 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-level Feature Alignment for Versatile Image Translation and Manipulation
Jul 07, 2021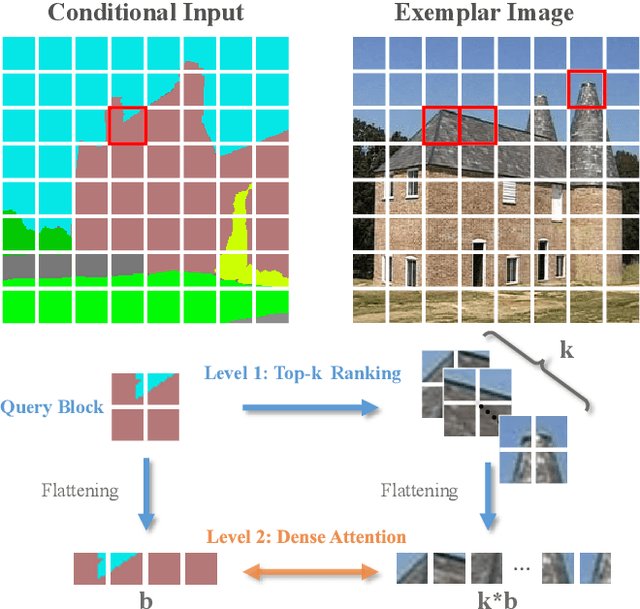
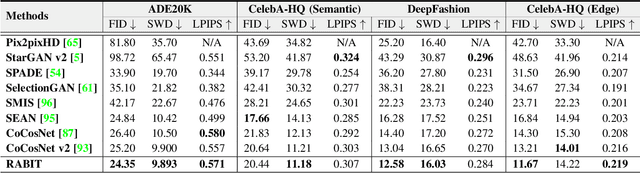
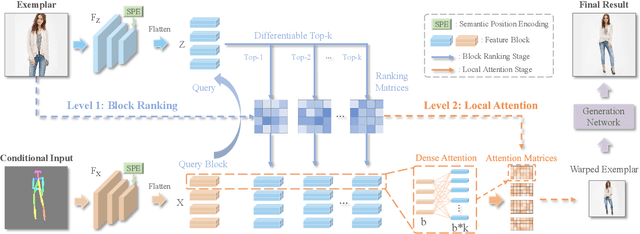
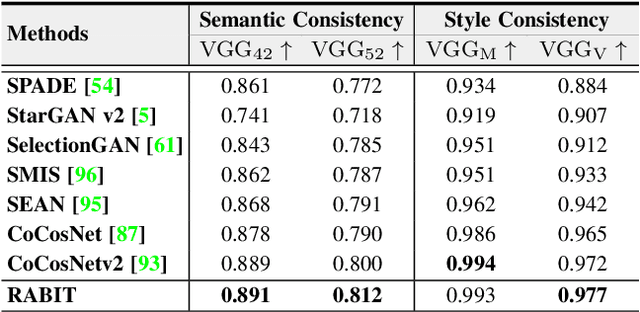
Generative adversarial networks (GANs) have achieved great success in image translation and manipulation. However, high-fidelity image generation with faithful style control remains a grand challenge in computer vision. This paper presents a versatile image translation and manipulation framework that achieves accurate semantic and style guidance in image generation by explicitly building a correspondence. To handle the quadratic complexity incurred by building the dense correspondences, we introduce a bi-level feature alignment strategy that adopts a top-$k$ operation to rank block-wise features followed by dense attention between block features which reduces memory cost substantially. As the top-$k$ operation involves index swapping which precludes the gradient propagation, we propose to approximate the non-differentiable top-$k$ operation with a regularized earth mover's problem so that its gradient can be effectively back-propagated. In addition, we design a novel semantic position encoding mechanism that builds up coordinate for each individual semantic region to preserve texture structures while building correspondences. Further, we design a novel confidence feature injection module which mitigates mismatch problem by fusing features adaptively according to the reliability of built correspondences. Extensive experiments show that our method achieves superior performance qualitatively and quantitatively as compared with the state-of-the-art. The code is available at \href{https://github.com/fnzhan/RABIT}{https://github.com/fnzhan/RABIT}.
