 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Perception for Test-time Grasping Detection Adaptation with Knowledge Infusion
Apr 07, 2025



It has always been expected that a robot can be easily deployed to unknown scenarios, accomplishing robotic grasping tasks without human intervention. Nevertheless, existing grasp detection approaches are typically off-body techniques and are realized by training various deep neural networks with extensive annotated data support. {In this paper, we propose an embodied test-time adaptation framework for grasp detection that exploits the robot's exploratory capabilities.} The framework aims to improve the generalization performance of grasping skills for robots in an unforeseen environment. Specifically, we introduce embodied assessment criteria based on the robot's manipulation capability to evaluate the quality of the grasp detection and maintain suitable samples. This process empowers the robots to actively explore the environment and continuously learn grasping skills, eliminating human intervention. Besides, to improve the efficiency of robot exploration, we construct a flexible knowledge base to provide context of initial optimal viewpoints. Conditioned on the maintained samples, the grasp detection networks can be adapted in the test-time scene. When the robot confronts new objects, it will undergo the same adaptation procedure mentioned above to realize continuous learning. Extensive experiments conducted on a real-world robot demonstrate the effectiveness and generalization of our proposed framework.
Intelligent Spatial Perception by Building Hierarchical 3D Scene Graphs for Indoor Scenarios with the Help of LLMs
Mar 19, 2025



This paper addresses the high demand in advanced intelligent robot navigation for a more holistic understanding of spatial environments, by introducing a novel system that harnesses the capabilities of Large Language Models (LLMs) to construct hierarchical 3D Scene Graphs (3DSGs) for indoor scenarios. The proposed framework constructs 3DSGs consisting of a fundamental layer with rich metric-semantic information, an object layer featuring precise point-cloud representation of object nodes as well as visual descriptors, and higher layers of room, floor, and building nodes. Thanks to the innovative application of LLMs, not only object nodes but also nodes of higher layers, e.g., room nodes, are annotated in an intelligent and accurate manner. A polling mechanism for room classification using LLMs is proposed to enhance the accuracy and reliability of the room node annotation. Thorough numerical experiments demonstrate the system's ability to integrate semantic descriptions with geometric data, creating an accurate and comprehensive representation of the environment instrumental for context-aware navigation and task planning.
Joint embedding in Hierarchical distance and semantic representation learning for link prediction
Mar 28, 2023The link prediction task aims to predict missing entities or relations in the knowledge graph and is essential for the downstream application. Existing well-known models deal with this task by mainly focusing on representing knowledge graph triplets in the distance space or semantic space. However, they can not fully capture the information of head and tail entities, nor even make good use of hierarchical level information. Thus, in this paper, we propose a novel knowledge graph embedding model for the link prediction task, namely, HIE, which models each triplet (\textit{h}, \textit{r}, \textit{t}) into distance measurement space and semantic measurement space, simultaneously. Moreover, HIE is introduced into hierarchical-aware space to leverage rich hierarchical information of entities and relations for better representation learning. Specifically, we apply distance transformation operation on the head entity in distance space to obtain the tail entity instead of translation-based or rotation-based approaches. Experimental results of HIE on four real-world datasets show that HIE outperforms several existing state-of-the-art knowledge graph embedding methods on the link prediction task and deals with complex relations accurately.
Syntax Controlled Knowledge Graph-to-Text Generation with Order and Semantic Consistency
Jul 02, 2022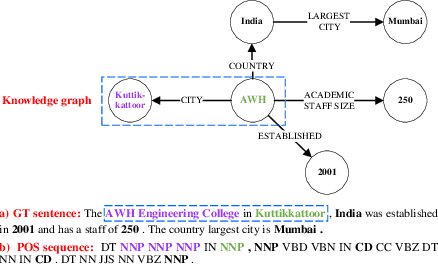
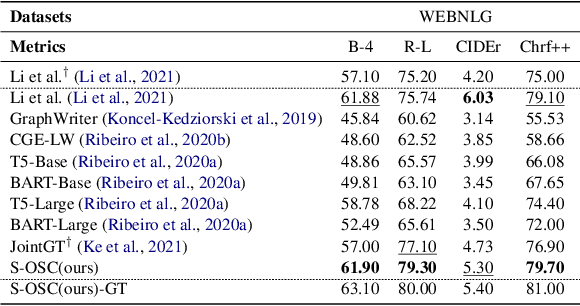
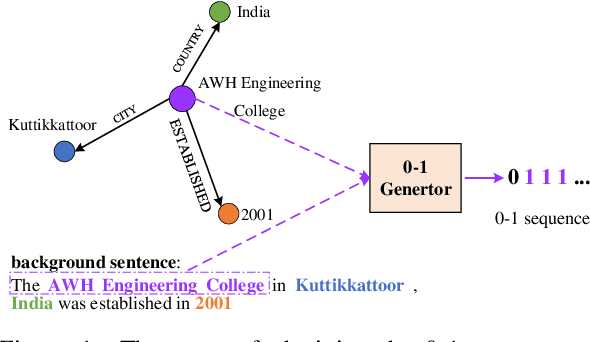
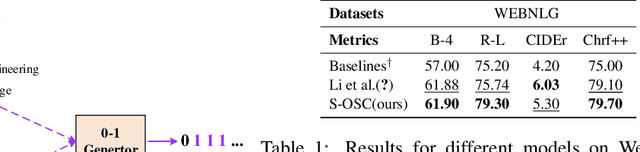
The knowledge graph (KG) stores a large amount of structural knowledge, while it is not easy for direct human understanding. Knowledge graph-to-text (KG-to-text) generation aims to generate easy-to-understand sentences from the KG, and at the same time, maintains semantic consistency between generated sentences and the KG. Existing KG-to-text generation methods phrase this task as a sequence-to-sequence generation task with linearized KG as input and consider the consistency issue of the generated texts and KG through a simple selection between decoded sentence word and KG node word at each time step. However, the linearized KG order is commonly obtained through a heuristic search without data-driven optimization. In this paper, we optimize the knowledge description order prediction under the order supervision extracted from the caption and further enhance the consistency of the generated sentences and KG through syntactic and semantic regularization. We incorporate the Part-of-Speech (POS) syntactic tags to constrain the positions to copy words from the KG and employ a semantic context scoring function to evaluate the semantic fitness for each word in its local context when decoding each word in the generated sentence. Extensive experiments are conducted on two datasets, WebNLG and DART, and achieve state-of-the-art performances.