 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensor Configuration Matters: A Systematic Evaluation of Multimodal SLAM on Quadruped Robots
Jun 17, 2026Autonomous navigation of quadrupedal robots in diverse environments fundamentally relies on resilient Simultaneous Localization and Mapping (SLAM). While visual-inertial SLAM has matured across wheeled, handheld, and aerial platforms, a critical evaluation gap remains regarding how hardware-level sensor configurations affect performance under the aggressive dynamics of legged locomotion. Quadrupeds introduce distinct embodiment-induced sensory challenges, including foot-impact shocks, high-frequency mechanical vibrations, and rapid angular rotations, which degrade standard perception pipelines. To address this gap, we present a systematic evaluation of state-of-the-art visual, visual-inertial, and LiDAR-visual-inertial SLAM methods using the GrandTour dataset recorded on an ANYmal D quadruped. We isolate and quantify the impacts of camera modalities, shutter techniques, and inertial sensor tiers, analyzing their trade-offs across localization accuracy, algorithmic robustness, and computational resource utilization. Our empirical findings demonstrate that hardware selection has substantial influence on system resilience: stereo configurations consistently outperform monocular and RGB-D modalities, global shutter cameras significantly mitigate motion-induced tracking failures compared to rolling shutter cameras, and, crucially, standard inertial integration can degrade the performance of primarily vision-based frameworks under harsh legged locomotion. These insights additionally offer concrete design guidelines for tailoring custom sensor payloads to achieve dependable perception on agile legged systems.
Revisiting Vul-RAG: Reproducibility and Replicability of RAG-based Vulnerability Detection with Open-Weight Models
Jun 03, 2026Large language models (LLMs) have shown strong potential for automated software vulnerability detection, particularly in retrieval-augmented generation (RAG) settings. However, for approaches relying on proprietary models and APIs, reproducibility and replicability remain largely unexplored, raising the question of whether reported results generalize or depend primarily on specific model choices. In this work, we present a reproducibility study of Vul-RAG, a RAG-based framework for source code vulnerability detection that enhances LLMs with high-level vulnerability knowledge. We first replicate the results in a fully local and open-weights setting using the reported open-weight baseline models. We then extend the evaluation to a diverse set of recent open-weight LLMs, including code-specialized, general-purpose, and reasoning models of varying parameter sizes. The results confirm that the findings of Vul-RAG are reproducible under local deployment, but with minor deviations. Across all evaluated models, we observe a performance plateau at approximately 0.30 pairwise accuracy (code pairs for which both the vulnerable and the patched function are correctly classified). Notably, this plateau persists even for more recent and advanced models, indicating that improvements in model capacity alone do not substantially enhance performance. Finally, we discuss practical implications and trade-offs between detection effectiveness, model capabilities, and model scale. Implementation and evaluation artifacts are publicly available at https://github.com/hs-esslingen-it-security/revisiting-Vul-RAG.
LAD-Drive: Bridging Language and Trajectory with Action-Aware Diffusion Transformers
Mar 02, 2026While multimodal large language models (MLLMs) provide advanced reasoning for autonomous driving, translating their discrete semantic knowledge into continuous trajectories remains a fundamental challenge. Existing methods often rely on unimodal planning heads that inherently limit their ability to represent multimodal driving behavior. Furthermore, most generative approaches frequently condition on one-hot encoded actions, discarding the nuanced navigational uncertainty critical for complex scenarios. To resolve these limitations, we introduce LAD-Drive, a generative framework that structurally disentangles high-level intention from low-level spatial planning. LAD-Drive employs an action decoder to infer a probabilistic meta-action distribution, establishing an explicit belief state that preserves the nuanced intent typically lost by one-hot encodings. This distribution, fused with the vehicle's kinematic state, conditions an action-aware diffusion decoder that utilizes a truncated denoising process to refine learned motion anchors into safe, kinematically feasible trajectories. Extensive evaluations on the LangAuto benchmark demonstrate that LAD-Drive achieves state-of-the-art results, outperforming competitive baselines by up to 59% in Driving Score while significantly reducing route deviations and collisions. We will publicly release the code and models on https://github.com/iis-esslingen/lad-drive.
