 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Robustness of Indoor Robotic Navigation with Free-Space Segmentation Models Against Adversarial Attacks
Feb 13, 2024Endeavors in indoor robotic navigation rely on the accuracy of segmentation models to identify free space in RGB images. However, deep learning models are vulnerable to adversarial attacks, posing a significant challenge to their real-world deployment. In this study, we identify vulnerabilities within the hidden layers of neural networks and introduce a practical approach to reinforce traditional adversarial training. Our method incorporates a novel distance loss function, minimizing the gap between hidden layers in clean and adversarial images. Experiments demonstrate satisfactory performance in improving the model's robustness against adversarial perturbations.
Depth-guided Free-space Segmentation for a Mobile Robot
Nov 03, 2023



Accurate indoor free-space segmentation is a challenging task due to the complexity and the dynamic nature that indoor environments exhibit. We propose an indoors free-space segmentation method that associates large depth values with navigable regions. Our method leverages an unsupervised masking technique that, using positive instances, generates segmentation labels based on textural homogeneity and depth uniformity. Moreover, we generate superpixels corresponding to areas of higher depth and align them with features extracted from a Dense Prediction Transformer (DPT). Using the estimated free-space masks and the DPT feature representation, a SegFormer model is fine-tuned on our custom-collected indoor dataset. Our experiments demonstrate sufficient performance in intricate scenarios characterized by cluttered obstacles and challenging identification of free space.
Understanding Cognitive Fatigue from fMRI Scans with Self-supervised Learning
Jun 30, 2021

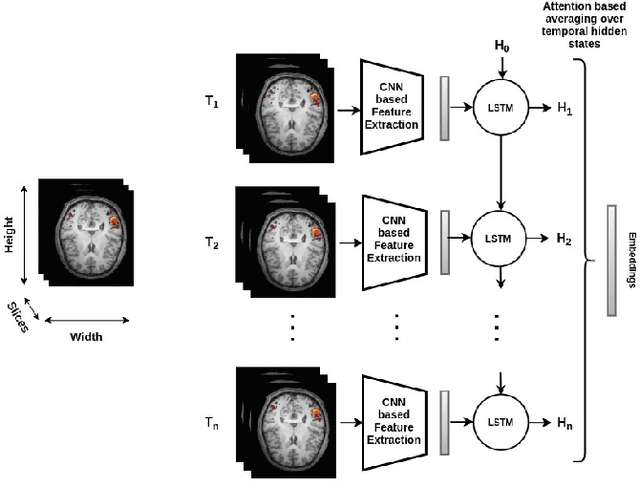
Functional magnetic resonance imaging (fMRI) is a neuroimaging technique that records neural activations in the brain by capturing the blood oxygen level in different regions based on the task performed by a subject. Given fMRI data, the problem of predicting the state of cognitive fatigue in a person has not been investigated to its full extent. This paper proposes tackling this issue as a multi-class classification problem by dividing the state of cognitive fatigue into six different levels, ranging from no-fatigue to extreme fatigue conditions. We built a spatio-temporal model that uses convolutional neural networks (CNN) for spatial feature extraction and a long short-term memory (LSTM) network for temporal modeling of 4D fMRI scans. We also applied a self-supervised method called MoCo to pre-train our model on a public dataset BOLD5000 and fine-tuned it on our labeled dataset to classify cognitive fatigue. Our novel dataset contains fMRI scans from Traumatic Brain Injury (TBI) patients and healthy controls (HCs) while performing a series of cognitive tasks. This method establishes a state-of-the-art technique to analyze cognitive fatigue from fMRI data and beats previous approaches to solve this problem.
