 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Pair Formulation & Accelerated Scheme for Non-convex Principal Component Pursuit
May 28, 2019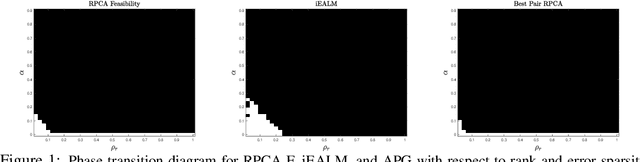
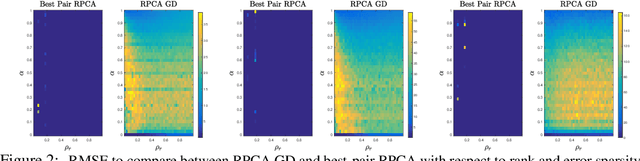

The best pair problem aims to find a pair of points that minimize the distance between two disjoint sets. In this paper, we formulate the classical robust principal component analysis (RPCA) as the best pair; which was not considered before. We design an accelerated proximal gradient scheme to solve it, for which we show global convergence, as well as the local linear rate. Our extensive numerical experiments on both real and synthetic data suggest that the algorithm outperforms relevant baseline algorithms in the literature.
One Method to Rule Them All: Variance Reduction for Data, Parameters and Many New Methods
May 27, 2019
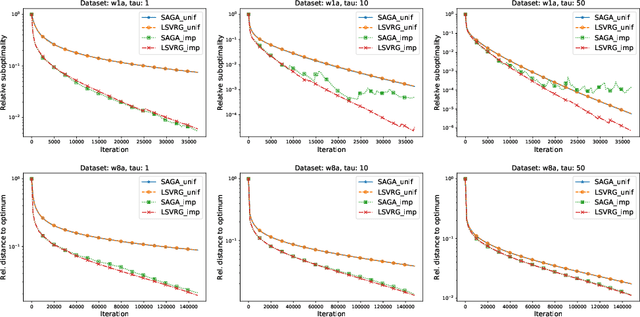
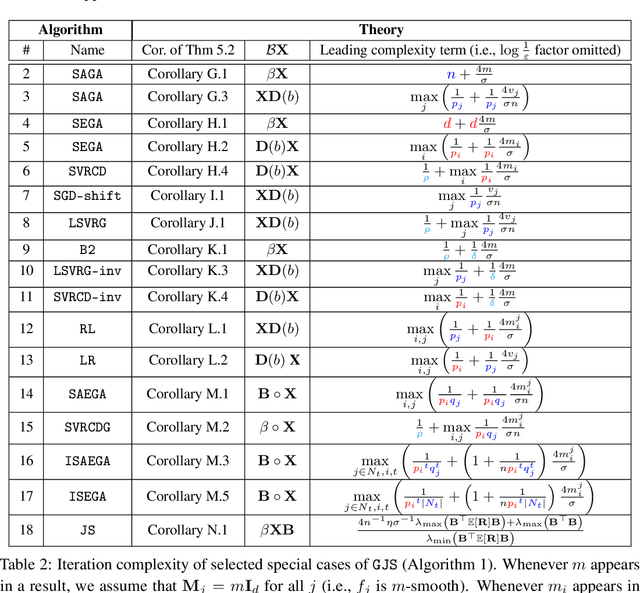
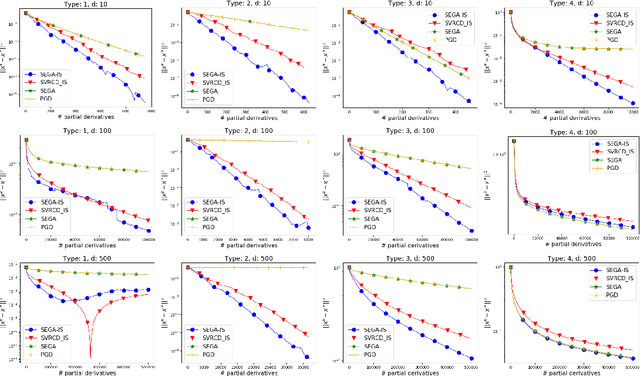
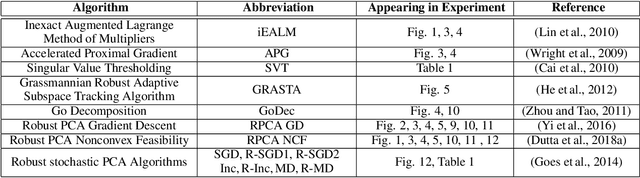
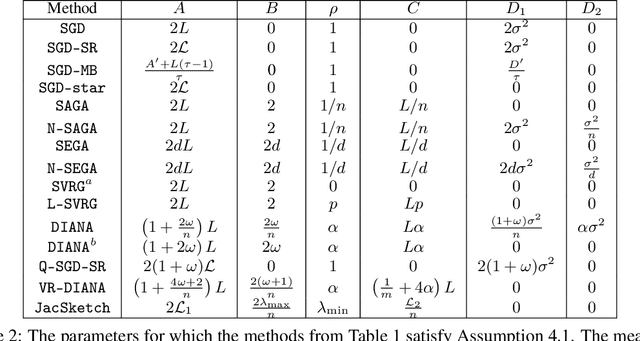
We propose a remarkably general variance-reduced method suitable for solving regularized empirical risk minimization problems with either a large number of training examples, or a large model dimension, or both. In special cases, our method reduces to several known and previously thought to be unrelated methods, such as {\tt SAGA}, {\tt LSVRG}, {\tt JacSketch}, {\tt SEGA} and {\tt ISEGA}, and their arbitrary sampling and proximal generalizations. However, we also highlight a large number of new specific algorithms with interesting properties. We provide a single theorem establishing linear convergence of the method under smoothness and quasi strong convexity assumptions. With this theorem we recover best-known and sometimes improved rates for known methods arising in special cases. As a by-product, we provide the first unified method and theory for stochastic gradient and stochastic coordinate descent type methods.
