 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Memory Efficient Baseline for Open Domain Question Answering
Dec 30, 2020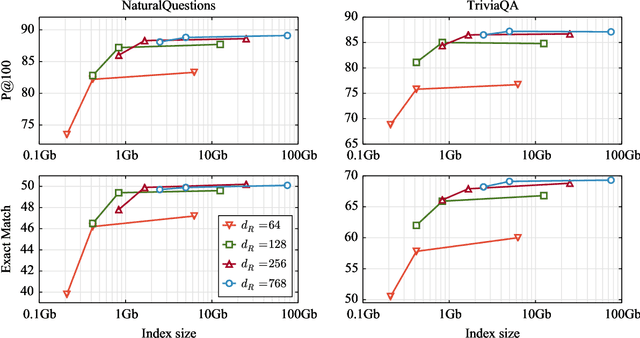
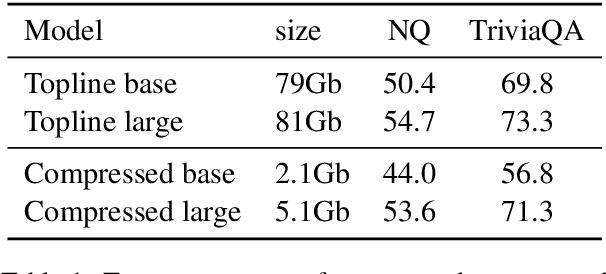
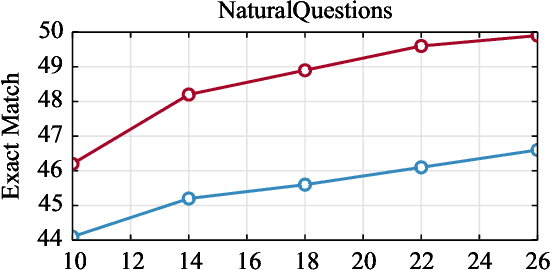
Recently, retrieval systems based on dense representations have led to important improvements in open-domain question answering, and related tasks. While very effective, this approach is also memory intensive, as the dense vectors for the whole knowledge source need to be kept in memory. In this paper, we study how the memory footprint of dense retriever-reader systems can be reduced. We consider three strategies to reduce the index size: dimension reduction, vector quantization and passage filtering. We evaluate our approach on two question answering benchmarks: TriviaQA and NaturalQuestions, showing that it is possible to get competitive systems using less than 6Gb of memory.
Generating Fact Checking Briefs
Nov 10, 2020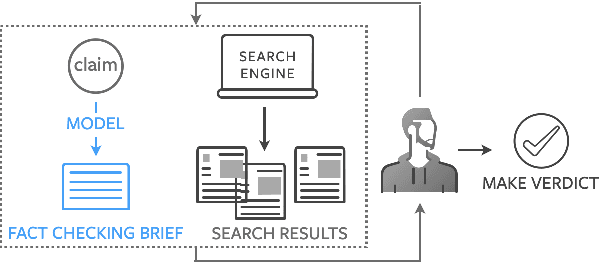
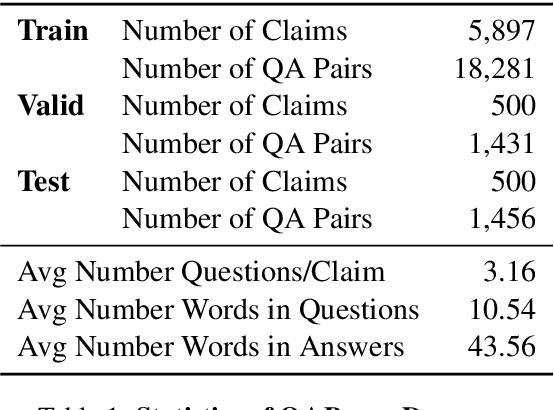

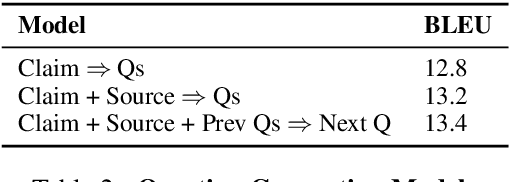
Fact checking at scale is difficult -- while the number of active fact checking websites is growing, it remains too small for the needs of the contemporary media ecosystem. However, despite good intentions, contributions from volunteers are often error-prone, and thus in practice restricted to claim detection. We investigate how to increase the accuracy and efficiency of fact checking by providing information about the claim before performing the check, in the form of natural language briefs. We investigate passage-based briefs, containing a relevant passage from Wikipedia, entity-centric ones consisting of Wikipedia pages of mentioned entities, and Question-Answering Briefs, with questions decomposing the claim, and their answers. To produce QABriefs, we develop QABriefer, a model that generates a set of questions conditioned on the claim, searches the web for evidence, and generates answers. To train its components, we introduce QABriefDataset which we collected via crowdsourcing. We show that fact checking with briefs -- in particular QABriefs -- increases the accuracy of crowdworkers by 10% while slightly decreasing the time taken. For volunteer (unpaid) fact checkers, QABriefs slightly increase accuracy and reduce the time required by around 20%.
