 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Code Summarization Models
Feb 09, 2021
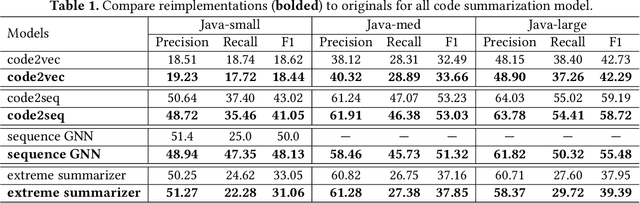


The last decade has witnessed a rapid advance in machine learning models. While the black-box nature of these systems allows powerful predictions, it cannot be directly explained, posing a threat to the continuing democratization of machine learning technology. Tackling the challenge of model explainability, research has made significant progress in demystifying the image classification models. In the same spirit of these works, this paper studies code summarization models, particularly, given an input program for which a model makes a prediction, our goal is to reveal the key features that the model uses for predicting the label of the program. We realize our approach in HouYi, which we use to evaluate four prominent code summarization models: extreme summarizer, code2vec, code2seq, and sequence GNN. Results show that all models base their predictions on syntactic and lexical properties with little to none semantic implication. Based on this finding, we present a novel approach to explaining the predictions of code summarization models through the lens of training data. Our work opens up this exciting, new direction of studying what models have learned from source code.
Learning Semantic Program Embeddings with Graph Interval Neural Network
May 27, 2020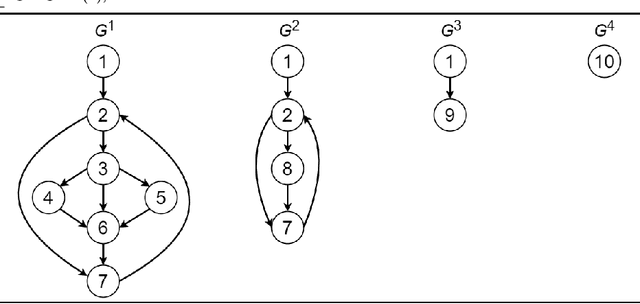
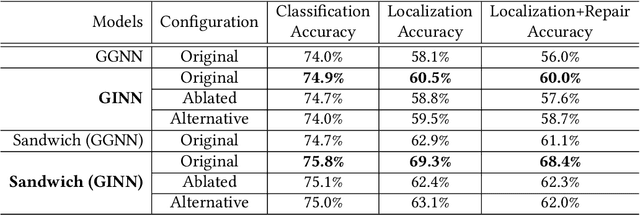
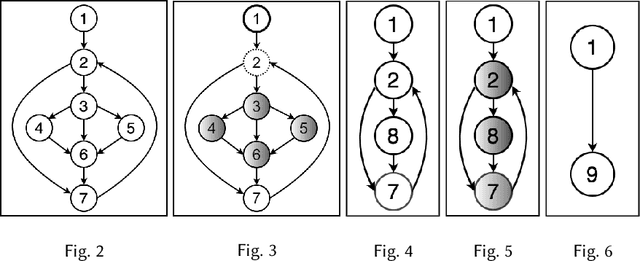
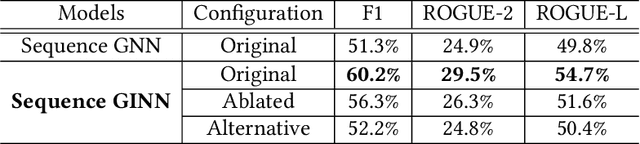
Learning distributed representations of source code has been a challenging task for machine learning models. Earlier works treated programs as text so that natural language methods can be readily applied. Unfortunately, such approaches do not capitalize on the rich structural information possessed by source code. Of late, Graph Neural Network (GNN) was proposed to learn embeddings of programs from their graph representations. Due to the homogeneous and expensive message-passing procedure, GNN can suffer from precision issues, especially when dealing with programs rendered into large graphs. In this paper, we present a new graph neural architecture, called Graph Interval Neural Network (GINN), to tackle the weaknesses of the existing GNN. Unlike the standard GNN, GINN generalizes from a curated graph representation obtained through an abstraction method designed to aid models to learn. In particular, GINN focuses exclusively on intervals for mining the feature representation of a program, furthermore, GINN operates on a hierarchy of intervals for scaling the learning to large graphs. We evaluate GINN for two popular downstream applications: variable misuse prediction and method name prediction. Results show in both cases GINN outperforms the state-of-the-art models by a comfortable margin. We have also created a neural bug detector based on GINN to catch null pointer deference bugs in Java code. While learning from the same 9,000 methods extracted from 64 projects, GINN-based bug detector significantly outperforms GNN-based bug detector on 13 unseen test projects. Next, we deploy our trained GINN-based bug detector and Facebook Infer to scan the codebase of 20 highly starred projects on GitHub. Through our manual inspection, we confirm 38 bugs out of 102 warnings raised by GINN-based bug detector compared to 34 bugs out of 129 warnings for Facebook Infer.