Sequential Late Fusion Technique for Multi-modal Sentiment Analysis
Jun 22, 2021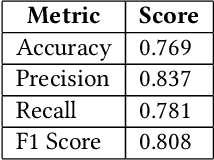
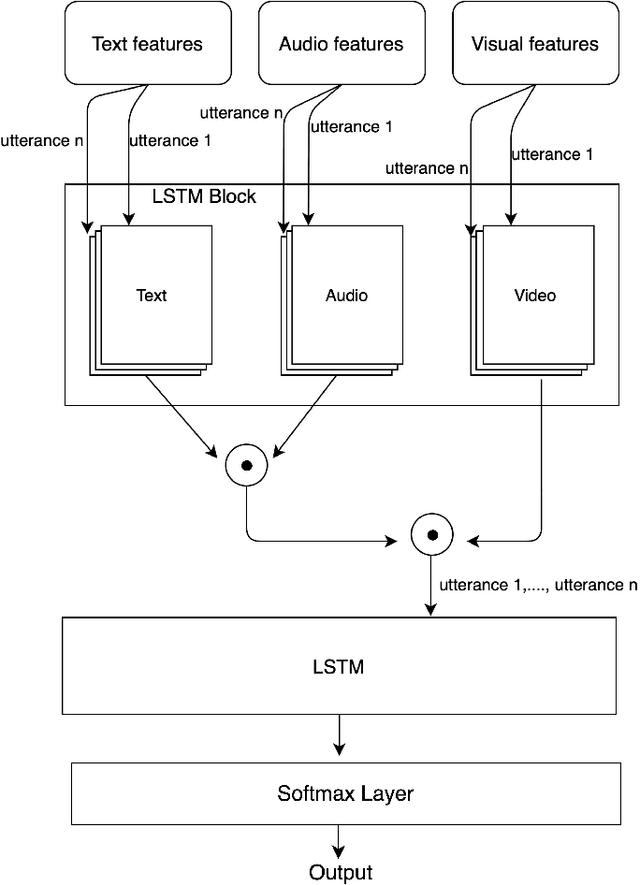
Multi-modal sentiment analysis plays an important role for providing better interactive experiences to users. Each modality in multi-modal data can provide different viewpoints or reveal unique aspects of a user's emotional state. In this work, we use text, audio and visual modalities from MOSI dataset and we propose a novel fusion technique using a multi-head attention LSTM network. Finally, we perform a classification task and evaluate its performance.
Towards a Multi-purpose Robotic Nursing Assistant
Jun 07, 2021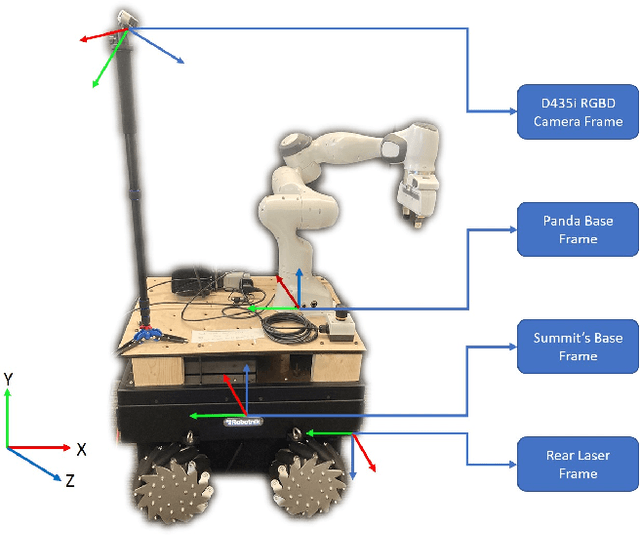


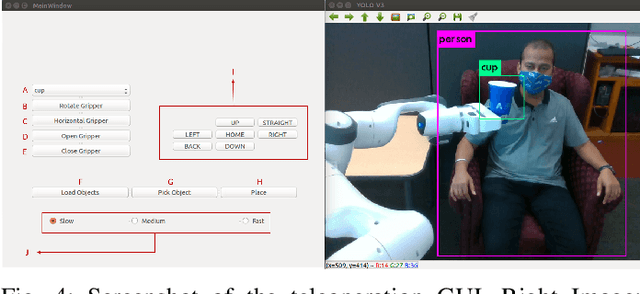
Robotic nursing aid is one of the heavily researched areas in robotics nowadays. Several robotic assistants exist that only focus on a specific function related to nurses assistance or functions related to patient aid. There is a need for a unified system that not only performs tasks that would assist nurses and reduce their burden but also perform tasks that help a patient. In recent times, due to the COVID-19 pandemic, there is also an increase in the need for robotic assistants that have teleoperation capabilities to provide better protection against the virus spread. To address these requirements, we propose a novel Multi-purpose Intelligent Nurse Aid (MINA) robotic system that is capable of providing walking assistance to the patients and perform teleoperation tasks with an easy-to-use and intuitive Graphical User Interface (GUI). This paper also presents preliminary results from the walking assistant task that improves upon the current state-of-the-art methods and shows the developed GUI for teleoperation.