A Unified Theory of SGD: Variance Reduction, Sampling, Quantization and Coordinate Descent
May 27, 2019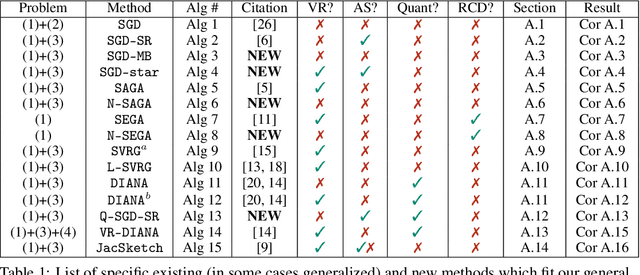
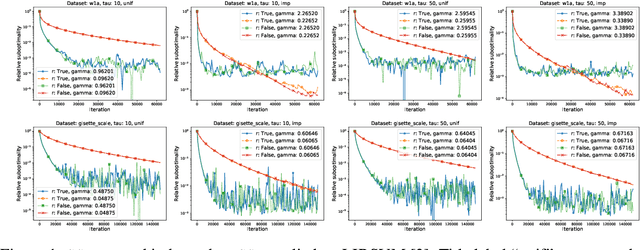
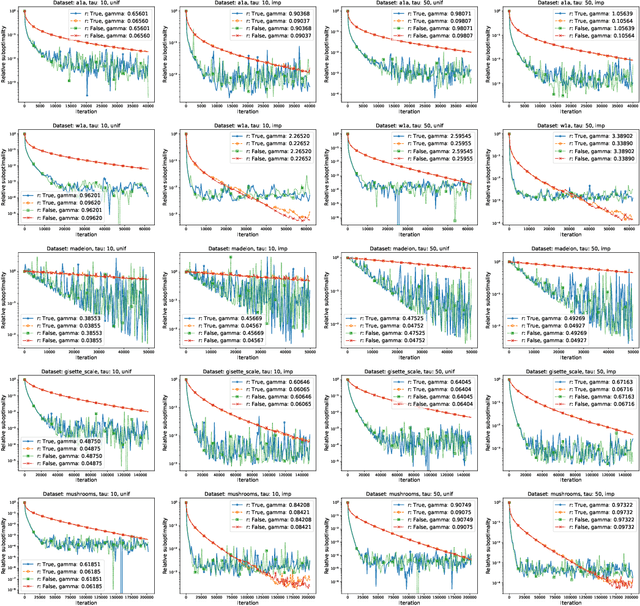
In this paper we introduce a unified analysis of a large family of variants of proximal stochastic gradient descent ({\tt SGD}) which so far have required different intuitions, convergence analyses, have different applications, and which have been developed separately in various communities. We show that our framework includes methods with and without the following tricks, and their combinations: variance reduction, importance sampling, mini-batch sampling, quantization, and coordinate sub-sampling. As a by-product, we obtain the first unified theory of {\tt SGD} and randomized coordinate descent ({\tt RCD}) methods, the first unified theory of variance reduced and non-variance-reduced {\tt SGD} methods, and the first unified theory of quantized and non-quantized methods. A key to our approach is a parametric assumption on the iterates and stochastic gradients. In a single theorem we establish a linear convergence result under this assumption and strong-quasi convexity of the loss function. Whenever we recover an existing method as a special case, our theorem gives the best known complexity result. Our approach can be used to motivate the development of new useful methods, and offers pre-proved convergence guarantees. To illustrate the strength of our approach, we develop five new variants of {\tt SGD}, and through numerical experiments demonstrate some of their properties.