Autoregressive Entity Retrieval
Oct 02, 2020Entities are at the center of how we represent and aggregate knowledge. For instance, Encyclopedias such as Wikipedia are structured by entities (e.g., one per article). The ability to retrieve such entities given a query is fundamental for knowledge-intensive tasks such as entity linking and open-domain question answering. One way to understand current approaches is as classifiers among atomic labels, one for each entity. Their weight vectors are dense entity representations produced by encoding entity information such as descriptions. This approach leads to several shortcomings: i) context and entity affinity is mainly captured through a vector dot product, potentially missing fine-grained interactions between the two; ii) a large memory footprint is needed to store dense representations when considering large entity sets; iii) an appropriately hard set of negative data has to be subsampled at training time. We propose GENRE, the first system that retrieves entities by generating their unique names, left to right, token-by-token in an autoregressive fashion, and conditioned on the context. This enables to mitigate the aforementioned technical issues: i) the autoregressive formulation allows us to directly capture relations between context and entity name, effectively cross encoding both; ii) the memory footprint is greatly reduced because the parameters of our encoder-decoder architecture scale with vocabulary size, not entity count; iii) the exact softmax loss can be efficiently computed without the need to subsample negative data. We show the efficacy of the approach with more than 20 datasets on entity disambiguation, end-to-end entity linking and document retrieval tasks, achieving new SOTA, or very competitive results while using a tiny fraction of the memory of competing systems. Finally, we demonstrate that new entities can be added by simply specifying their unambiguous name.
KILT: a Benchmark for Knowledge Intensive Language Tasks
Sep 04, 2020
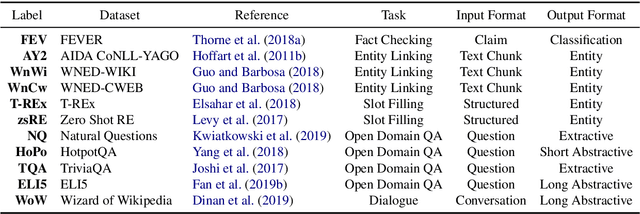
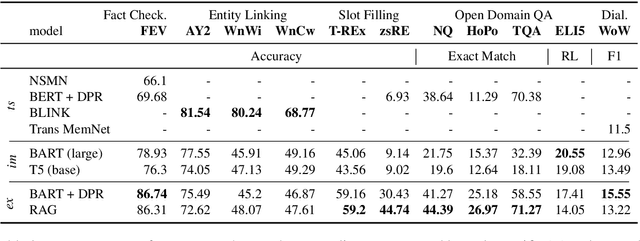
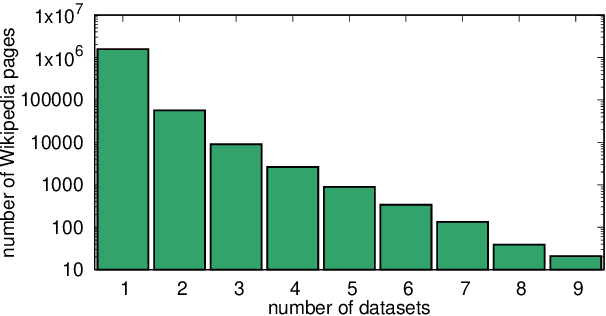
Challenging problems such as open-domain question answering, fact checking, slot filling and entity linking require access to large, external knowledge sources. While some models do well on individual tasks, developing general models is difficult as each task might require computationally expensive indexing of custom knowledge sources, in addition to dedicated infrastructure. To catalyze research on models that condition on specific information in large textual resources, we present a benchmark for knowledge-intensive language tasks (KILT). All tasks in KILT are grounded in the same snapshot of Wikipedia, reducing engineering turnaround through the re-use of components, as well as accelerating research into task-agnostic memory architectures. We test both task-specific and general baselines, evaluating downstream performance in addition to the ability of the models to provide provenance. We find that a shared dense vector index coupled with a seq2seq model is a strong baseline, outperforming more tailor-made approaches for fact checking, open-domain question answering and dialogue, and yielding competitive results on entity linking and slot filling, by generating disambiguated text. KILT data and code are available at https://github.com/facebookresearch/KILT.