Blind Image Super-Resolution via Contrastive Representation Learning
Jul 01, 2021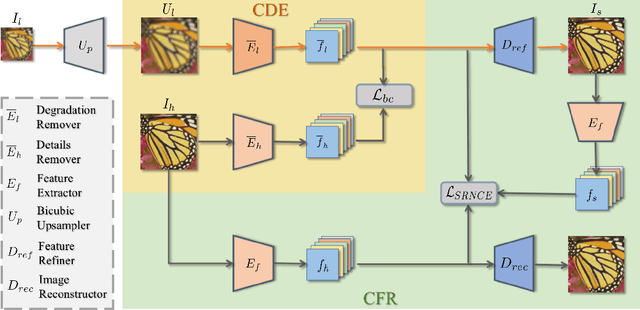

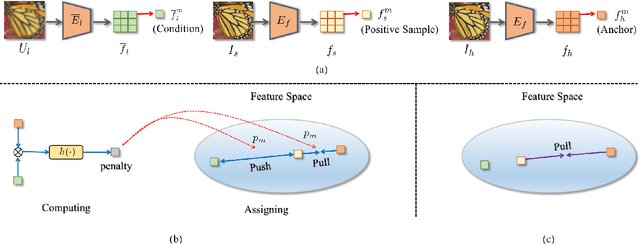
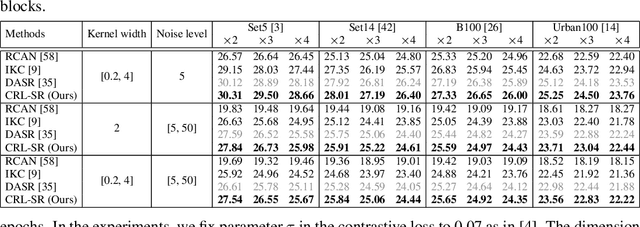
Image super-resolution (SR) research has witnessed impressive progress thanks to the advance of convolutional neural networks (CNNs) in recent years. However, most existing SR methods are non-blind and assume that degradation has a single fixed and known distribution (e.g., bicubic) which struggle while handling degradation in real-world data that usually follows a multi-modal, spatially variant, and unknown distribution. The recent blind SR studies address this issue via degradation estimation, but they do not generalize well to multi-source degradation and cannot handle spatially variant degradation. We design CRL-SR, a contrastive representation learning network that focuses on blind SR of images with multi-modal and spatially variant distributions. CRL-SR addresses the blind SR challenges from two perspectives. The first is contrastive decoupling encoding which introduces contrastive learning to extract resolution-invariant embedding and discard resolution-variant embedding under the guidance of a bidirectional contrastive loss. The second is contrastive feature refinement which generates lost or corrupted high-frequency details under the guidance of a conditional contrastive loss. Extensive experiments on synthetic datasets and real images show that the proposed CRL-SR can handle multi-modal and spatially variant degradation effectively under blind settings and it also outperforms state-of-the-art SR methods qualitatively and quantitatively.
Sparse Needlets for Lighting Estimation with Spherical Transport Loss
Jun 24, 2021

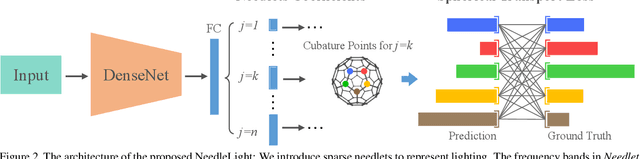
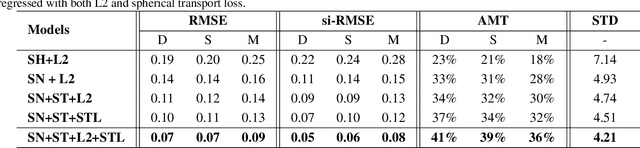
Accurate lighting estimation is challenging yet critical to many computer vision and computer graphics tasks such as high-dynamic-range (HDR) relighting. Existing approaches model lighting in either frequency domain or spatial domain which is insufficient to represent the complex lighting conditions in scenes and tends to produce inaccurate estimation. This paper presents NeedleLight, a new lighting estimation model that represents illumination with needlets and allows lighting estimation in both frequency domain and spatial domain jointly. An optimal thresholding function is designed to achieve sparse needlets which trims redundant lighting parameters and demonstrates superior localization properties for illumination representation. In addition, a novel spherical transport loss is designed based on optimal transport theory which guides to regress lighting representation parameters with consideration of the spatial information. Furthermore, we propose a new metric that is concise yet effective by directly evaluating the estimated illumination maps rather than rendered images. Extensive experiments show that NeedleLight achieves superior lighting estimation consistently across multiple evaluation metrics as compared with state-of-the-art methods.
