 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesized Policies for Transfer and Adaptation across Tasks and Environments
Apr 05, 2019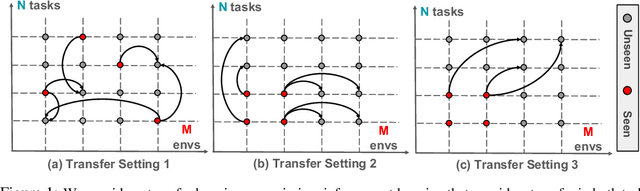

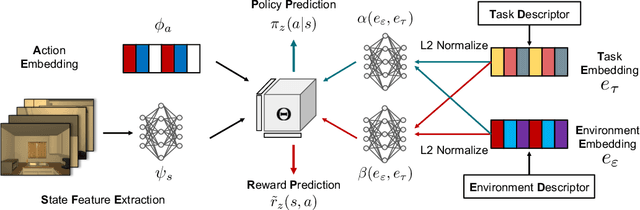

The ability to transfer in reinforcement learning is key towards building an agent of general artificial intelligence. In this paper, we consider the problem of learning to simultaneously transfer across both environments (ENV) and tasks (TASK), probably more importantly, by learning from only sparse (ENV, TASK) pairs out of all the possible combinations. We propose a novel compositional neural network architecture which depicts a meta rule for composing policies from the environment and task embeddings. Notably, one of the main challenges is to learn the embeddings jointly with the meta rule. We further propose new training methods to disentangle the embeddings, making them both distinctive signatures of the environments and tasks and effective building blocks for composing the policies. Experiments on GridWorld and Thor, of which the agent takes as input an egocentric view, show that our approach gives rise to high success rates on all the (ENV, TASK) pairs after learning from only 40\% of them.
Hyper-parameter Tuning under a Budget Constraint
Feb 01, 2019
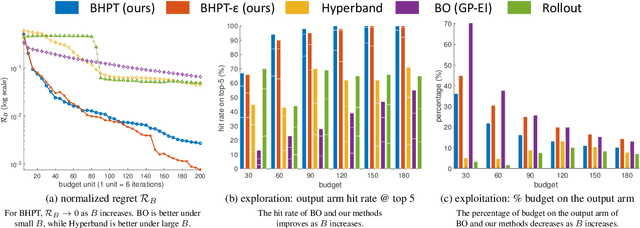
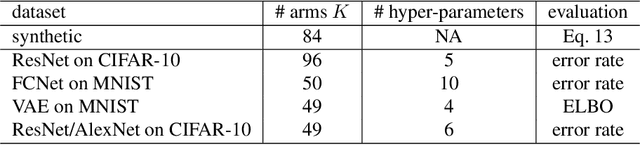
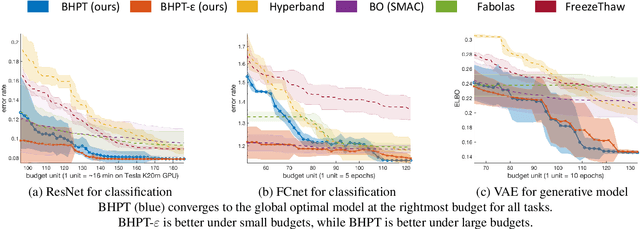
We study a budgeted hyper-parameter tuning problem, where we optimize the tuning result under a hard resource constraint. We propose to solve it as a sequential decision making problem, such that we can use the partial training progress of configurations to dynamically allocate the remaining budget. Our algorithm combines a Bayesian belief model which estimates the future performance of configurations, with an action-value function which balances exploration-exploitation tradeoff, to optimize the final output. It automatically adapts the tuning behaviors to different constraints, which is useful in practice. Experiment results demonstrate superior performance over existing algorithms, including the-state-of-the-art one, on real-world tuning tasks across a range of different budgets.
