 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaccDiv: A Metric and Benchmark for Quantifying Diversity of Generated Marketing Text in the Music Industry
Apr 29, 2025



Online platforms are increasingly interested in using Data-to-Text technologies to generate content and help their users. Unfortunately, traditional generative methods often fall into repetitive patterns, resulting in monotonous galleries of texts after only a few iterations. In this paper, we investigate LLM-based data-to-text approaches to automatically generate marketing texts that are of sufficient quality and diverse enough for broad adoption. We leverage Language Models such as T5, GPT-3.5, GPT-4, and LLaMa2 in conjunction with fine-tuning, few-shot, and zero-shot approaches to set a baseline for diverse marketing texts. We also introduce a metric JaccDiv to evaluate the diversity of a set of texts. This research extends its relevance beyond the music industry, proving beneficial in various fields where repetitive automated content generation is prevalent.
Spend Your Budget Wisely: Towards an Intelligent Distribution of the Privacy Budget in Differentially Private Text Rewriting
Mar 28, 2025



The task of $\textit{Differentially Private Text Rewriting}$ is a class of text privatization techniques in which (sensitive) input textual documents are $\textit{rewritten}$ under Differential Privacy (DP) guarantees. The motivation behind such methods is to hide both explicit and implicit identifiers that could be contained in text, while still retaining the semantic meaning of the original text, thus preserving utility. Recent years have seen an uptick in research output in this field, offering a diverse array of word-, sentence-, and document-level DP rewriting methods. Common to these methods is the selection of a privacy budget (i.e., the $\varepsilon$ parameter), which governs the degree to which a text is privatized. One major limitation of previous works, stemming directly from the unique structure of language itself, is the lack of consideration of $\textit{where}$ the privacy budget should be allocated, as not all aspects of language, and therefore text, are equally sensitive or personal. In this work, we are the first to address this shortcoming, asking the question of how a given privacy budget can be intelligently and sensibly distributed amongst a target document. We construct and evaluate a toolkit of linguistics- and NLP-based methods used to allocate a privacy budget to constituent tokens in a text document. In a series of privacy and utility experiments, we empirically demonstrate that given the same privacy budget, intelligent distribution leads to higher privacy levels and more positive trade-offs than a naive distribution of $\varepsilon$. Our work highlights the intricacies of text privatization with DP, and furthermore, it calls for further work on finding more efficient ways to maximize the privatization benefits offered by DP in text rewriting.
Investigating User Perspectives on Differentially Private Text Privatization
Mar 12, 2025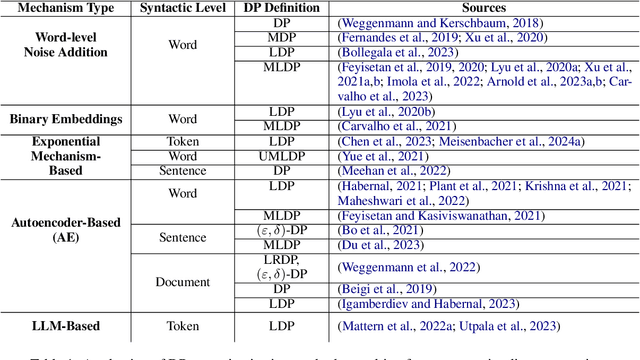
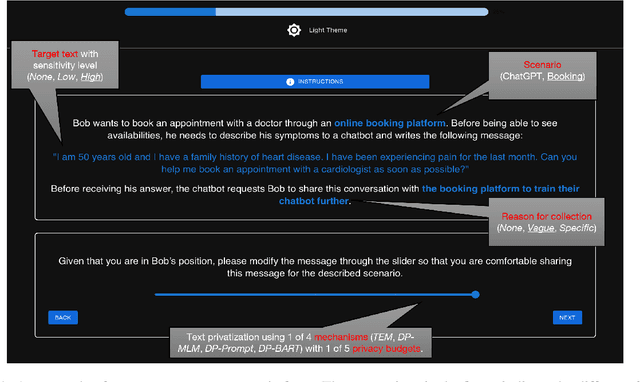


