 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Network-based EEG Classification: A Survey
Oct 03, 2023



Graph neural networks (GNN) are increasingly used to classify EEG for tasks such as emotion recognition, motor imagery and neurological diseases and disorders. A wide range of methods have been proposed to design GNN-based classifiers. Therefore, there is a need for a systematic review and categorisation of these approaches. We exhaustively search the published literature on this topic and derive several categories for comparison. These categories highlight the similarities and differences among the methods. The results suggest a prevalence of spectral graph convolutional layers over spatial. Additionally, we identify standard forms of node features, with the most popular being the raw EEG signal and differential entropy. Our results summarise the emerging trends in GNN-based approaches for EEG classification. Finally, we discuss several promising research directions, such as exploring the potential of transfer learning methods and appropriate modelling of cross-frequency interactions.
Model-Free Market Risk Hedging Using Crowding Networks
Jun 13, 2023



Crowding is widely regarded as one of the most important risk factors in designing portfolio strategies. In this paper, we analyze stock crowding using network analysis of fund holdings, which is used to compute crowding scores for stocks. These scores are used to construct costless long-short portfolios, computed in a distribution-free (model-free) way and without using any numerical optimization, with desirable properties of hedge portfolios. More specifically, these long-short portfolios provide protection for both small and large market price fluctuations, due to their negative correlation with the market and positive convexity as a function of market returns. By adding our long-short portfolio to a baseline portfolio such as a traditional 60/40 portfolio, our method provides an alternative way to hedge portfolio risk including tail risk, which does not require costly option-based strategies or complex numerical optimization. The total cost of such hedging amounts to the total cost of rebalancing the hedge portfolio.
Adaptive Gated Graph Convolutional Network for Explainable Diagnosis of Alzheimer's Disease using EEG Data
Apr 12, 2023



Graph neural network (GNN) models are increasingly being used for the classification of electroencephalography (EEG) data. However, GNN-based diagnosis of neurological disorders, such as Alzheimer's disease (AD), remains a relatively unexplored area of research. Previous studies have relied on functional connectivity methods to infer brain graph structures and used simple GNN architectures for the diagnosis of AD. In this work, we propose a novel adaptive gated graph convolutional network (AGGCN) that can provide explainable predictions. AGGCN adaptively learns graph structures by combining convolution-based node feature enhancement with a well-known correlation-based measure of functional connectivity. Furthermore, the gated graph convolution can dynamically weigh the contribution of various spatial scales. The proposed model achieves high accuracy in both eyes-closed and eyes-open conditions, indicating the stability of learned representations. Finally, we demonstrate that the proposed AGGCN model generates consistent explanations of its predictions that might be relevant for further study of AD-related alterations of brain networks.
InsPro: Propagating Instance Query and Proposal for Online Video Instance Segmentation
Jan 05, 2023Video instance segmentation (VIS) aims at segmenting and tracking objects in videos. Prior methods typically generate frame-level or clip-level object instances first and then associate them by either additional tracking heads or complex instance matching algorithms. This explicit instance association approach increases system complexity and fails to fully exploit temporal cues in videos. In this paper, we design a simple, fast and yet effective query-based framework for online VIS. Relying on an instance query and proposal propagation mechanism with several specially developed components, this framework can perform accurate instance association implicitly. Specifically, we generate frame-level object instances based on a set of instance query-proposal pairs propagated from previous frames. This instance query-proposal pair is learned to bind with one specific object across frames through conscientiously developed strategies. When using such a pair to predict an object instance on the current frame, not only the generated instance is automatically associated with its precursors on previous frames, but the model gets a good prior for predicting the same object. In this way, we naturally achieve implicit instance association in parallel with segmentation and elegantly take advantage of temporal clues in videos. To show the effectiveness of our method InsPro, we evaluate it on two popular VIS benchmarks, i.e., YouTube-VIS 2019 and YouTube-VIS 2021. Without bells-and-whistles, our InsPro with ResNet-50 backbone achieves 43.2 AP and 37.6 AP on these two benchmarks respectively, outperforming all other online VIS methods.