Learning Embedding Adaptation for Few-Shot Learning
Dec 16, 2018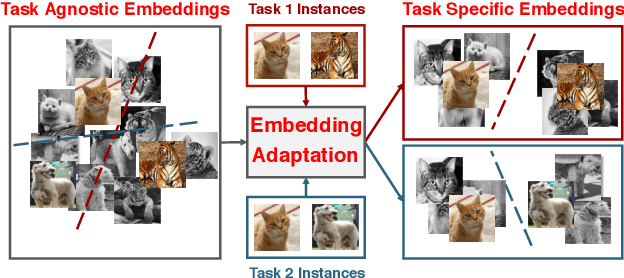
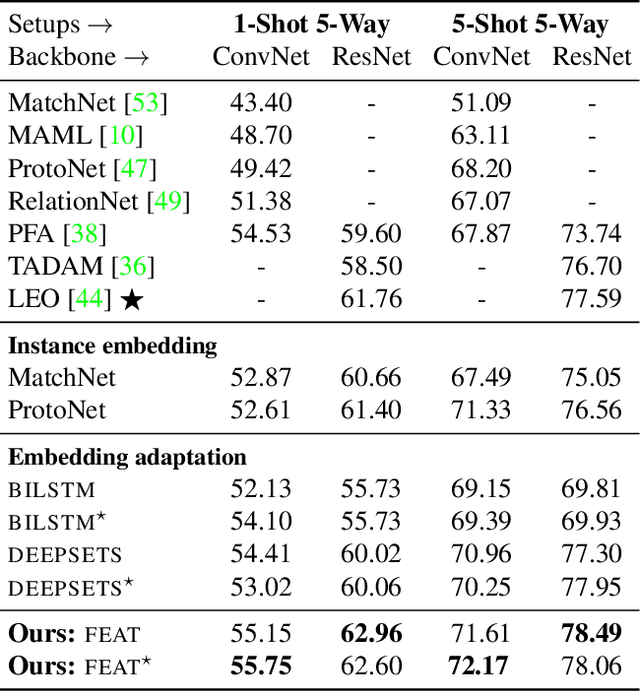
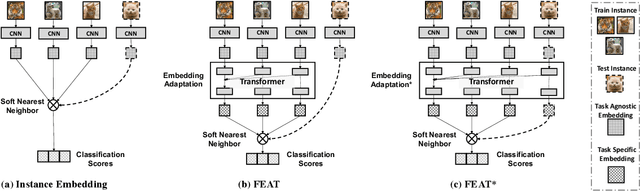
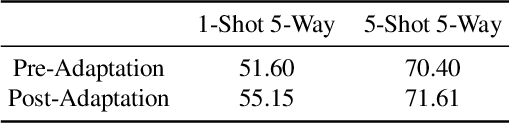
Learning with limited data is a key challenge for visual recognition. Few-shot learning methods address this challenge by learning an instance embedding function from seen classes and apply the function to instances from unseen classes with limited labels. This style of transfer learning is task-agnostic: the embedding function is not learned optimally discriminative with respect to the unseen classes, where discerning among them is the target task. In this paper, we propose a novel approach to adapt the embedding model to the target classification task, yielding embeddings that are task-specific and are discriminative. To this end, we employ a type of self-attention mechanism called Transformer to transform the embeddings from task-agnostic to task-specific by focusing on relating instances from the test instances to the training instances in both seen and unseen classes. Our approach also extends to both transductive and generalized few-shot classification, two important settings that have essential use cases. We verify the effectiveness of our model on two standard benchmark few-shot classification datasets --- MiniImageNet and CUB, where our approach demonstrates state-of-the-art empirical performance.