Automated system to measure Tandem Gait to assess executive functions in children
Dec 28, 2020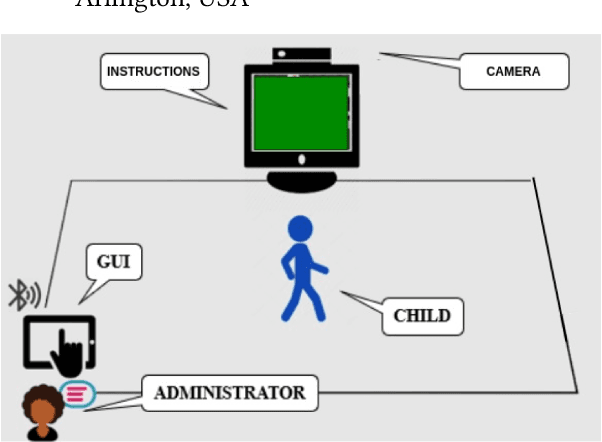
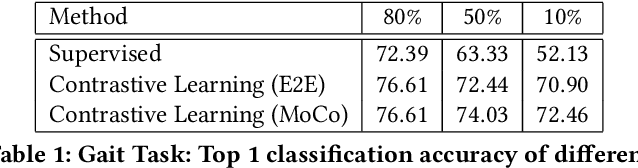
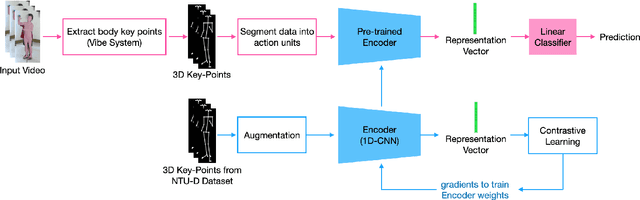
As mobile technologies have become ubiquitous in recent years, computer-based cognitive tests have become more popular and efficient. In this work, we focus on assessing motor function in children by analyzing their gait movements. Although there has been a lot of research on designing automated assessment systems for gait analysis, most of these efforts use obtrusive wearable sensors for measuring body movements. We have devised a computer vision-based assessment system that only requires a camera which makes it easier to employ in school or home environments. A dataset has been created with 27 children performing the test. Furthermore in order to improve the accuracy of the system, a deep learning based model was pre-trained on NTU-RGB+D 120 dataset and then it was fine-tuned on our gait dataset. The results highlight the efficacy of proposed work for automating the assessment of children's performances by achieving 76.61% classification accuracy.
A Survey on Contrastive Self-supervised Learning
Oct 31, 2020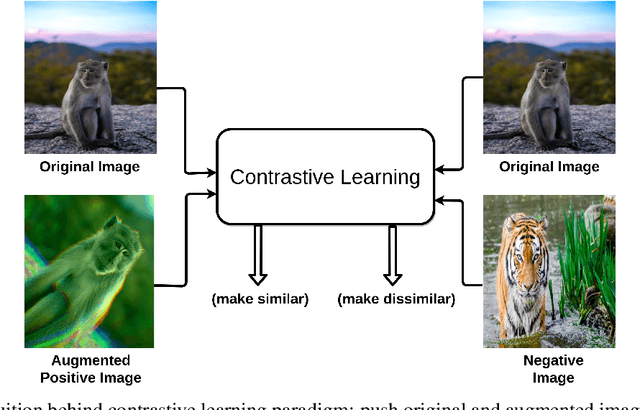
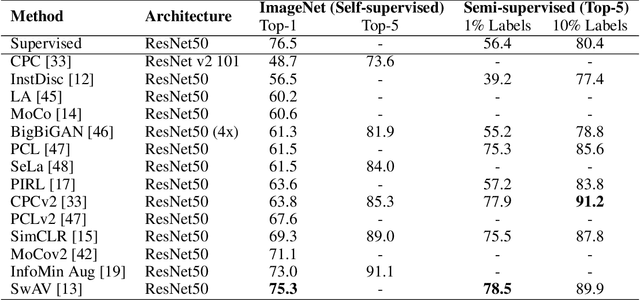
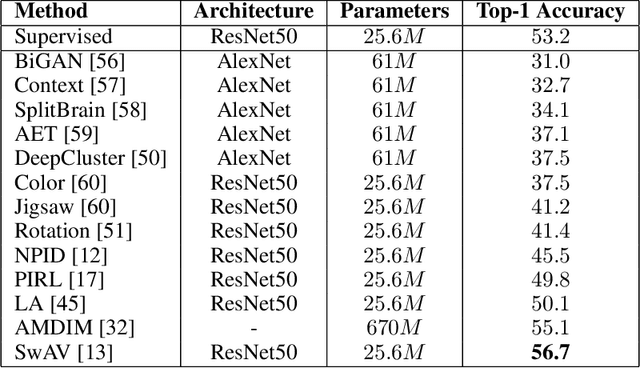
Self-supervised learning has gained popularity because of its ability to avoid the cost of annotating large-scale datasets. It is capable of adopting self-defined pseudo labels as supervision and use the learned representations for several downstream tasks. Specifically, contrastive learning has recently become a dominant component in self-supervised learning methods for computer vision, natural language processing (NLP), and other domains. It aims at embedding augmented versions of the same sample close to each other while trying to push away embeddings from different samples. This paper provides an extensive review of self-supervised methods that follow the contrastive approach. The work explains commonly used pretext tasks in a contrastive learning setup, followed by different architectures that have been proposed so far. Next, we have a performance comparison of different methods for multiple downstream tasks such as image classification, object detection, and action recognition. Finally, we conclude with the limitations of the current methods and the need for further techniques and future directions to make substantial progress.