Unbalanced Feature Transport for Exemplar-based Image Translation
Jun 19, 2021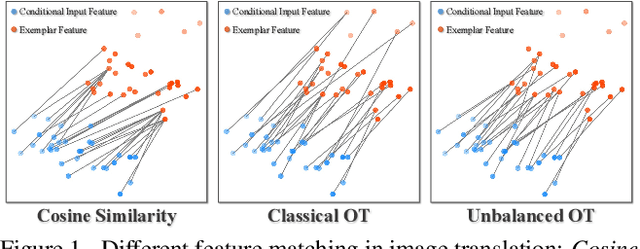
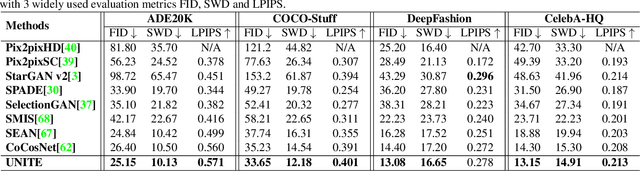
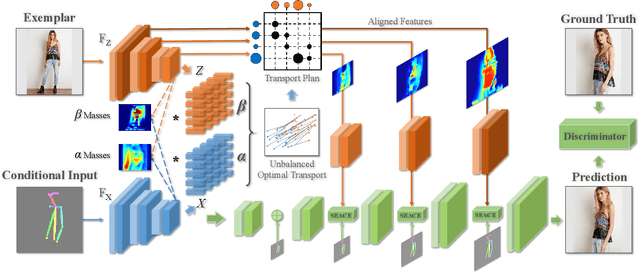
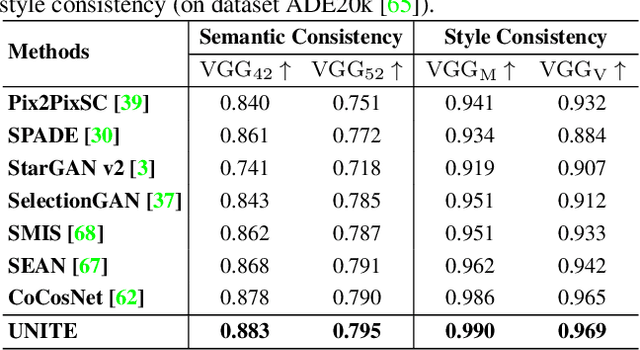
Despite the great success of GANs in images translation with different conditioned inputs such as semantic segmentation and edge maps, generating high-fidelity realistic images with reference styles remains a grand challenge in conditional image-to-image translation. This paper presents a general image translation framework that incorporates optimal transport for feature alignment between conditional inputs and style exemplars in image translation. The introduction of optimal transport mitigates the constraint of many-to-one feature matching significantly while building up accurate semantic correspondences between conditional inputs and exemplars. We design a novel unbalanced optimal transport to address the transport between features with deviational distributions which exists widely between conditional inputs and exemplars. In addition, we design a semantic-activation normalization scheme that injects style features of exemplars into the image translation process successfully. Extensive experiments over multiple image translation tasks show that our method achieves superior image translation qualitatively and quantitatively as compared with the state-of-the-art.