Classifier and Exemplar Synthesis for Zero-Shot Learning
Dec 16, 2018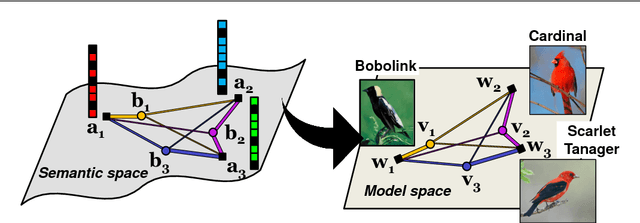
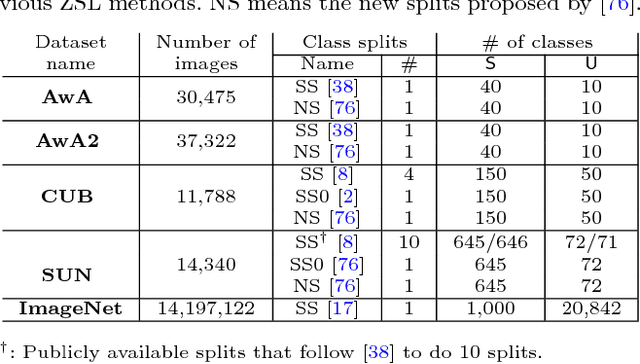
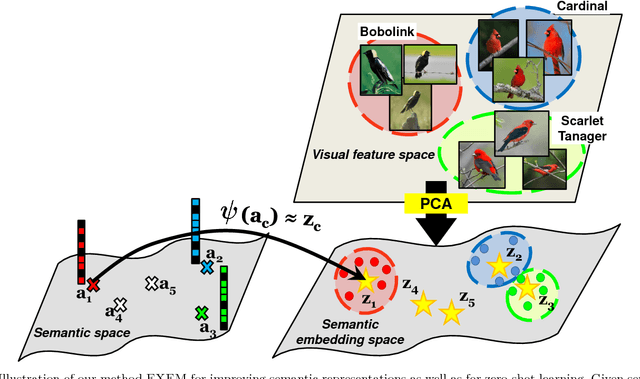
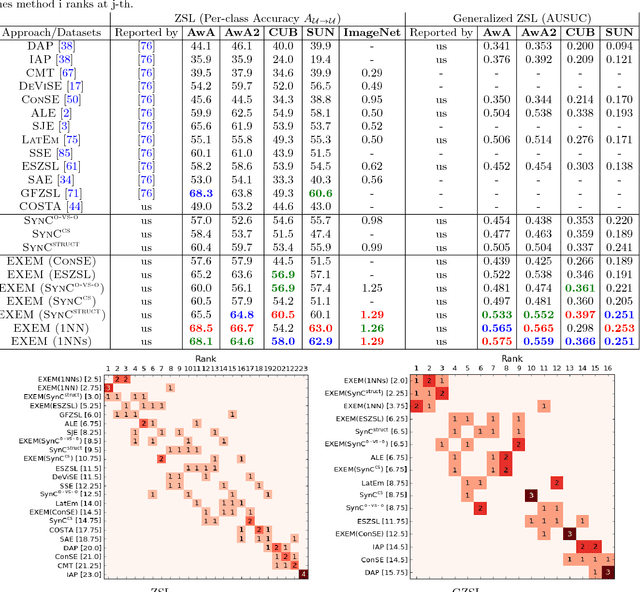
Zero-shot learning (ZSL) enables solving a task without the need to see its examples. In this paper, we propose two ZSL frameworks that learn to synthesize parameters for novel unseen classes. First, we propose to cast the problem of ZSL as learning manifold embeddings from graphs composed of object classes, leading to a flexible approach that synthesizes "classifiers" for the unseen classes. Then, we define an auxiliary task of synthesizing "exemplars" for the unseen classes to be used as an automatic denoising mechanism for any existing ZSL approaches or as an effective ZSL model by itself. On five visual recognition benchmark datasets, we demonstrate the superior performances of our proposed frameworks in various scenarios of both conventional and generalized ZSL. Finally, we provide valuable insights through a series of empirical analyses, among which are a comparison of semantic representations on the full ImageNet benchmark as well as a comparison of metrics used in generalized ZSL. Our code and data are publicly available at https://github.com/pujols/Zero-shot-learning-journal