Self-Supervised Human Activity Recognition by Augmenting Generative Adversarial Networks
Aug 26, 2020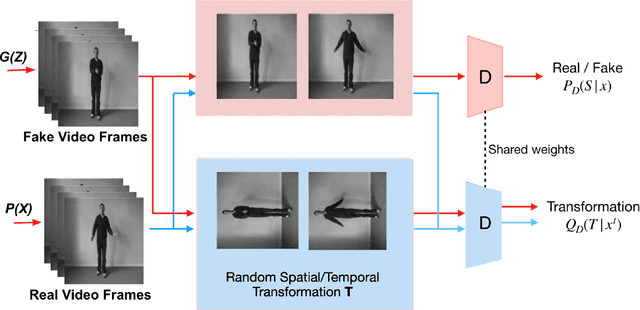
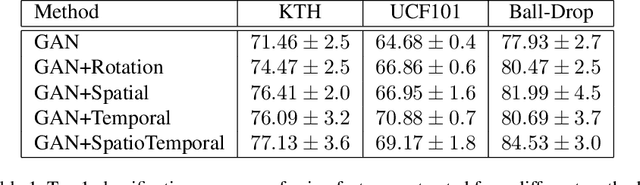

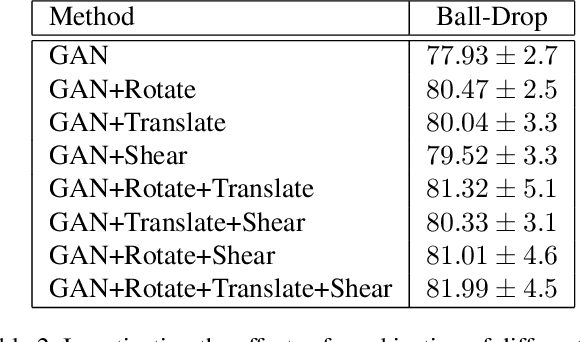
This article proposes a novel approach for augmenting generative adversarial network (GAN) with a self-supervised task in order to improve its ability for encoding video representations that are useful in downstream tasks such as human activity recognition. In the proposed method, input video frames are randomly transformed by different spatial transformations, such as rotation, translation and shearing or temporal transformations such as shuffling temporal order of frames. Then discriminator is encouraged to predict the applied transformation by introducing an auxiliary loss. Subsequently, results prove superiority of the proposed method over baseline methods for providing a useful representation of videos used in human activity recognition performed on datasets such as KTH, UCF101 and Ball-Drop. Ball-Drop dataset is a specifically designed dataset for measuring executive functions in children through physically and cognitively demanding tasks. Using features from proposed method instead of baseline methods caused the top-1 classification accuracy to increase by more then 4%. Moreover, ablation study was performed to investigate the contribution of different transformations on downstream task.