Learning Disentangled Label Representations for Multi-label Classification
Dec 02, 2022



Although various methods have been proposed for multi-label classification, most approaches still follow the feature learning mechanism of the single-label (multi-class) classification, namely, learning a shared image feature to classify multiple labels. However, we find this One-shared-Feature-for-Multiple-Labels (OFML) mechanism is not conducive to learning discriminative label features and makes the model non-robustness. For the first time, we mathematically prove that the inferiority of the OFML mechanism is that the optimal learned image feature cannot maintain high similarities with multiple classifiers simultaneously in the context of minimizing cross-entropy loss. To address the limitations of the OFML mechanism, we introduce the One-specific-Feature-for-One-Label (OFOL) mechanism and propose a novel disentangled label feature learning (DLFL) framework to learn a disentangled representation for each label. The specificity of the framework lies in a feature disentangle module, which contains learnable semantic queries and a Semantic Spatial Cross-Attention (SSCA) module. Specifically, learnable semantic queries maintain semantic consistency between different images of the same label. The SSCA module localizes the label-related spatial regions and aggregates located region features into the corresponding label feature to achieve feature disentanglement. We achieve state-of-the-art performance on eight datasets of three tasks, \ie, multi-label classification, pedestrian attribute recognition, and continual multi-label learning.
QueryProp: Object Query Propagation for High-Performance Video Object Detection
Jul 22, 2022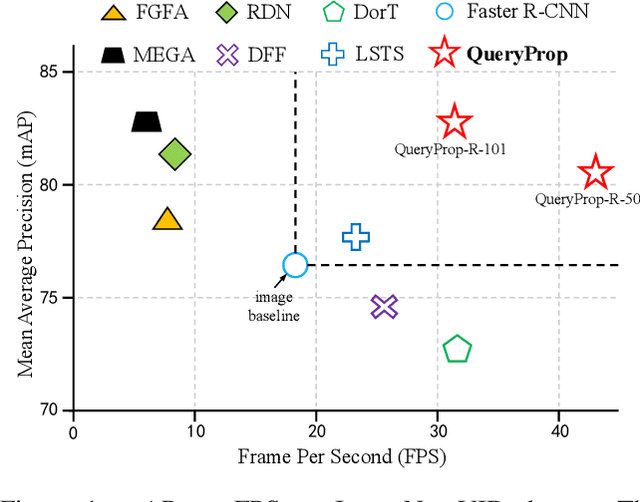
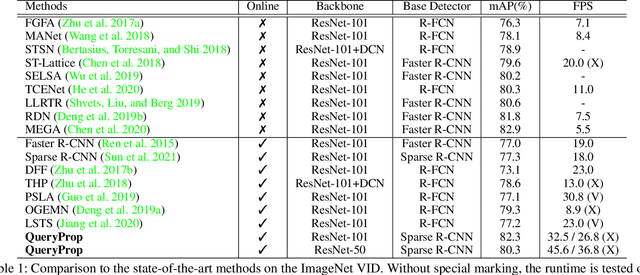
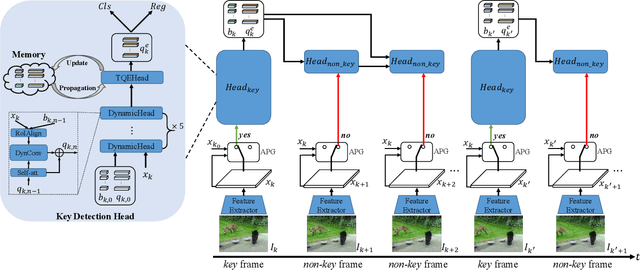
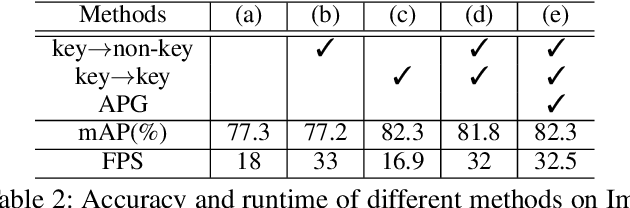
Video object detection has been an important yet challenging topic in computer vision. Traditional methods mainly focus on designing the image-level or box-level feature propagation strategies to exploit temporal information. This paper argues that with a more effective and efficient feature propagation framework, video object detectors can gain