Diverse Image Inpainting with Bidirectional and Autoregressive Transformers
Apr 30, 2021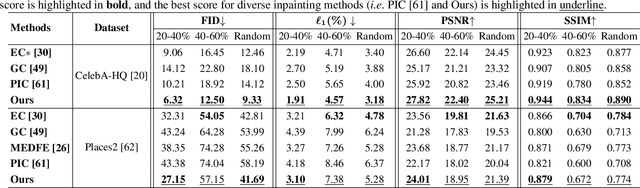
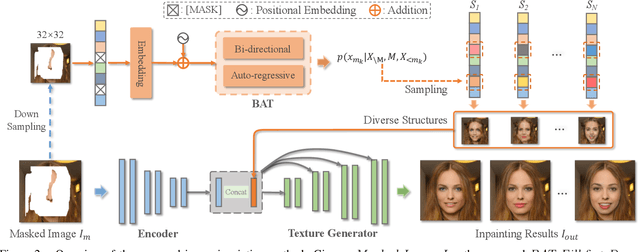
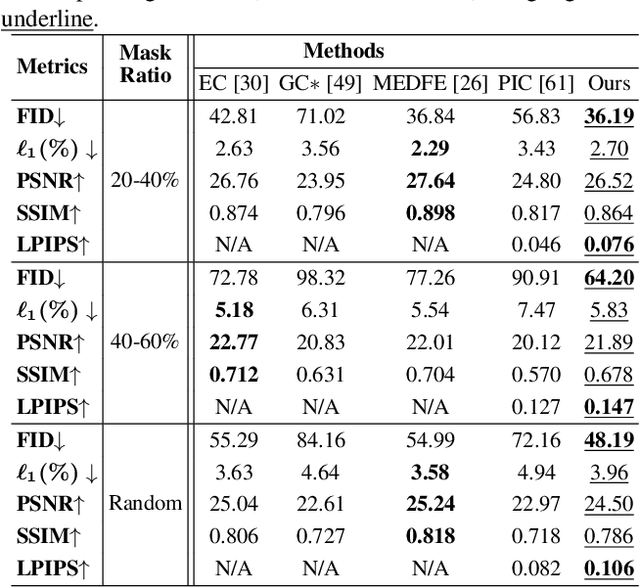
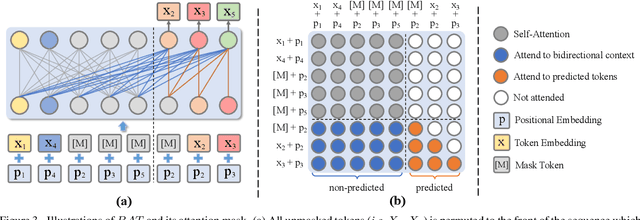
Image inpainting is an underdetermined inverse problem, it naturally allows diverse contents that fill up the missing or corrupted regions reasonably and realistically. Prevalent approaches using convolutional neural networks (CNNs) can synthesize visually pleasant contents, but CNNs suffer from limited perception fields for capturing global features. With image-level attention, transformers enable to model long-range dependencies and generate diverse contents with autoregressive modeling of pixel-sequence distributions. However, the unidirectional attention in transformers is suboptimal as corrupted regions can have arbitrary shapes with contexts from arbitrary directions. We propose BAT-Fill, an image inpainting framework with a novel bidirectional autoregressive transformer (BAT) that models deep bidirectional contexts for autoregressive generation of diverse inpainting contents. BAT-Fill inherits the merits of transformers and CNNs in a two-stage manner, which allows to generate high-resolution contents without being constrained by the quadratic complexity of attention in transformers. Specifically, it first generates pluralistic image structures of low resolution by adapting transformers and then synthesizes realistic texture details of high resolutions with a CNN-based up-sampling network. Extensive experiments over multiple datasets show that BAT-Fill achieves superior diversity and fidelity in image inpainting qualitatively and quantitatively.
Deep Monocular 3D Human Pose Estimation via Cascaded Dimension-Lifting
Apr 08, 2021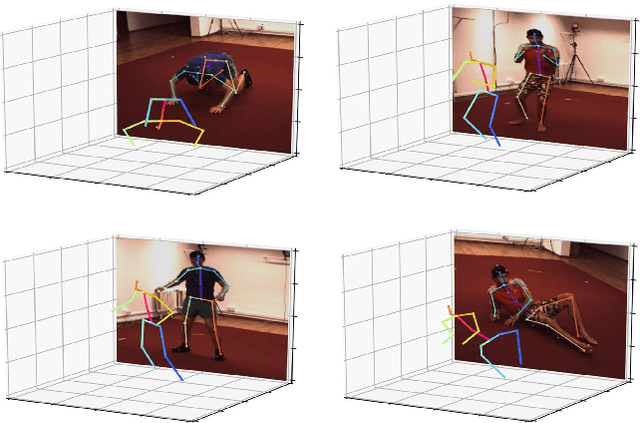
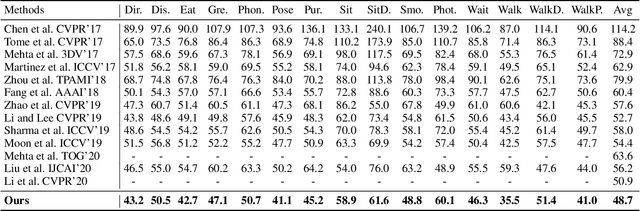
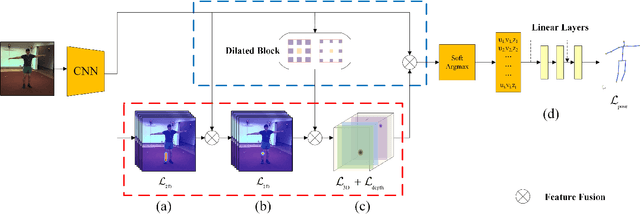
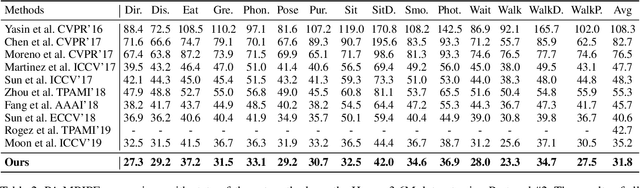
The 3D pose estimation from a single image is a challenging problem due to depth ambiguity. One type of the previous methods lifts 2D joints, obtained by resorting to external 2D pose detectors, to the 3D space. However, this type of approaches discards the contextual information of images which are strong cues for 3D pose estimation. Meanwhile, some other methods predict the joints directly from monocular images