Towards Deep Learning based Hand Keypoints Detection for Rapid Sequential Movements from RGB Images
Apr 03, 2018
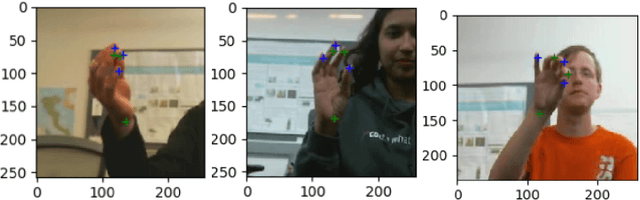
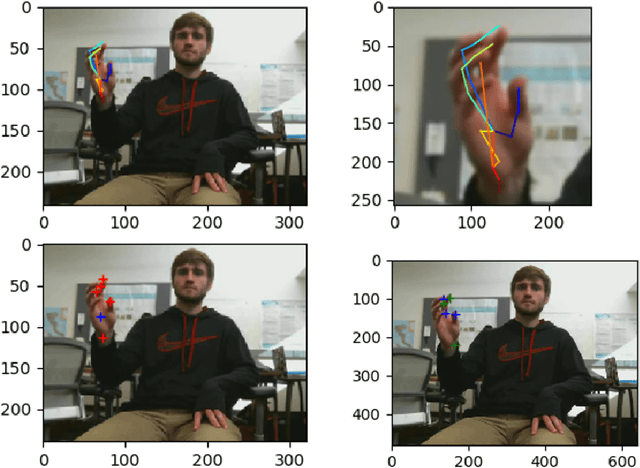
Hand keypoints detection and pose estimation has numerous applications in computer vision, but it is still an unsolved problem in many aspects. An application of hand keypoints detection is in performing cognitive assessments of a subject by observing the performance of that subject in physical tasks involving rapid finger motion. As a part of this work, we introduce a novel hand key-points benchmark dataset that consists of hand gestures recorded specifically for cognitive behavior monitoring. We explore the state of the art methods in hand keypoint detection and we provide quantitative evaluations for the performance of these methods on our dataset. In future, these results and our dataset can serve as a useful benchmark for hand keypoint recognition for rapid finger movements.
Improving the Accuracy of the CogniLearn System for Cognitive Behavior Assessment
Mar 25, 2017
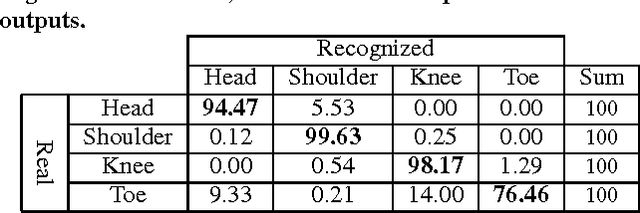
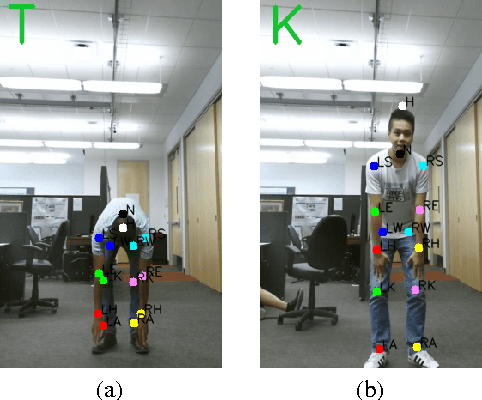
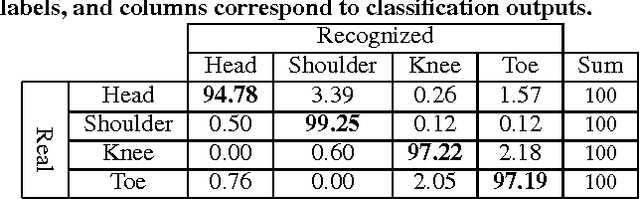
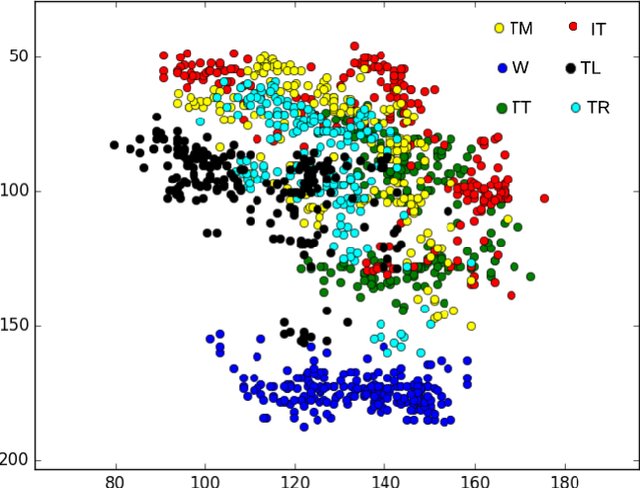
HTKS is a game-like cognitive assessment method, designed for children between four and eight years of age. During the HTKS assessment, a child responds to a sequence of requests, such as "touch your head" or "touch your toes". The cognitive challenge stems from the fact that the children are instructed to interpret these requests not literally, but by touching a different body part than the one stated. In prior work, we have developed the CogniLearn system, that captures data from subjects performing the HTKS game, and analyzes the motion of the subjects. In this paper we propose some specific improvements that make the motion analysis module more accurate. As a result of these improvements, the accuracy in recognizing cases where subjects touch their toes has gone from 76.46% in our previous work to 97.19% in this paper.