improvement in terms of both accuracy and speed. For this purpose, this paper studies object-level feature propagation, and proposes an object query propagation (QueryProp) framework for high-performance video object detection. The proposed QueryProp contains two propagation strategies: 1) query propagation is performed from sparse key frames to dense non-key frames to reduce the redundant computation on non-key frames; 2) query propagation is performed from previous key frames to the current key frame to improve feature representation by temporal context modeling. To further facilitate query propagation, an adaptive propagation gate is designed to achieve flexible key frame selection. We conduct extensive experiments on the ImageNet VID dataset. QueryProp achieves comparable accuracy with state-of-the-art methods and strikes a decent accuracy/speed trade-off. Code is available at https://github.com/hf1995/QueryProp.
Bispectrum-based Cross-frequency Functional Connectivity: Classification of Alzheimer's disease
Jun 10, 2022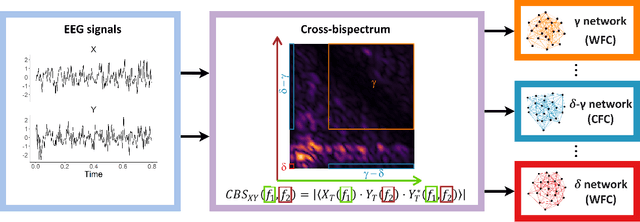
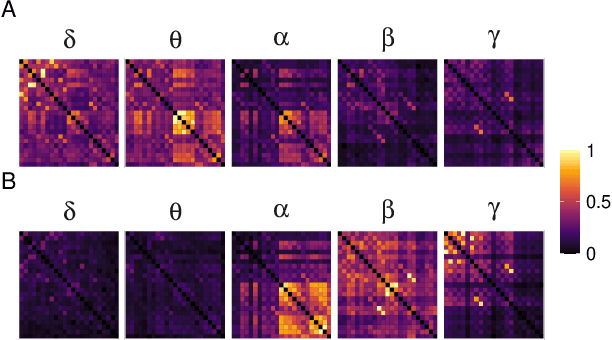
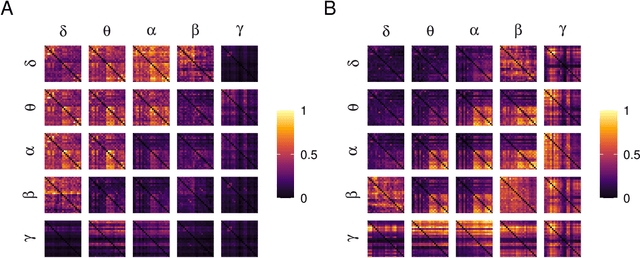
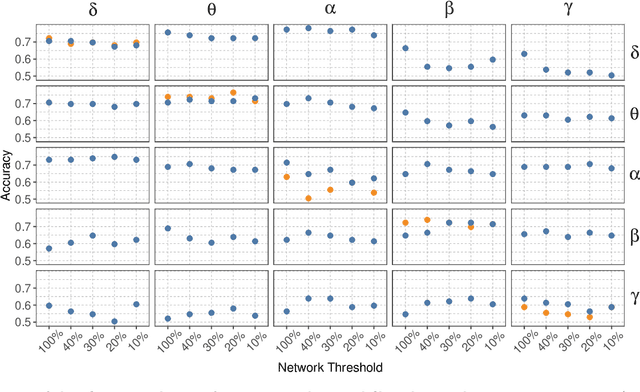
Alzheimer's disease (AD) is a neurodegenerative disease known to affect brain functional connectivity (FC). Linear FC measures have been applied to study the differences in AD by splitting neurophysiological signals such as electroencephalography (EEG) recordings into discrete frequency bands and analysing them in isolation. We address this limitation by quantifying cross-frequency FC in addition to the traditional within-band approach. Cross-bispectrum, a higher-order spectral analysis, is used to measure the nonlinear FC and is compared with the cross-spectrum, which only measures the linear FC within bands. Each frequency coupling is then used to construct an FC network, which is in turn vectorised and used to train a classifier. We show that fusing features from networks improves classification accuracy. Although both within-frequency and cross-frequency networks can be used to predict AD with high accuracy, our results show that bispectrum-based FC outperforms cross-spectrum suggesting an important role of cross-frequency FC.