99% of Parallel Optimization is Inevitably a Waste of Time
Jan 27, 2019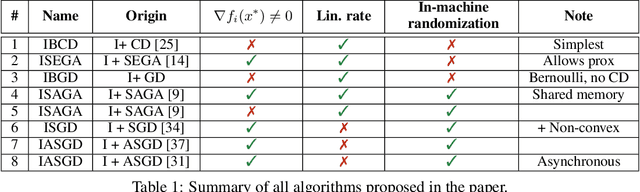
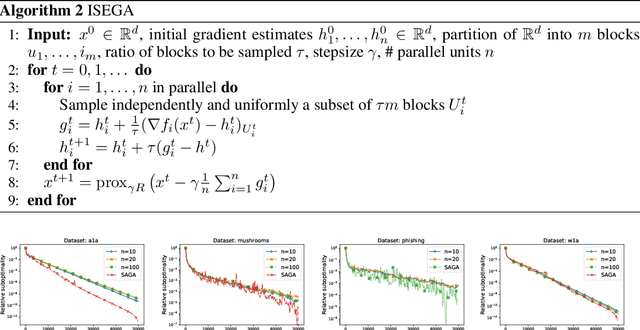

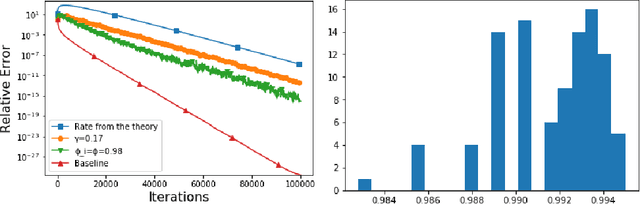
It is well known that many optimization methods, including SGD, SAGA, and Accelerated SGD for over-parameterized models, do not scale linearly in the parallel setting. In this paper, we present a new version of block coordinate descent that solves this issue for a number of methods. The core idea is to make the sampling of coordinate blocks on each parallel unit independent of the others. Surprisingly, we prove that the optimal number of blocks to be updated by each of $n$ units in every iteration is equal to $m/n$, where $m$ is the total number of blocks. As an illustration, this means that when $n=100$ parallel units are used, $99\%$ of work is a waste of time. We demonstrate that with $m/n$ blocks used by each unit the iteration complexity often remains the same. Among other applications which we mention, this fact can be exploited in the setting of distributed optimization to break the communication bottleneck. Our claims are justified by numerical experiments which demonstrate almost a perfect match with our theory on a number of datasets.
A Privacy Preserving Randomized Gossip Algorithm via Controlled Noise Insertion
Jan 27, 2019


In this work we present a randomized gossip algorithm for solving the average consensus problem while at the same time protecting the information about the initial private values stored at the nodes. We give iteration complexity bounds for the method and perform extensive numerical experiments.