Learning a Static Bug Finder from Data
Jul 15, 2019
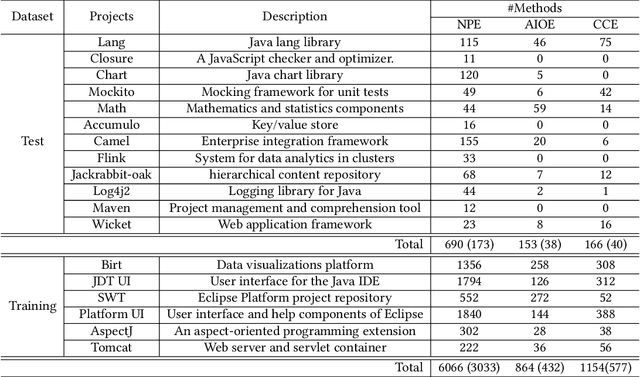
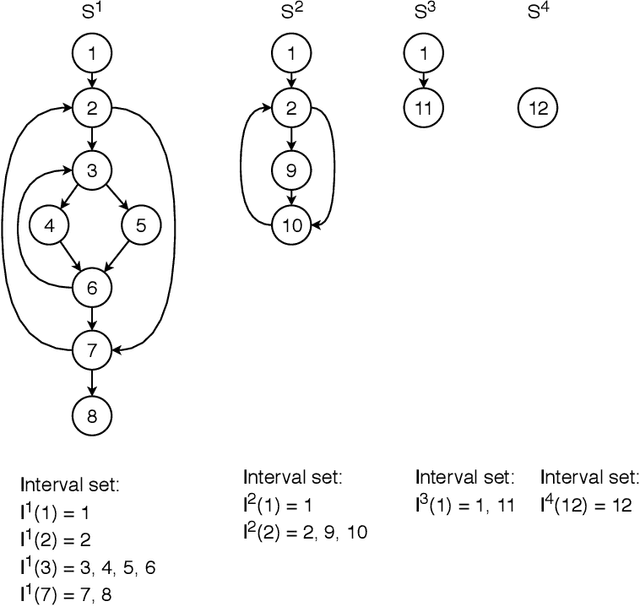
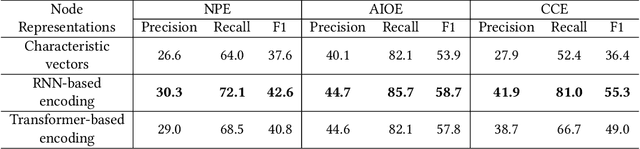
Static analysis is an effective technique to catch bugs early when they are easy to fix. Recent advances in program reasoning theory have led to increasing adoption of static analyzers in software engineering practice. Despite the significant progress, there is still potential for improvement. In this paper, we present an alternative approach to create static bug finders. Instead of relying on human expertise, we leverage deep neural networks-which have achieved groundbreaking results in a number of problem domains-to train a static analyzer directly from data. In particular, we frame the problem of bug finding as a classification task and train a classifier to differentiate the buggy from non-buggy programs using Gated Graph Neural Network (GGNN). In addition, we propose a novel interval-based propagation mechanism that significantly improves the generalization of GGNN on larger graphs. We have realized our approach into a framework, NeurSA, and extensively evaluated it. In a cross-project prediction task, three neural bug detectors we instantiate from NeurSA are highly precise in catching null pointer dereference, array index out of bound and class cast bugs in unseen code. A close comparison with Facebook Infer in catching null pointer dereference bugs reveals NeurSA to be far more precise in catching the real bugs and suppressing the spurious warnings. We are in active discussion with Visa Inc for possible adoption of NeurSA in their software development cycle. Due to the effectiveness and generality, we expect NeurSA to be helpful in improving the quality of their code base.