but adopt a 2.5D output representation $P^{2.5D} = (u,v,z^{r}) $ where both $u$ and $v$ are in the image space but $z^{r}$ in root-relative 3D space. Thus, the ground-truth information (e.g., the depth of root joint from the camera) is normally utilized to transform the 2.5D output to the 3D space, which limits the applicability in practice. In this work, we propose a novel end-to-end framework that not only exploits the contextual information but also produces the output directly in the 3D space via cascaded dimension-lifting. Specifically, we decompose the task of lifting pose from 2D image space to 3D spatial space into several sequential sub-tasks, 1) kinematic skeletons \& individual joints estimation in 2D space, 2) root-relative depth estimation, and 3) lifting to the 3D space, each of which employs direct supervisions and contextual image features to guide the learning process. Extensive experiments show that the proposed framework achieves state-of-the-art performance on two widely used 3D human pose datasets (Human3.6M, MuPoTS-3D).
GMLight: Lighting Estimation via Geometric Distribution Approximation
Feb 20, 2021
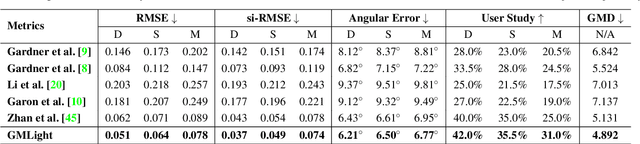
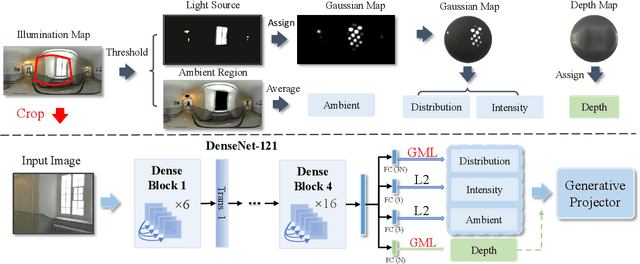
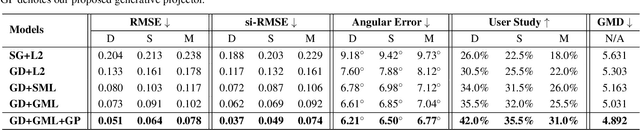
Lighting estimation from a single image is an essential yet challenging task in computer vision and computer graphics. Existing works estimate lighting by regressing representative illumination parameters or generating illumination maps directly. However, these methods often suffer from poor accuracy and generalization. This paper presents Geometric Mover's Light (GMLight), a lighting estimation framework that employs a regression network and a generative projector for effective illumination estimation. We parameterize illumination scenes in terms of the geometric light distribution, light intensity, ambient term, and auxiliary depth, and estimate them as a pure regression task. Inspired by the earth mover's distance, we design a novel geometric mover's loss to guide the accurate regression of light distribution parameters. With the estimated lighting parameters, the generative projector synthesizes panoramic illumination maps with realistic appearance and frequency. Extensive experiments show that GMLight achieves accurate illumination estimation and superior fidelity in relighting for 3D object insertion.