Video Understanding as Machine Translation
Jun 12, 2020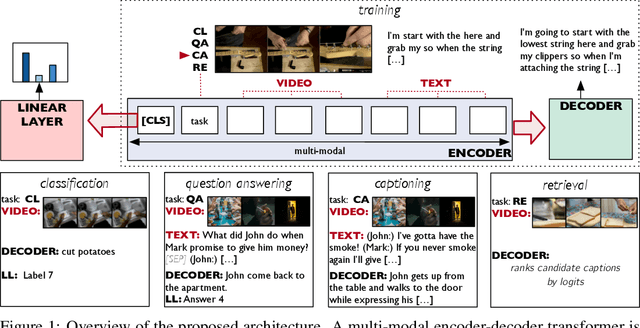
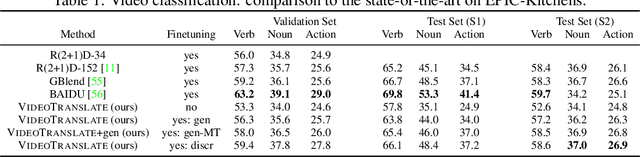
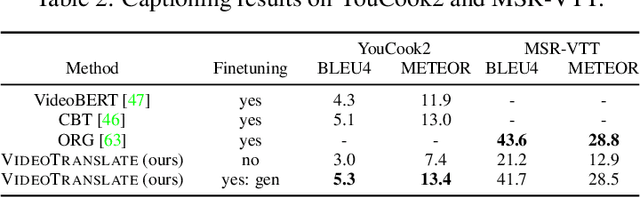

With the advent of large-scale multimodal video datasets, especially sequences with audio or transcribed speech, there has been a growing interest in self-supervised learning of video representations. Most prior work formulates the objective as a contrastive metric learning problem between the modalities. To enable effective learning, however, these strategies require a careful selection of positive and negative samples often combined with hand-designed curriculum policies. In this work we remove the need for negative sampling by taking a generative modeling approach that poses the objective as a translation problem between modalities. Such a formulation allows us to tackle a wide variety of downstream video understanding tasks by means of a single unified framework, without the need for large batches of negative samples common in contrastive metric learning. We experiment with the large-scale HowTo100M dataset for training, and report performance gains over the state-of-the-art on several downstream tasks including video classification (EPIC-Kitchens), question answering (TVQA), captioning (TVC, YouCook2, and MSR-VTT), and text-based clip retrieval (YouCook2 and MSR-VTT).