Cross-Modal and Hierarchical Modeling of Video and Text
Oct 16, 2018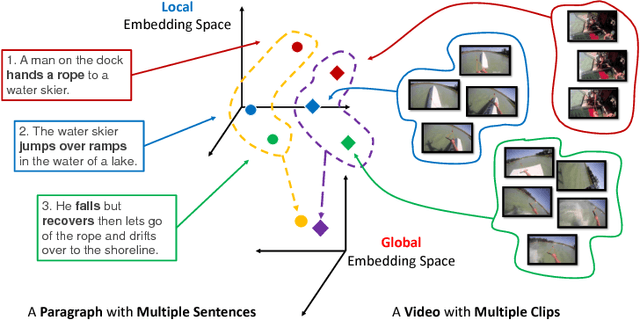
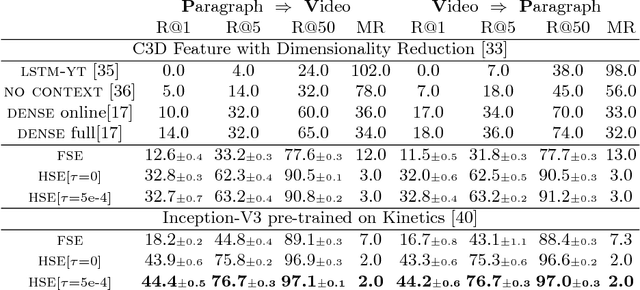
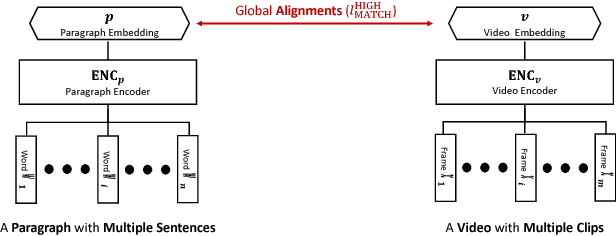
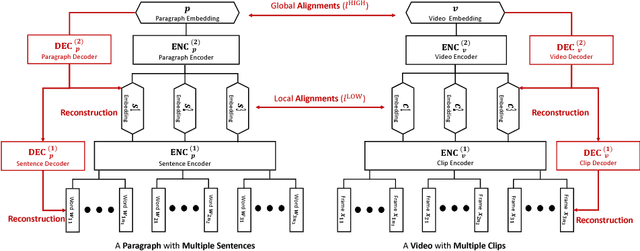
Visual data and text data are composed of information at multiple granularities. A video can describe a complex scene that is composed of multiple clips or shots, where each depicts a semantically coherent event or action. Similarly, a paragraph may contain sentences with different topics, which collectively conveys a coherent message or story. In this paper, we investigate the modeling techniques for such hierarchical sequential data where there are correspondences across multiple modalities. Specifically, we introduce hierarchical sequence embedding (HSE), a generic model for embedding sequential data of different modalities into hierarchically semantic spaces, with either explicit or implicit correspondence information. We perform empirical studies on large-scale video and paragraph retrieval datasets and demonstrated superior performance by the proposed methods. Furthermore, we examine the effectiveness of our learned embeddings when applied to downstream tasks. We show its utility in zero-shot action recognition and video captioning.