Recent literature has seen a considerable uptick in $\textit{Differentially Private Natural Language Processing}$ (DP NLP). This includes DP text privatization, where potentially sensitive input texts are transformed under DP to achieve privatized output texts that ideally mask sensitive information $\textit{and}$ maintain original semantics. Despite continued work to address the open challenges in DP text privatization, there remains a scarcity of work addressing user perceptions of this technology, a crucial aspect which serves as the final barrier to practical adoption. In this work, we conduct a survey study with 721 laypersons around the globe, investigating how the factors of $\textit{scenario}$, $\textit{data sensitivity}$, $\textit{mechanism type}$, and $\textit{reason for data collection}$ impact user preferences for text privatization. We learn that while all these factors play a role in influencing privacy decisions, users are highly sensitive to the utility and coherence of the private output texts. Our findings highlight the socio-technical factors that must be considered in the study of DP NLP, opening the door to further user-based investigations going forward.
Step-by-Step Fact Verification System for Medical Claims with Explainable Reasoning
Feb 20, 2025



Fact verification (FV) aims to assess the veracity of a claim based on relevant evidence. The traditional approach for automated FV includes a three-part pipeline relying on short evidence snippets and encoder-only inference models. More recent approaches leverage the multi-turn nature of LLMs to address FV as a step-by-step problem where questions inquiring additional context are generated and answered until there is enough information to make a decision. This iterative method makes the verification process rational and explainable. While these methods have been tested for encyclopedic claims, exploration on domain-specific and realistic claims is missing. In this work, we apply an iterative FV system on three medical fact-checking datasets and evaluate it with multiple settings, including different LLMs, external web search, and structured reasoning using logic predicates. We demonstrate improvements in the final performance over traditional approaches and the high potential of step-by-step FV systems for domain-specific claims.
On the Influence of Context Size and Model Choice in Retrieval-Augmented Generation Systems
Feb 20, 2025



Retrieval-augmented generation (RAG) has emerged as an approach to augment large language models (LLMs) by reducing their reliance on static knowledge and improving answer factuality. RAG retrieves relevant context snippets and generates an answer based on them. Despite its increasing industrial adoption, systematic exploration of RAG components is lacking, particularly regarding the ideal size of provided context, and the choice of base LLM and retrieval method. To help guide development of robust RAG systems, we evaluate various context sizes, BM25 and semantic search as retrievers, and eight base LLMs. Moving away from the usual RAG evaluation with short answers, we explore the more challenging long-form question answering in two domains, where a good answer has to utilize the entire context. Our findings indicate that final QA performance improves steadily with up to 15 snippets but stagnates or declines beyond that. Finally, we show that different general-purpose LLMs excel in the biomedical domain than the encyclopedic one, and that open-domain evidence retrieval in large corpora is challenging.
Lexical Substitution is not Synonym Substitution: On the Importance of Producing Contextually Relevant Word Substitutes
Feb 06, 2025Lexical Substitution is the task of replacing a single word in a sentence with a similar one. This should ideally be one that is not necessarily only synonymous, but also fits well into the surrounding context of the target word, while preserving the sentence's grammatical structure. Recent advances in Lexical Substitution have leveraged the masked token prediction task of Pre-trained Language Models to generate replacements for a given word in a sentence. With this technique, we introduce ConCat, a simple augmented approach which utilizes the original sentence to bolster contextual information sent to the model. Compared to existing approaches, it proves to be very effective in guiding the model to make contextually relevant predictions for the target word. Our study includes a quantitative evaluation, measured via sentence similarity and task performance. In addition, we conduct a qualitative human analysis to validate that users prefer the substitutions proposed by our method, as opposed to previous methods. Finally, we test our approach on the prevailing benchmark for Lexical Substitution, CoInCo, revealing potential pitfalls of the benchmark. These insights serve as the foundation for a critical discussion on the way in which Lexical Substitution is evaluated.
On the Impact of Noise in Differentially Private Text Rewriting
Jan 31, 2025