Concept Matching for Low-Resource Classification
Jun 01, 2020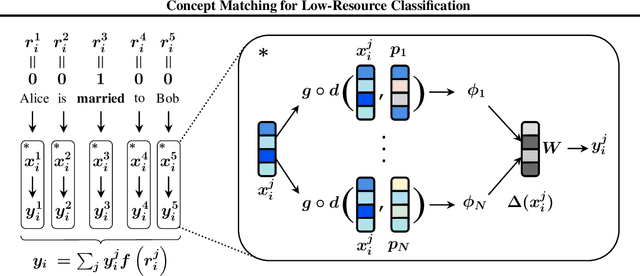


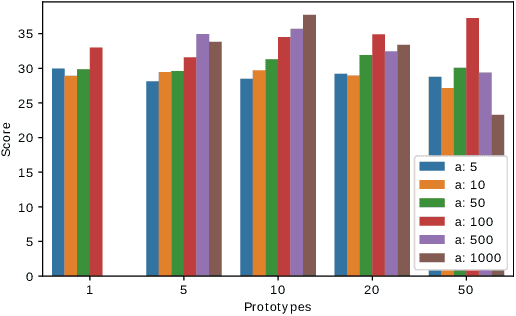
We propose a model to tackle classification tasks in the presence of very little training data. To this aim, we approximate the notion of exact match with a theoretically sound mechanism that computes a probability of matching in the input space. Importantly, the model learns to focus on elements of the input that are relevant for the task at hand; by leveraging highlighted portions of the training data, an error boosting technique guides the learning process. In practice, it increases the error associated with relevant parts of the input by a given factor. Remarkable results on text classification tasks confirm the benefits of the proposed approach in both balanced and unbalanced cases, thus being of practical use when labeling new examples is expensive. In addition, by inspecting its weights, it is often possible to gather insights on what the model has learned.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
May 22, 2020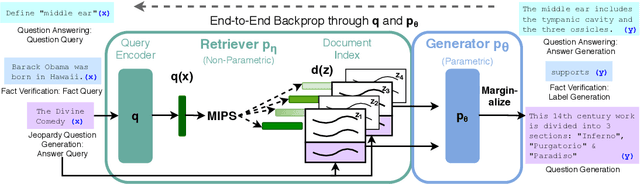
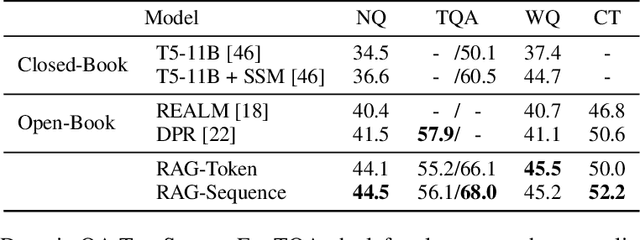
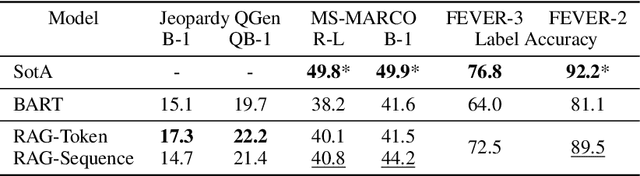

Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge remain open research problems. Pre-trained models with a differentiable access mechanism to explicit non-parametric memory can overcome this issue, but have so far been only investigated for extractive downstream tasks. We explore a general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) -- models which combine pre-trained parametric and non-parametric memory for language generation. We introduce RAG models where the parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. We compare two RAG formulations, one which conditions on the same retrieved passages across the whole generated sequence, the other can use different passages per token. We fine-tune and evaluate our models on a wide range of knowledge-intensive NLP tasks and set the state-of-the-art on three open domain QA tasks, outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures. For language generation tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art parametric-only seq2seq baseline.
