 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Efficient Policy Gradient Methods with Recursive Variance Reduction
Sep 18, 2019
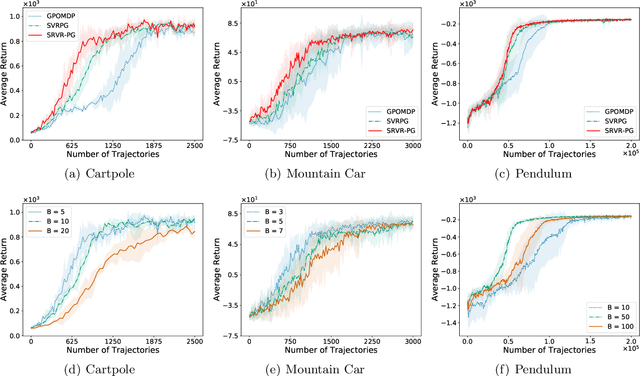
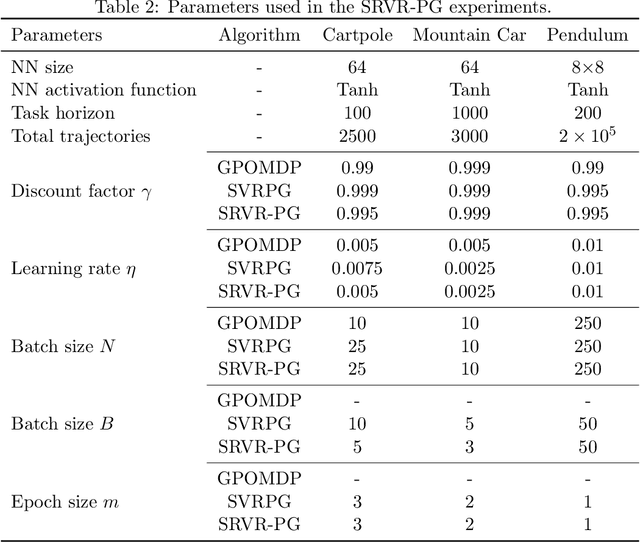
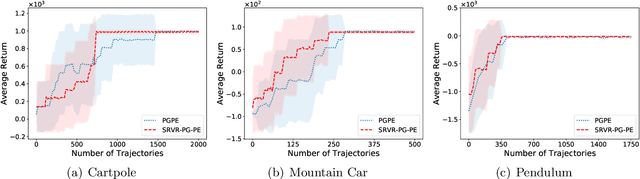
Improving the sample efficiency in reinforcement learning has been a long-standing research problem. In this work, we aim to reduce the sample complexity of existing policy gradient methods. We propose a novel policy gradient algorithm called SRVR-PG, which only requires $O(1/\epsilon^{3/2})$ episodes to find an $\epsilon$-approximate stationary point of the nonconcave performance function $J(\boldsymbol{\theta})$ (i.e., $\boldsymbol{\theta}$ such that $\|\nabla J(\boldsymbol{\theta})\|_2^2\leq\epsilon$). This sample complexity improves the best known result $O(1/\epsilon^{5/3})$ for policy gradient algorithms by a factor of $O(1/\epsilon^{1/6})$. In addition, we also propose a variant of SRVR-PG with parameter exploration, which explores the initial policy parameter from a prior probability distribution. We conduct numerical experiments on classic control problems in reinforcement learning to validate the performance of our proposed algorithms.
An Improved Convergence Analysis of Stochastic Variance-Reduced Policy Gradient
May 29, 2019
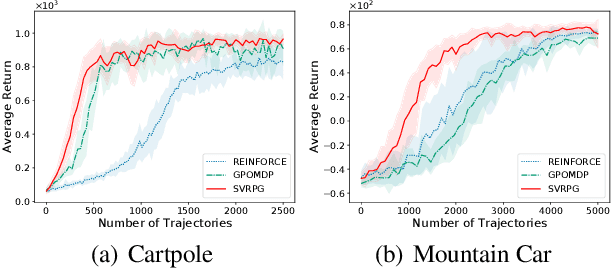
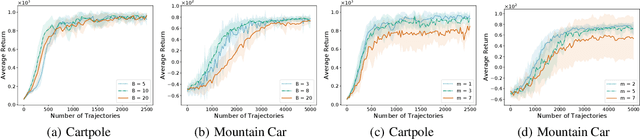
We revisit the stochastic variance-reduced policy gradient (SVRPG) method proposed by Papini et al. (2018) for reinforcement learning. We provide an improved convergence analysis of SVRPG and show that it can find an $\epsilon$-approximate stationary point of the performance function within $O(1/\epsilon^{5/3})$ trajectories. This sample complexity improves upon the best known result $O(1/\epsilon^2)$ by a factor of $O(1/\epsilon^{1/3})$. At the core of our analysis is (i) a tighter upper bound for the variance of importance sampling weights, where we prove that the variance can be controlled by the parameter distance between different policies; and (ii) a fine-grained analysis of the epoch length and batch size parameters such that we can significantly reduce the number of trajectories required in each iteration of SVRPG. We also empirically demonstrate the effectiveness of our theoretical claims of batch sizes on reinforcement learning benchmark tasks.