Aiming to Know You Better Perhaps Makes Me a More Engaging Dialogue Partner
Aug 21, 2018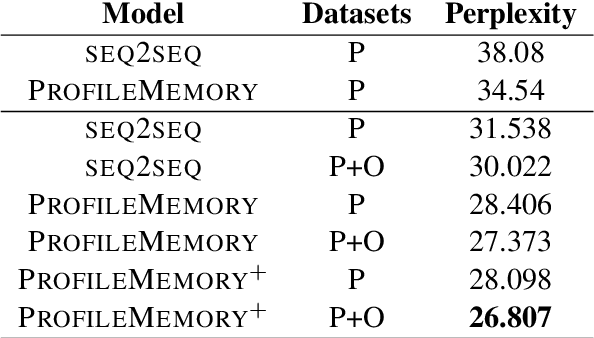
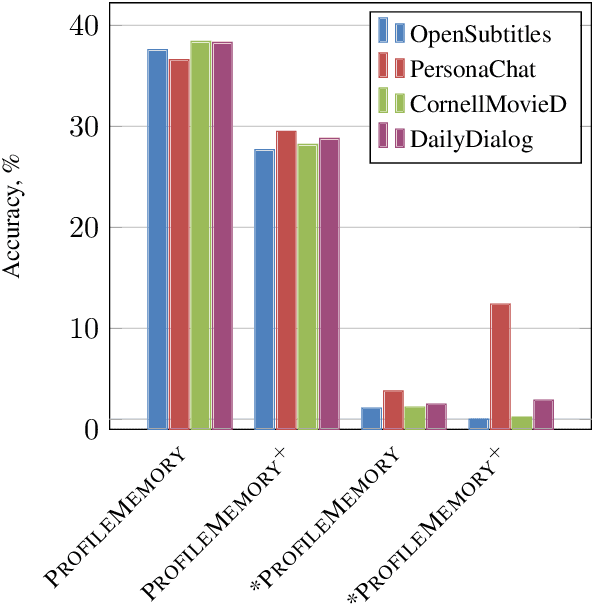

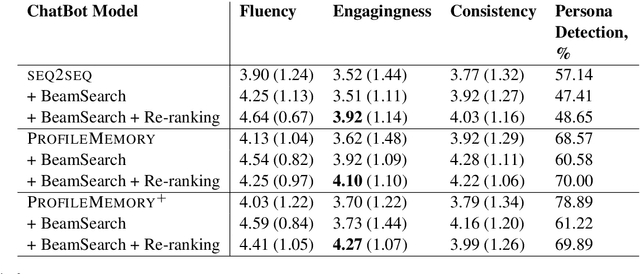
There have been several attempts to define a plausible motivation for a chit-chat dialogue agent that can lead to engaging conversations. In this work, we explore a new direction where the agent specifically focuses on discovering information about its interlocutor. We formalize this approach by defining a quantitative metric. We propose an algorithm for the agent to maximize it. We validate the idea with human evaluation where our system outperforms various baselines. We demonstrate that the metric indeed correlates with the human judgments of engagingness.
Multi-Task Learning for Sequence Tagging: An Empirical Study
Aug 13, 2018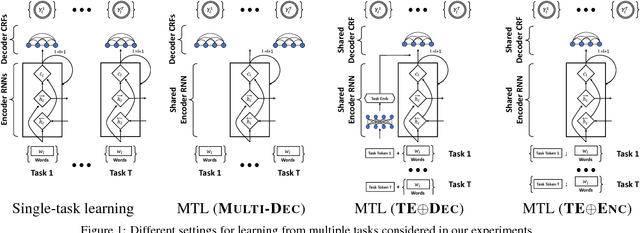
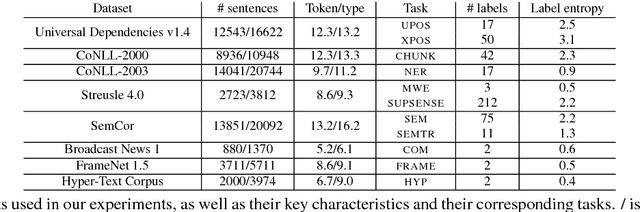

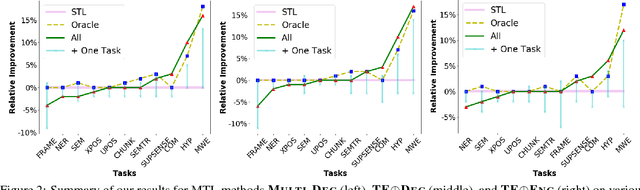
We study three general multi-task learning (MTL) approaches on 11 sequence tagging tasks. Our extensive empirical results show that in about 50% of the cases, jointly learning all 11 tasks improves upon either independent or pairwise learning of the tasks. We also show that pairwise MTL can inform us what tasks can benefit others or what tasks can be benefited if they are learned jointly. In particular, we identify tasks that can always benefit others as well as tasks that can always be harmed by others. Interestingly, one of our MTL approaches yields embeddings of the tasks that reveal the natural clustering of semantic and syntactic tasks. Our inquiries have opened the doors to further utilization of MTL in NLP.