How Context Affects Language Models' Factual Predictions
May 10, 2020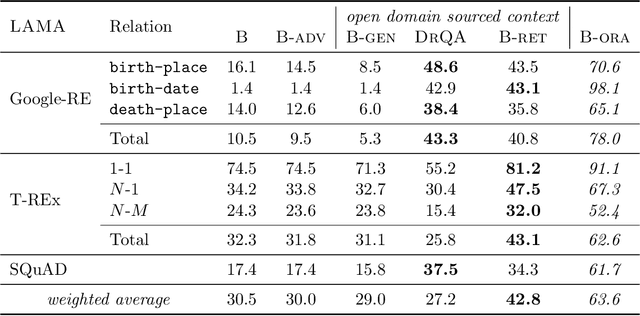
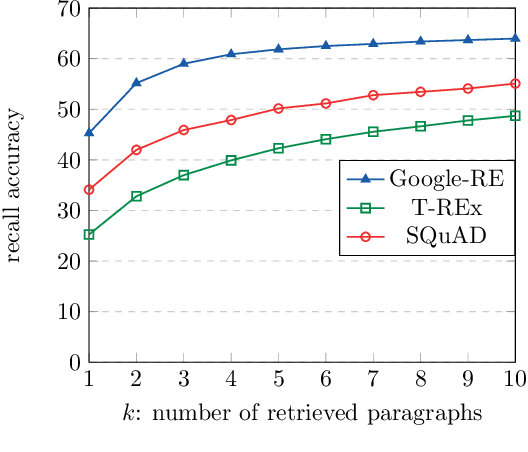
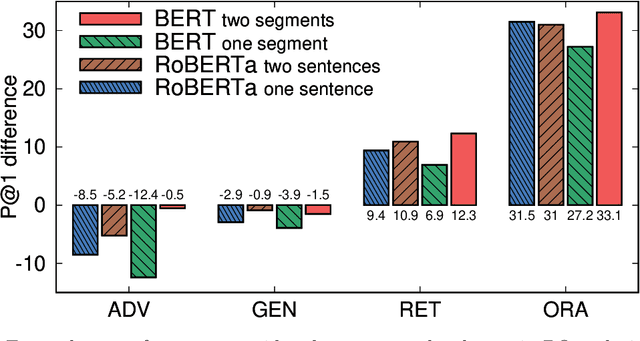
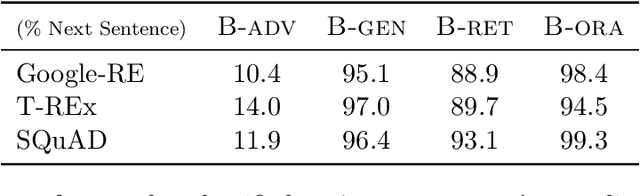
When pre-trained on large unsupervised textual corpora, language models are able to store and retrieve factual knowledge to some extent, making it possible to use them directly for zero-shot cloze-style question answering. However, storing factual knowledge in a fixed number of weights of a language model clearly has limitations. Previous approaches have successfully provided access to information outside the model weights using supervised architectures that combine an information retrieval system with a machine reading component. In this paper, we go a step further and integrate information from a retrieval system with a pre-trained language model in a purely unsupervised way. We report that augmenting pre-trained language models in this way dramatically improves performance and that the resulting system, despite being unsupervised, is competitive with a supervised machine reading baseline. Furthermore, processing query and context with different segment tokens allows BERT to utilize its Next Sentence Prediction pre-trained classifier to determine whether the context is relevant or not, substantially improving BERT's zero-shot cloze-style question-answering performance and making its predictions robust to noisy contexts.
Zero-shot Entity Linking with Dense Entity Retrieval
Nov 10, 2019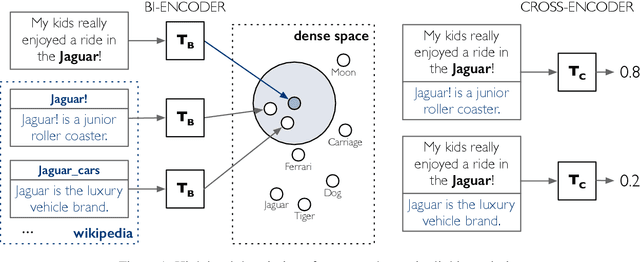

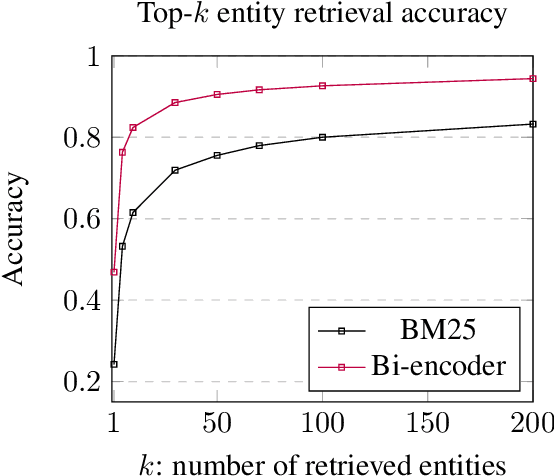

We consider the zero-shot entity-linking challenge where each entity is defined by a short textual description, and the model must read these descriptions together with the mention context to make the final linking decisions. In this setting, retrieving entity candidates can be particularly challenging, since many of the common linking cues such as entity alias tables and link popularity are not available. In this paper, we introduce a simple and effective two stage approach for zero-shot linking, based on fine-tuned BERT architectures. In the first stage, we do retrieval in a dense space defined by a bi-encoder that independently embeds the mention context and the entity descriptions. Each candidate is then examined more carefully with a cross-encoder, that concatenates the mention and entity text. Our approach achieves a nearly 5 point absolute gain on a recently introduced zero-shot entity linking benchmark, driven largely by improvements over previous IR-based candidate retrieval. We also show that it performs well in the non-zero-shot setting, obtaining the state-of-the-art result on TACKBP-2010.