PanopticDepth: A Unified Framework for Depth-aware Panoptic Segmentation
Jun 01, 2022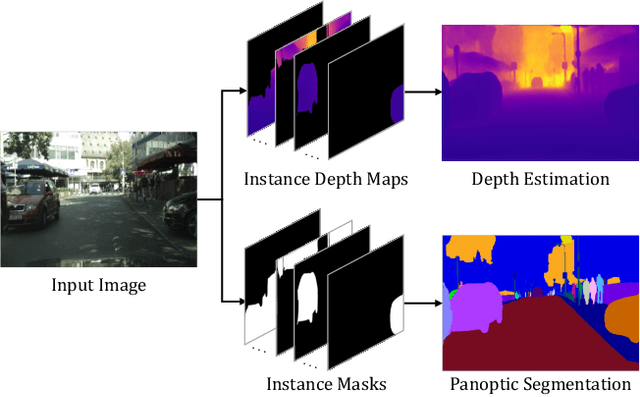
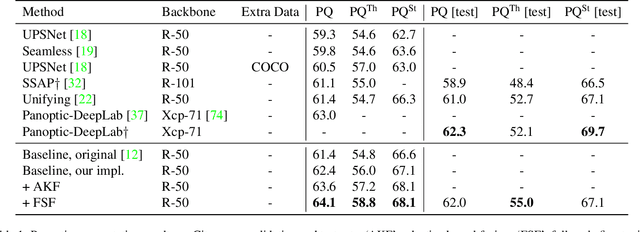
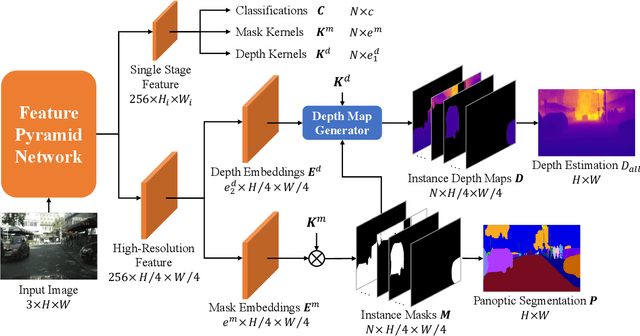

This paper presents a unified framework for depth-aware panoptic segmentation (DPS), which aims to reconstruct 3D scene with instance-level semantics from one single image. Prior works address this problem by simply adding a dense depth regression head to panoptic segmentation (PS) networks, resulting in two independent task branches. This neglects the mutually-beneficial relations between these two tasks, thus failing to exploit handy instance-level semantic cues to boost depth accuracy while also producing sub-optimal depth maps. To overcome these limitations, we propose a unified framework for the DPS task by applying a dynamic convolution technique to both the PS and depth prediction tasks. Specifically, instead of predicting depth for all pixels at a time, we generate instance-specific kernels to predict depth and segmentation masks for each instance. Moreover, leveraging the instance-wise depth estimation scheme, we add additional instance-level depth cues to assist with supervising the depth learning via a new depth loss. Extensive experiments on Cityscapes-DPS and SemKITTI-DPS show the effectiveness and promise of our method. We hope our unified solution to DPS can lead a new paradigm in this area. Code is available at https://github.com/NaiyuGao/PanopticDepth.