The field of text privatization often leverages the notion of $\textit{Differential Privacy}$ (DP) to provide formal guarantees in the rewriting or obfuscation of sensitive textual data. A common and nearly ubiquitous form of DP application necessitates the addition of calibrated noise to vector representations of text, either at the data- or model-level, which is governed by the privacy parameter $\varepsilon$. However, noise addition almost undoubtedly leads to considerable utility loss, thereby highlighting one major drawback of DP in NLP. In this work, we introduce a new sentence infilling privatization technique, and we use this method to explore the effect of noise in DP text rewriting. We empirically demonstrate that non-DP privatization techniques excel in utility preservation and can find an acceptable empirical privacy-utility trade-off, yet cannot outperform DP methods in empirical privacy protections. Our results highlight the significant impact of noise in current DP rewriting mechanisms, leading to a discussion of the merits and challenges of DP in NLP, as well as the opportunities that non-DP methods present.
AI-assisted German Employment Contract Review: A Benchmark Dataset
Jan 27, 2025Employment contracts are used to agree upon the working conditions between employers and employees all over the world. Understanding and reviewing contracts for void or unfair clauses requires extensive knowledge of the legal system and terminology. Recent advances in Natural Language Processing (NLP) hold promise for assisting in these reviews. However, applying NLP techniques on legal text is particularly difficult due to the scarcity of expert-annotated datasets. To address this issue and as a starting point for our effort in assisting lawyers with contract reviews using NLP, we release an anonymized and annotated benchmark dataset for legality and fairness review of German employment contract clauses, alongside with baseline model evaluations.
CarMem: Enhancing Long-Term Memory in LLM Voice Assistants through Category-Bounding
Jan 16, 2025



In today's assistant landscape, personalisation enhances interactions, fosters long-term relationships, and deepens engagement. However, many systems struggle with retaining user preferences, leading to repetitive user requests and disengagement. Furthermore, the unregulated and opaque extraction of user preferences in industry applications raises significant concerns about privacy and trust, especially in regions with stringent regulations like Europe. In response to these challenges, we propose a long-term memory system for voice assistants, structured around predefined categories. This approach leverages Large Language Models to efficiently extract, store, and retrieve preferences within these categories, ensuring both personalisation and transparency. We also introduce a synthetic multi-turn, multi-session conversation dataset (CarMem), grounded in real industry data, tailored to an in-car voice assistant setting. Benchmarked on the dataset, our system achieves an F1-score of .78 to .95 in preference extraction, depending on category granularity. Our maintenance strategy reduces redundant preferences by 95% and contradictory ones by 92%, while the accuracy of optimal retrieval is at .87. Collectively, the results demonstrate the system's suitability for industrial applications.
Towards Optimizing a Retrieval Augmented Generation using Large Language Model on Academic Data
Nov 13, 2024



Given the growing trend of many organizations integrating Retrieval Augmented Generation (RAG) into their operations, we assess RAG on domain-specific data and test state-of-the-art models across various optimization techniques. We incorporate four optimizations; Multi-Query, Child-Parent-Retriever, Ensemble Retriever, and In-Context-Learning, to enhance the functionality and performance in the academic domain. We focus on data retrieval, specifically targeting various study programs at a large technical university. We additionally introduce a novel evaluation approach, the RAG Confusion Matrix designed to assess the effectiveness of various configurations within the RAG framework. By exploring the integration of both open-source (e.g., Llama2, Mistral) and closed-source (GPT-3.5 and GPT-4) Large Language Models, we offer valuable insights into the application and optimization of RAG frameworks in domain-specific contexts. Our experiments show a significant performance increase when including multi-query in the retrieval phase.