 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecPL: Disentangling Spectral Granularity for Prompt Learning
May 06, 2026Existing prompt learning for VLMs exhibits a modality asymmetry, predominantly optimizing text tokens while still relying on frozen visual encoder as holistic extractor and neglecting the spectral granularity essential for fine-grained discrimination. To bridge this, we introduce Disentangling Spectral Granularity for Prompt Learning (SpecPL), which approaches prompt learning from a novel spectral perspective via Counterfactual Granule Supervision. Specifically, we leverage a frozen VAE to decompose visual signals into semantic low-frequency bands and granular high-frequency details. A frozen Visual Semantic Bank anchors text representations to universal low-frequency invariants, mitigating overfitting. Crucially, fine-grained discrimination is driven by counterfactual granule training: by permuting high-frequency signals, we compel the model to explicitly distinguish visual granularity from semantic invariance. Uniquely, SpecPL serves as a universal plug-and-play booster, revitalizing text-oriented baselines like CoOp and MaPLe via visual-side guidance. Experiments on 11 benchmarks demonstrate competitive state-of-the-art performance, achieving a new performance ceiling of 81.51\% harmonic-mean accuracy. These results validate that spectral disentanglement with counterfactual supervision effectively bridges the gap in the stability-generalization trade-off. Code is released at https://github.com/Mlrac1e/SpecPL-Prompt-Learning.
OFCap:Object-aware Fusion for Image Captioning
Nov 27, 2024

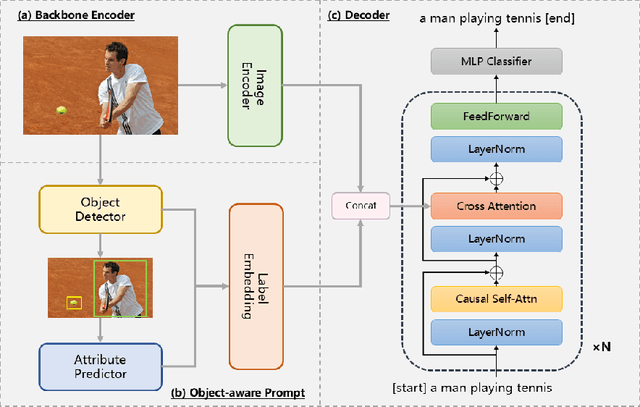
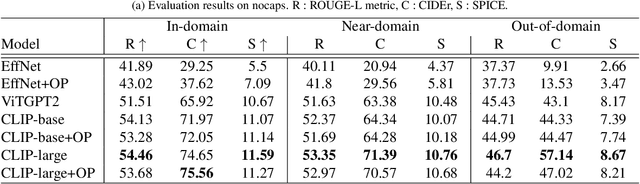
Image captioning is a technique that translates image content into natural language descriptions. Many application scenarios, such as intelligent search engines and assistive tools for visually impaired individuals, involve images containing people. As a result, datasets often have a high proportion of images featuring people. However, this data imbalance can lead to overfitting. The model may perform poorly when generating descriptions for images without people and may even produce irrelevant descriptions (hallucinations). To address this issue, increasing the diversity of the dataset could be an effective solution. However, acquiring high-quality image-text pairs is costly. Reducing overfitting without altering the dataset can significantly save resources. To tackle this challenge, we propose a target-aware prompting strategy. This method extracts object information from images using an object detector and integrates this information into the model through a fusion module. This helps the model generate descriptions with additional references (\textbf{OFCap}). Moreover, this strategy is model-agnostic. Pretrained models can be used with frozen parameters during training, further reducing computational costs. We conducted experiments on the COCO and nocpas datasets. The results demonstrate that this strategy effectively mitigates overfitting and significantly improves the quality of image descriptions.
ViTOC: Vision Transformer and Object-aware Captioner
Nov 13, 2024
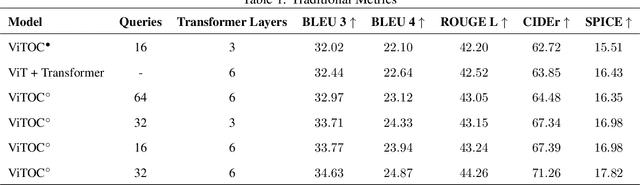
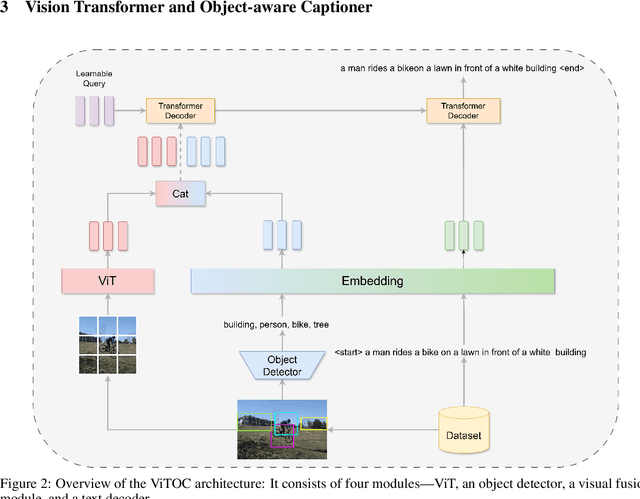
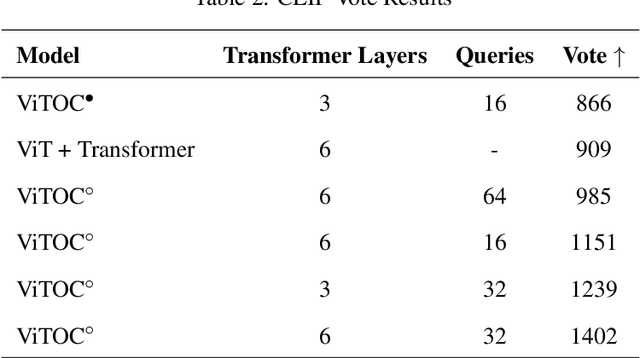
This paper presents ViTOC (Vision Transformer and Object-aware Captioner), a novel vision-language model for image captioning that addresses the challenges of accuracy and diversity in generated descriptions. Unlike conventional approaches, ViTOC employs a dual-path architecture based on Vision Transformer and object detector, effectively fusing global visual features and local object information through learnable vectors. The model introduces an innovative object-aware prompting strategy that significantly enhances its capability in handling long-tail data. Experiments on the standard COCO dataset demonstrate that ViTOC outperforms baseline models across all evaluation metrics. Additionally, we propose a reference-free evaluation method based on CLIP to further validate the model's effectiveness. By utilizing pretrained visual model parameters, ViTOC achieves efficient end-to-end training.