Cross-Dataset Adaptation for Visual Question Answering
Jun 10, 2018
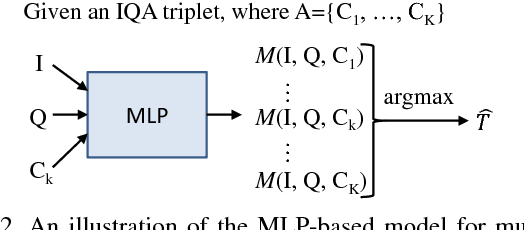
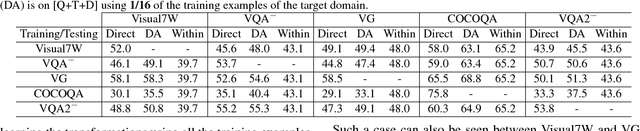
We investigate the problem of cross-dataset adaptation for visual question answering (Visual QA). Our goal is to train a Visual QA model on a source dataset but apply it to another target one. Analogous to domain adaptation for visual recognition, this setting is appealing when the target dataset does not have a sufficient amount of labeled data to learn an "in-domain" model. The key challenge is that the two datasets are constructed differently, resulting in the cross-dataset mismatch on images, questions, or answers. We overcome this difficulty by proposing a novel domain adaptation algorithm. Our method reduces the difference in statistical distributions by transforming the feature representation of the data in the target dataset. Moreover, it maximizes the likelihood of answering questions (in the target dataset) correctly using the Visual QA model trained on the source dataset. We empirically studied the effectiveness of the proposed approach on adapting among several popular Visual QA datasets. We show that the proposed method improves over baselines where there is no adaptation and several other adaptation methods. We both quantitatively and qualitatively analyze when the adaptation can be mostly effective.
Learning Answer Embeddings for Visual Question Answering
Jun 10, 2018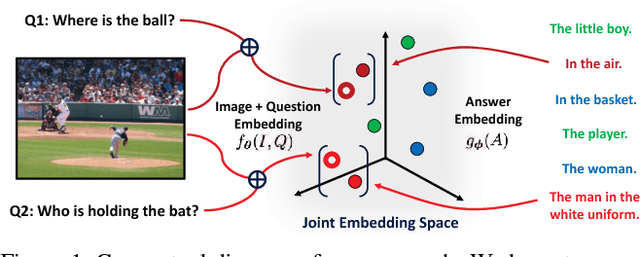
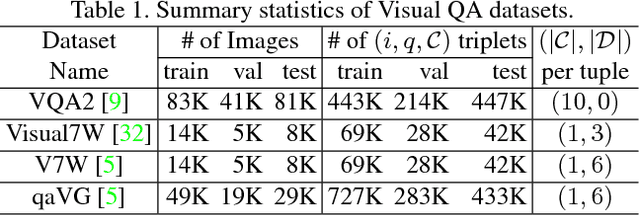
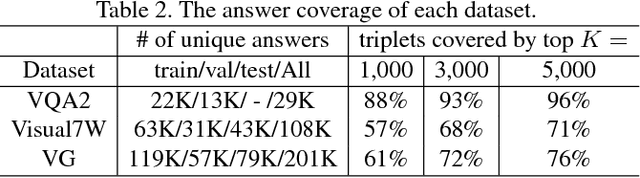
We propose a novel probabilistic model for visual question answering (Visual QA). The key idea is to infer two sets of embeddings: one for the image and the question jointly and the other for the answers. The learning objective is to learn the best parameterization of those embeddings such that the correct answer has higher likelihood among all possible answers. In contrast to several existing approaches of treating Visual QA as multi-way classification, the proposed approach takes the semantic relationships (as characterized by the embeddings) among answers into consideration, instead of viewing them as independent ordinal numbers. Thus, the learned embedded function can be used to embed unseen answers (in the training dataset). These properties make the approach particularly appealing for transfer learning for open-ended Visual QA, where the source dataset on which the model is learned has limited overlapping with the target dataset in the space of answers. We have also developed large-scale optimization techniques for applying the model to datasets with a large number of answers, where the challenge is to properly normalize the proposed probabilistic models. We validate our approach on several Visual QA datasets and investigate its utility for transferring models across datasets. The empirical results have shown that the approach performs well not only on in-domain learning but also on transfer learning.