How Decoding Strategies Affect the Verifiability of Generated Text
Nov 09, 2019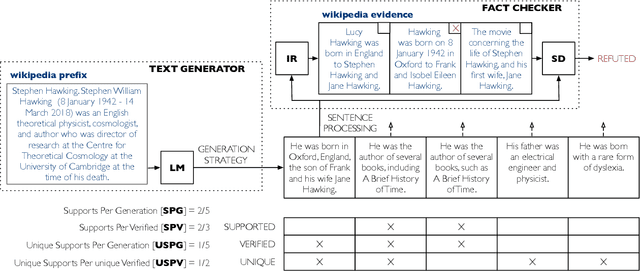
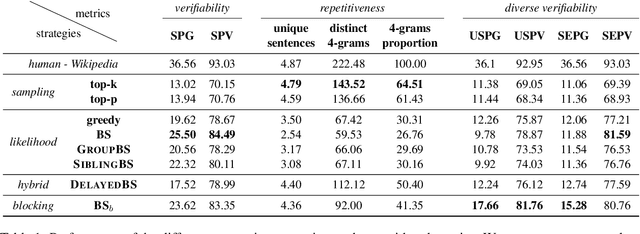
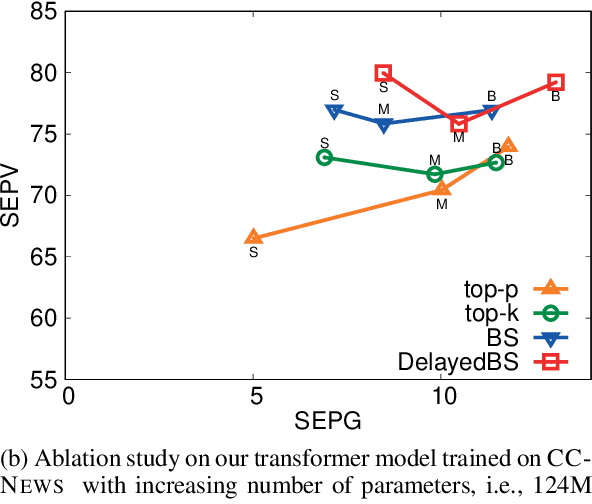

Language models are of considerable importance. They are used for pretraining, finetuning, and rescoring in downstream applications, and as is as a test-bed and benchmark for progress in natural language understanding. One fundamental question regards the way we should generate text from a language model. It is well known that different decoding strategies can have dramatic impact on the quality of the generated text and using the most likely sequence under the model distribution, e.g., via beam search, generally leads to degenerate and repetitive outputs. While generation strategies such as top-k and nucleus sampling lead to more natural and less repetitive generations, the true cost of avoiding the highest scoring solution is hard to quantify. In this paper, we argue that verifiability, i.e., the consistency of the generated text with factual knowledge, is a suitable metric for measuring this cost. We use an automatic fact-checking system to calculate new metrics as a function of the number of supported claims per sentence and find that sampling-based generation strategies, such as top-k, indeed lead to less verifiable text. This finding holds across various dimensions, such as model size, training data size and parameters of the generation strategy. Based on this finding, we introduce a simple and effective generation strategy for producing non-repetitive and more verifiable (in comparison to other methods) text.