EMLight: Lighting Estimation via Spherical Distribution Approximation
Dec 21, 2020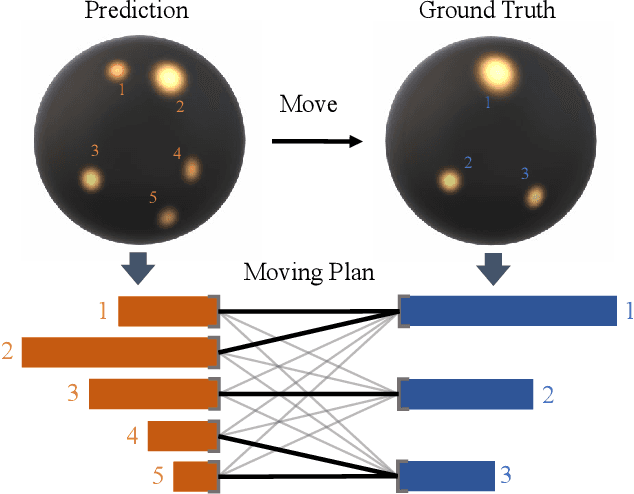
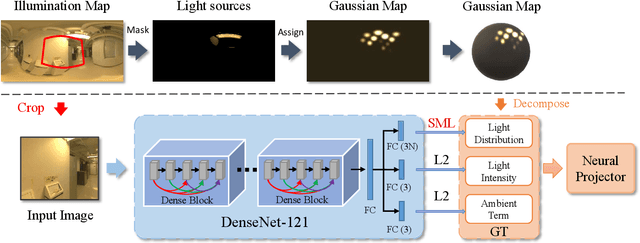

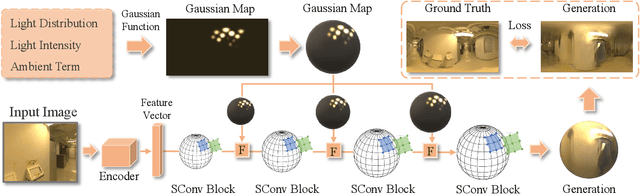
Illumination estimation from a single image is critical in 3D rendering and it has been investigated extensively in the computer vision and computer graphic research community. On the other hand, existing works estimate illumination by either regressing light parameters or generating illumination maps that are often hard to optimize or tend to produce inaccurate predictions. We propose Earth Mover Light (EMLight), an illumination estimation framework that leverages a regression network and a neural projector for accurate illumination estimation. We decompose the illumination map into spherical light distribution, light intensity and the ambient term, and define the illumination estimation as a parameter regression task for the three illumination components. Motivated by the Earth Mover distance, we design a novel spherical mover's loss that guides to regress light distribution parameters accurately by taking advantage of the subtleties of spherical distribution. Under the guidance of the predicted spherical distribution, light intensity and ambient term, the neural projector synthesizes panoramic illumination maps with realistic light frequency. Extensive experiments show that EMLight achieves accurate illumination estimation and the generated relighting in 3D object embedding exhibits superior plausibility and fidelity as compared with state-of-the-art methods.