Multi-Phase Locking Value: A Generalized Method for Determining Instantaneous Multi-frequency Phase Coupling
Feb 20, 2021
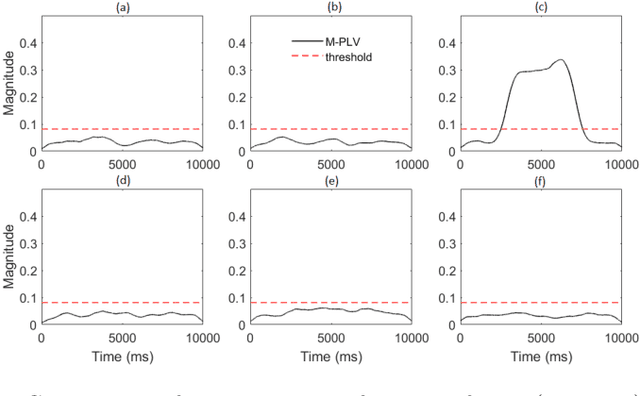
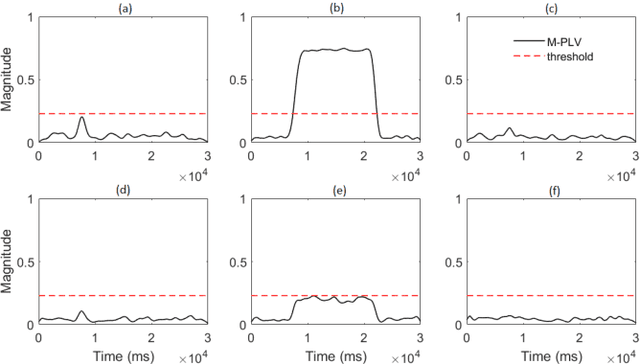
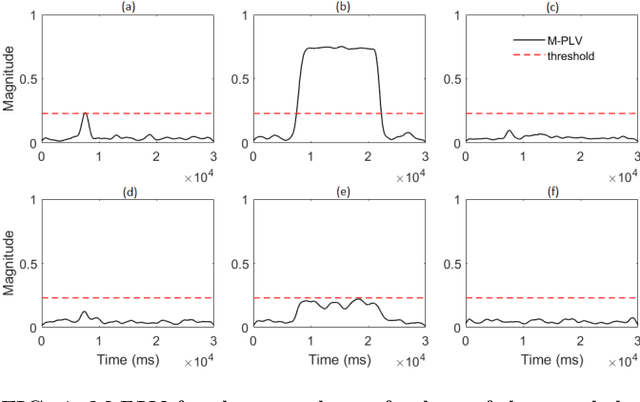
Many physical, biological and neural systems behave as coupled oscillators, with characteristic phase coupling across different frequencies. Methods such as $n:m$ phase locking value and bi-phase locking value have previously been proposed to quantify phase coupling between two resonant frequencies (e.g. $f$, $2f/3$) and across three frequencies (e.g. $f_1$, $f_2$, $f_1+f_2$), respectively. However, the existing phase coupling metrics have their limitations and limited applications. They cannot be used to detect or quantify phase coupling across multiple frequencies (e.g. $f_1$, $f_2$, $f_3$, $f_4$, $f_1+f_2+f_3-f_4$), or coupling that involves non-integer multiples of the frequencies (e.g. $f_1$, $f_2$, $2f_1/3+f_2/3$). To address the gap, this paper proposes a generalized approach, named multi-phase locking value (M-PLV), for the quantification of various types of instantaneous multi-frequency phase coupling. Different from most instantaneous phase coupling metrics that measure the simultaneous phase coupling, the proposed M-PLV method also allows the detection of delayed phase coupling and the associated time lag between coupled oscillators. The M-PLV has been tested on cases where synthetic coupled signals are generated using white Gaussian signals, and a system comprised of multiple coupled R\"ossler oscillators. Results indicate that the M-PLV can provide a reliable estimation of the time window and frequency combination where the phase coupling is significant, as well as a precise determination of time lag in the case of delayed coupling. This method has the potential to become a powerful new tool for exploring phase coupling in complex nonlinear dynamic systems.
