 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring LLMs for South Asian Music Understanding and Generation
Jun 03, 2026Recent advancements in Large Language Models (LLMs) have shown promising results in music understanding and generation tasks. However, existing works remain confined to Western tonal traditions, offering little insight into whether current LLMs can handle structurally distinct low-resource musical traditions. We present the first systematic evaluation of LLM competence in South Asian classical music, a tradition governed by raga, tala-based melodic constraints that impose fundamentally different structural principles from Western harmony-driven music. We ground our evaluation in Hindustani classical theory and Bengali classical forms, including Rabindra and Nazrul Sangeet -- representative low-resource traditions within South Asian classical music. For music understanding evaluation, we introduce a 504-question-answer benchmark spanning raga grammar, cultural knowledge, and symbolic notation reasoning, evaluating 33 LLMs where frontier models such as Gemini 2.5 Pro achieve 85-90% accuracy, while most open-source models remain in the 23-40% range. For music generation, we design a five-level controlled prompting framework and find that even the strongest model produces stylistically faithful outputs only 40% of the time. These results reveal that structural validity and stylistic faithfulness in music generation are distinct objectives and highlight an open challenge for culturally grounded music modeling.
"When Words Fail, Emojis Prevail": Generating Sarcastic Utterances with Emoji Using Valence Reversal and Semantic Incongruity
May 06, 2023



Sarcasm pertains to the subtle form of language that individuals use to express the opposite of what is implied. We present a novel architecture for sarcasm generation with emoji from a non-sarcastic input sentence. We divide the generation task into two sub tasks: one for generating textual sarcasm and another for collecting emojis associated with those sarcastic sentences. Two key elements of sarcasm are incorporated into the textual sarcasm generation task: valence reversal and semantic incongruity with context, where the context may involve shared commonsense or general knowledge between the speaker and their audience. The majority of existing sarcasm generation works have focused on this textual form. However, in the real world, when written texts fall short of effectively capturing the emotional cues of spoken and face-to-face communication, people often opt for emojis to accurately express their emotions. Due to the wide range of applications of emojis, incorporating appropriate emojis to generate textual sarcastic sentences helps advance sarcasm generation. We conclude our study by evaluating the generated sarcastic sentences using human judgement. All the codes and data used in this study will be made publicly available.
Computational Sarcasm Analysis on Social Media: A Systematic Review
Sep 20, 2022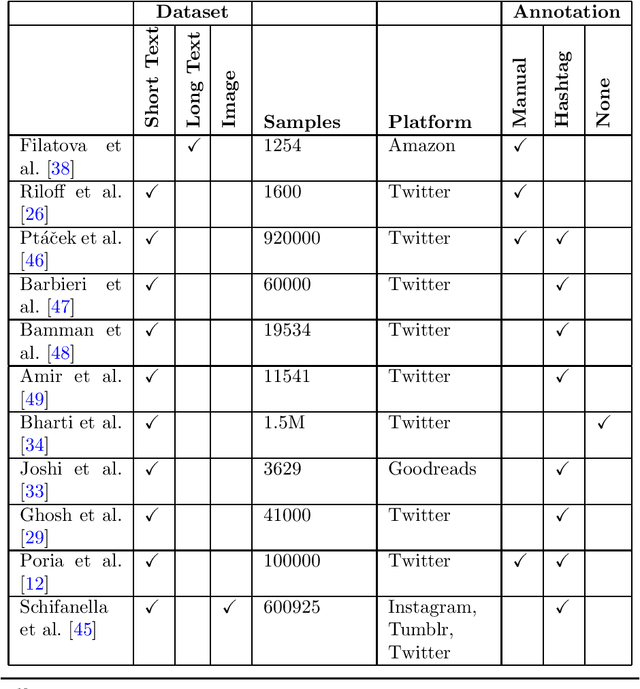
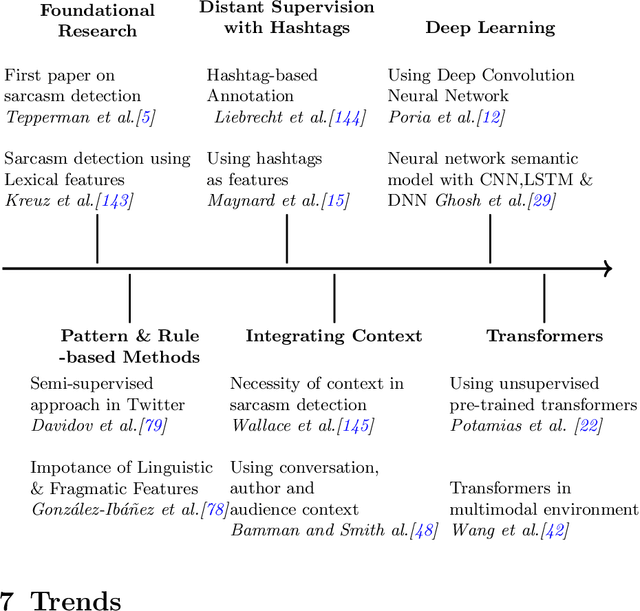
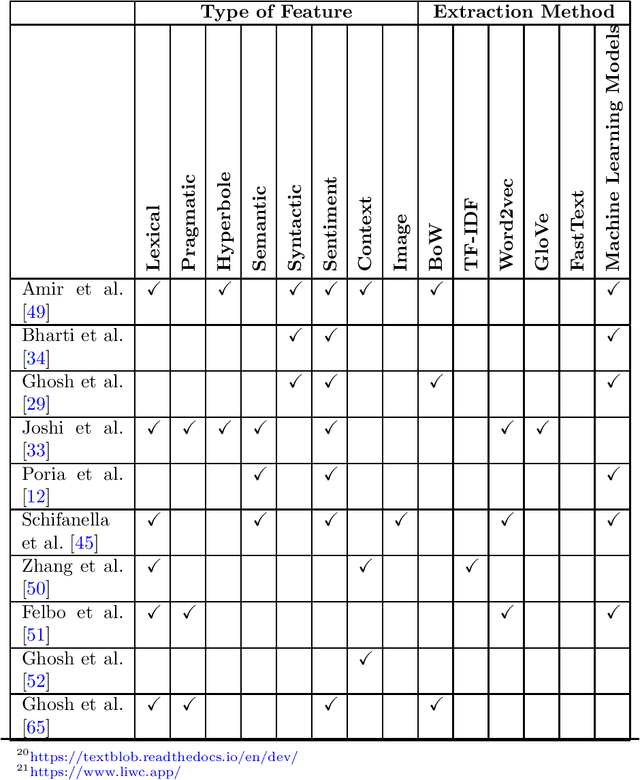
Sarcasm can be defined as saying or writing the opposite of what one truly wants to express, usually to insult, irritate, or amuse someone. Because of the obscure nature of sarcasm in textual data, detecting it is difficult and of great interest to the sentiment analysis research community. Though the research in sarcasm detection spans more than a decade, some significant advancements have been made recently, including employing unsupervised pre-trained transformers in multimodal environments and integrating context to identify sarcasm. In this study, we aim to provide a brief overview of recent advancements and trends in computational sarcasm research for the English language. We describe relevant datasets, methodologies, trends, issues, challenges, and tasks relating to sarcasm that are beyond detection. Our study provides well-summarized tables of sarcasm datasets, sarcastic features and their extraction methods, and performance analysis of various approaches which can help researchers in related domains understand current state-of-the-art practices in sarcasm detection.