store information or concepts in short-term memory is subject to numerical restrictions,the capacity of information that can be encoded in such vector representations is limited and one way of modeling the numerical restrictions to cognition. In this paper, we analyze these limits regarding information capacity of distributed representations. We focus our analysis on simple superposition and more complex, structured representations involving convolutive powers to encode spatial information. In two experiments, we find upper bounds for the number of concepts that can effectively be stored in a single vector.