Characterising Alzheimer's Disease with EEG-based Energy Landscape Analysis
Feb 19, 2021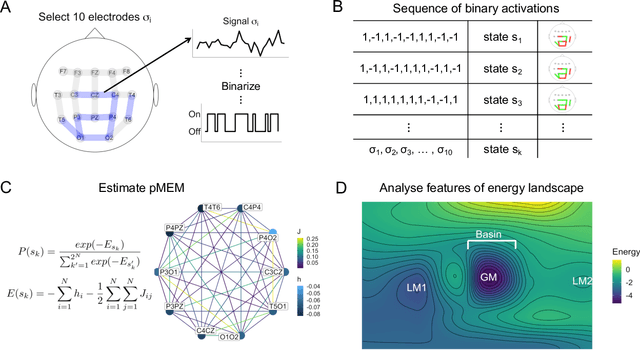

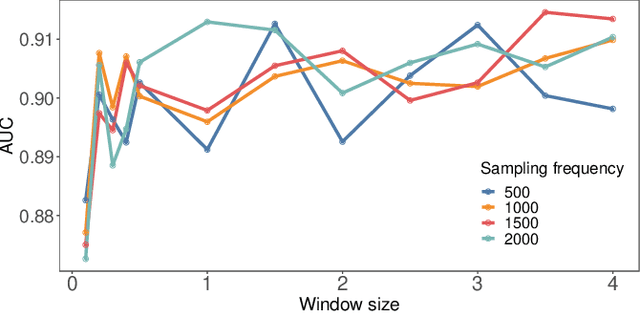
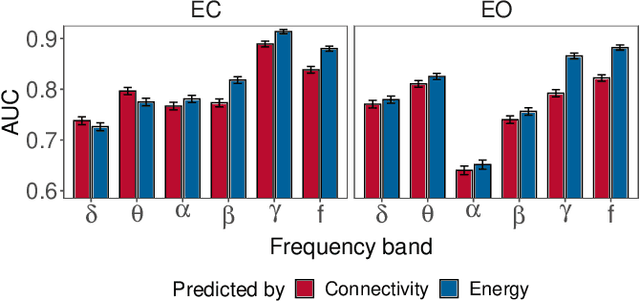
Alzheimer's disease (AD) is one of the most common neurodegenerative diseases, with around 50 million patients worldwide. Accessible and non-invasive methods of diagnosing and characterising AD are therefore urgently required. Electroencephalography (EEG) fulfils these criteria and is often used when studying AD. Several features derived from EEG were shown to predict AD with high accuracy, e.g. signal complexity and synchronisation. However, the dynamics of how the brain transitions between stable states have not been properly studied in the case of AD and EEG data. Energy landscape analysis is a method that can be used to quantify these dynamics. This work presents the first application of this method to both AD and EEG. Energy landscape assigns energy value to each possible state, i.e. pattern of activations across brain regions. The energy is inversely proportional to the probability of occurrence. By studying the features of energy landscapes of 20 AD patients and 20 healthy age-matched counterparts, significant differences were found. The dynamics of AD patients' brain networks were shown to be more constrained - with more local minima, less variation in basin size, and smaller basins. We show that energy landscapes can predict AD with high accuracy, performing significantly better than baseline models.