SEGA: Variance Reduction via Gradient Sketching
Oct 18, 2018

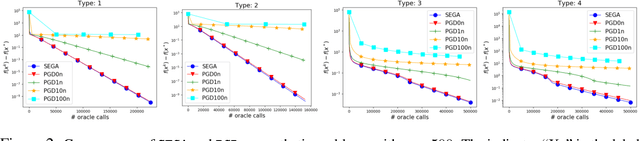
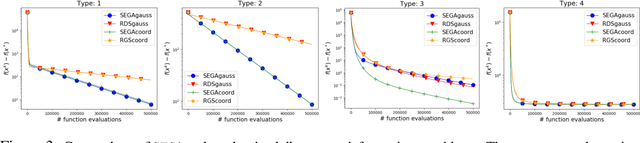
We propose a randomized first order optimization method--SEGA (SkEtched GrAdient method)-- which progressively throughout its iterations builds a variance-reduced estimate of the gradient from random linear measurements (sketches) of the gradient obtained from an oracle. In each iteration, SEGA updates the current estimate of the gradient through a sketch-and-project operation using the information provided by the latest sketch, and this is subsequently used to compute an unbiased estimate of the true gradient through a random relaxation procedure. This unbiased estimate is then used to perform a gradient step. Unlike standard subspace descent methods, such as coordinate descent, SEGA can be used for optimization problems with a non-separable proximal term. We provide a general convergence analysis and prove linear convergence for strongly convex objectives. In the special case of coordinate sketches, SEGA can be enhanced with various techniques such as importance sampling, minibatching and acceleration, and its rate is up to a small constant factor identical to the best-known rate of coordinate descent.
A Nonconvex Projection Method for Robust PCA
May 21, 2018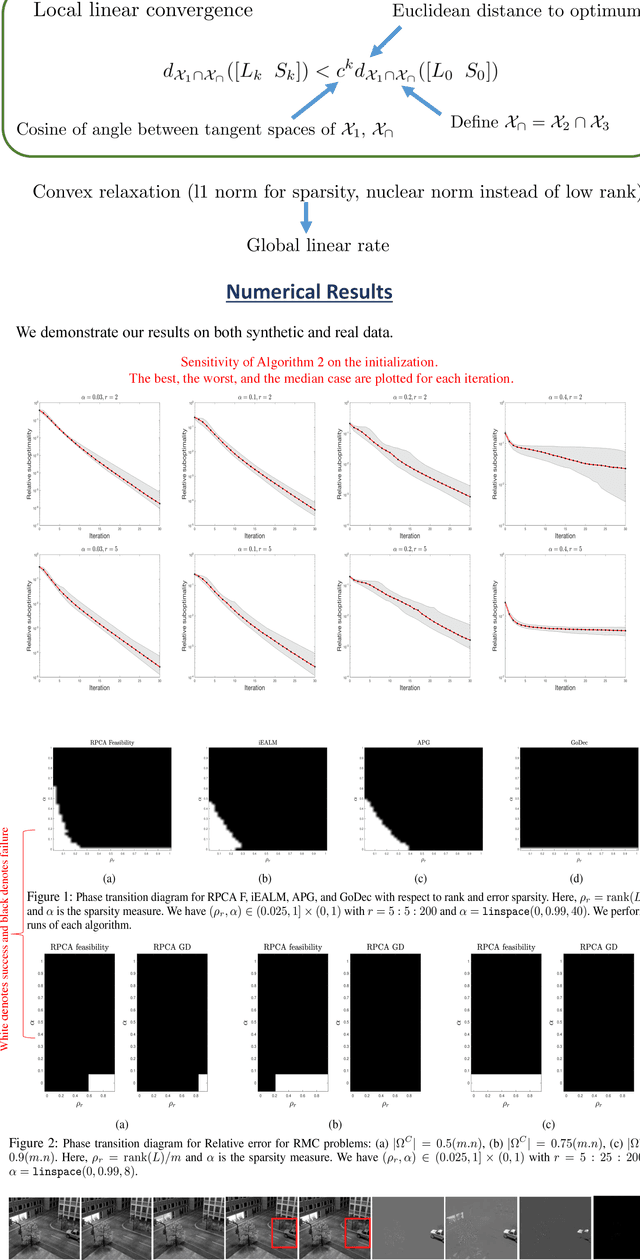
Robust principal component analysis (RPCA) is a well-studied problem with the goal of decomposing a matrix into the sum of low-rank and sparse components. In this paper, we propose a nonconvex feasibility reformulation of RPCA problem and apply an alternating projection method to solve it. To the best of our knowledge, we are the first to propose a method that solves RPCA problem without considering any objective function, convex relaxation, or surrogate convex constraints. We demonstrate through extensive numerical experiments on a variety of applications, including shadow removal, background estimation, face detection, and galaxy evolution, that our approach matches and often significantly outperforms current state-of-the-art in various ways.