Being Negative but Constructively: Lessons Learnt from Creating Better Visual Question Answering Datasets
Jun 10, 2018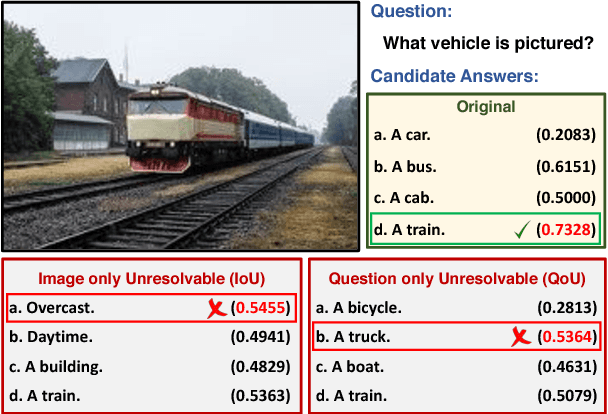
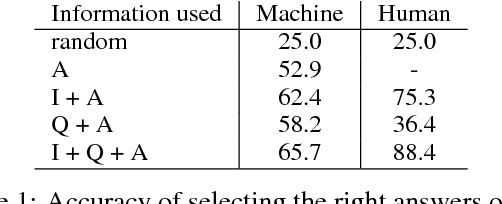
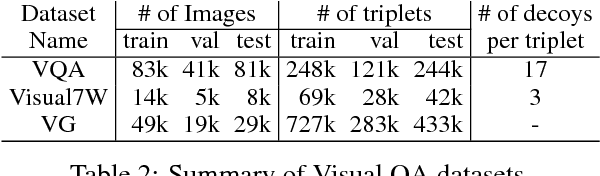

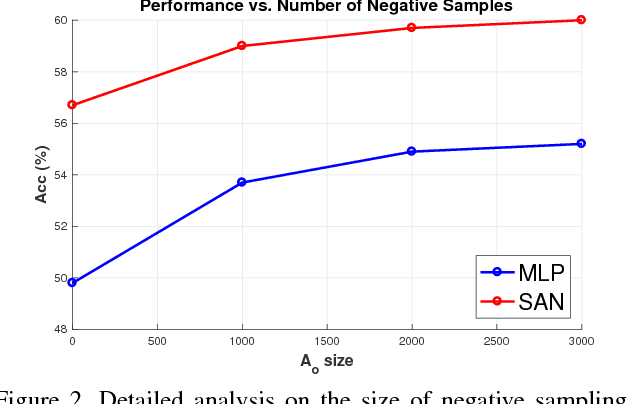
Visual question answering (Visual QA) has attracted a lot of attention lately, seen essentially as a form of (visual) Turing test that artificial intelligence should strive to achieve. In this paper, we study a crucial component of this task: how can we design good datasets for the task? We focus on the design of multiple-choice based datasets where the learner has to select the right answer from a set of candidate ones including the target (\ie the correct one) and the decoys (\ie the incorrect ones). Through careful analysis of the results attained by state-of-the-art learning models and human annotators on existing datasets, we show that the design of the decoy answers has a significant impact on how and what the learning models learn from the datasets. In particular, the resulting learner can ignore the visual information, the question, or both while still doing well on the task. Inspired by this, we propose automatic procedures to remedy such design deficiencies. We apply the procedures to re-construct decoy answers for two popular Visual QA datasets as well as to create a new Visual QA dataset from the Visual Genome project, resulting in the largest dataset for this task. Extensive empirical studies show that the design deficiencies have been alleviated in the remedied datasets and the performance on them is likely a more faithful indicator of the difference among learning models. The datasets are released and publicly available via http://www.teds.usc.edu/website_vqa/.