Adversarial Image Composition with Auxiliary Illumination
Sep 17, 2020
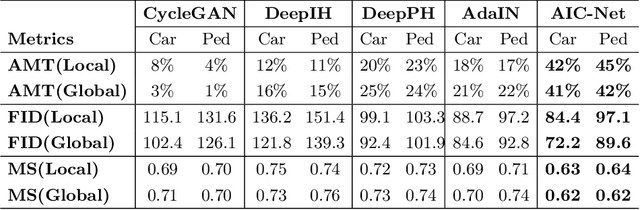
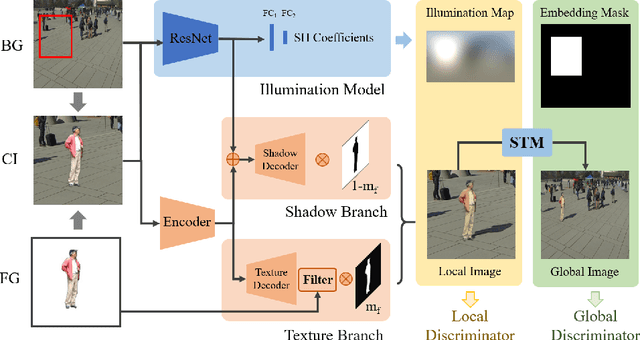
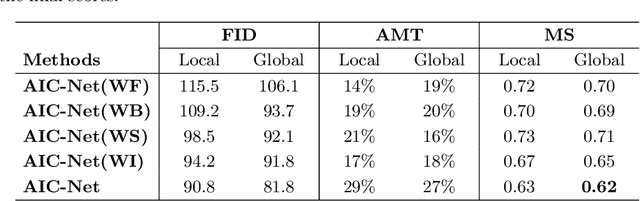
Dealing with the inconsistency between a foreground object and a background image is a challenging task in high-fidelity image composition. State-of-the-art methods strive to harmonize the composed image by adapting the style of foreground objects to be compatible with the background image, whereas the potential shadow of foreground objects within the composed image which is critical to the composition realism is largely neglected. In this paper, we propose an Adversarial Image Composition Net (AIC-Net) that achieves realistic image composition by considering potential shadows that the foreground object projects in the composed image. A novel branched generation mechanism is proposed, which disentangles the generation of shadows and the transfer of foreground styles for optimal accomplishment of the two tasks simultaneously. A differentiable spatial transformation module is designed which bridges the local harmonization and the global harmonization to achieve their joint optimization effectively. Extensive experiments on pedestrian and car composition tasks show that the proposed AIC-Net achieves superior composition performance qualitatively and quantitatively.
Towards Realistic 3D Embedding via View Alignment
Jul 14, 2020
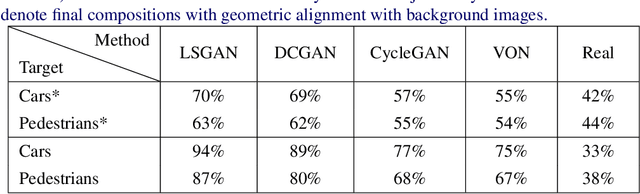
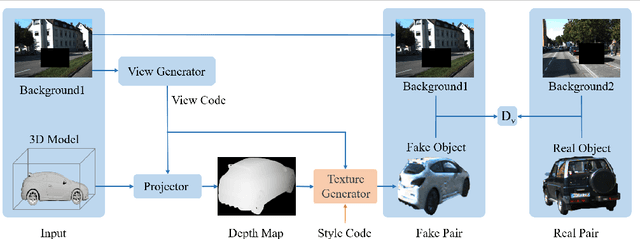
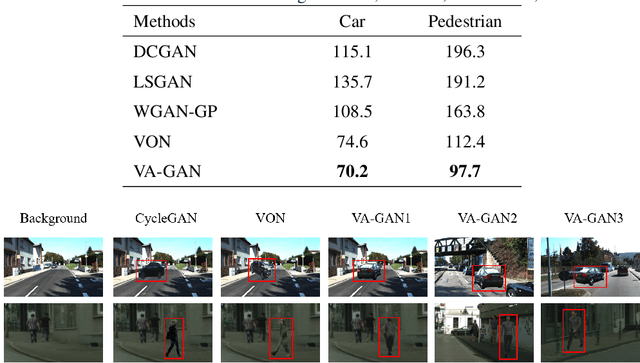
Recent advances in generative adversarial networks (GANs) have achieved great success in automated image composition that generates new images by embedding interested foreground objects into background images automatically. On the other hand, most existing works deal with foreground objects in two-dimensional (2D) images though foreground objects in three-dimensional (3D) models are more flexible with 360-degree view freedom. This paper presents an innovative View Alignment GAN (VA-GAN) that composes new images by embedding 3D models into 2D background images realistically and automatically. VA-GAN consists of a texture generator and a differential discriminator that are inter-connected and end-to-end trainable. The differential discriminator guides to learn geometric transformation from background images so that the composed 3D models can be aligned with the background images with realistic poses and views. The texture generator adopts a novel view encoding mechanism for generating accurate object textures for the 3D models under the estimated views. Extensive experiments over two synthesis tasks (car synthesis with KITTI and pedestrian synthesis with Cityscapes) show that VA-GAN achieves high-fidelity composition qualitatively and quantitatively as compared with state-of-the-art generation methods.