Enhancing LLM-based Autonomous Driving with Modular Traffic Light and Sign Recognition
Nov 18, 2025Large Language Models (LLMs) are increasingly used for decision-making and planning in autonomous driving, showing promising reasoning capabilities and potential to generalize across diverse traffic situations. However, current LLM-based driving agents lack explicit mechanisms to enforce traffic rules and often struggle to reliably detect small, safety-critical objects such as traffic lights and signs. To address this limitation, we introduce TLS-Assist, a modular redundancy layer that augments LLM-based autonomous driving agents with explicit traffic light and sign recognition. TLS-Assist converts detections into structured natural language messages that are injected into the LLM input, enforcing explicit attention to safety-critical cues. The framework is plug-and-play, model-agnostic, and supports both single-view and multi-view camera setups. We evaluate TLS-Assist in a closed-loop setup on the LangAuto benchmark in CARLA. The results demonstrate relative driving performance improvements of up to 14% over LMDrive and 7% over BEVDriver, while consistently reducing traffic light and sign infractions. We publicly release the code and models on https://github.com/iis-esslingen/TLS-Assist.
GraphPilot: Grounded Scene Graph Conditioning for Language-Based Autonomous Driving
Nov 14, 2025Vision-language models have recently emerged as promising planners for autonomous driving, where success hinges on topology-aware reasoning over spatial structure and dynamic interactions from multimodal input. However, existing models are typically trained without supervision that explicitly encodes these relational dependencies, limiting their ability to infer how agents and other traffic entities influence one another from raw sensor data. In this work, we bridge this gap with a novel model-agnostic method that conditions language-based driving models on structured relational context in the form of traffic scene graphs. We serialize scene graphs at various abstraction levels and formats, and incorporate them into the models via structured prompt templates, enabling a systematic analysis of when and how relational supervision is most beneficial. Extensive evaluations on the public LangAuto benchmark show that scene graph conditioning of state-of-the-art approaches yields large and persistent improvement in driving performance. Notably, we observe up to a 15.6\% increase in driving score for LMDrive and 17.5\% for BEVDriver, indicating that models can better internalize and ground relational priors through scene graph-conditioned training, even without requiring scene graph input at test-time. Code, fine-tuned models, and our scene graph dataset are publicly available at https://github.com/iis-esslingen/GraphPilot.
Probabilistic Textual Time Series Depression Detection
Nov 06, 2025Accurate and interpretable predictions of depression severity are essential for clinical decision support, yet existing models often lack uncertainty estimates and temporal modeling. We propose PTTSD, a Probabilistic Textual Time Series Depression Detection framework that predicts PHQ-8 scores from utterance-level clinical interviews while modeling uncertainty over time. PTTSD includes sequence-to-sequence and sequence-to-one variants, both combining bidirectional LSTMs, self-attention, and residual connections with Gaussian or Student-t output heads trained via negative log-likelihood. Evaluated on E-DAIC and DAIC-WOZ, PTTSD achieves state-of-the-art performance among text-only systems (e.g., MAE = 3.85 on E-DAIC, 3.55 on DAIC) and produces well-calibrated prediction intervals. Ablations confirm the value of attention and probabilistic modeling, while comparisons with MentalBERT establish generality. A three-part calibration analysis and qualitative case studies further highlight the interpretability and clinical relevance of uncertainty-aware forecasting.
A Systematic Literature Review on Detecting Software Vulnerabilities with Large Language Models
Jul 30, 2025The increasing adoption of Large Language Models (LLMs) in software engineering has sparked interest in their use for software vulnerability detection. However, the rapid development of this field has resulted in a fragmented research landscape, with diverse studies that are difficult to compare due to differences in, e.g., system designs and dataset usage. This fragmentation makes it difficult to obtain a clear overview of the state-of-the-art or compare and categorize studies meaningfully. In this work, we present a comprehensive systematic literature review (SLR) of LLM-based software vulnerability detection. We analyze 227 studies published between January 2020 and June 2025, categorizing them by task formulation, input representation, system architecture, and adaptation techniques. Further, we analyze the datasets used, including their characteristics, vulnerability coverage, and diversity. We present a fine-grained taxonomy of vulnerability detection approaches, identify key limitations, and outline actionable future research opportunities. By providing a structured overview of the field, this review improves transparency and serves as a practical guide for researchers and practitioners aiming to conduct more comparable and reproducible research. We publicly release all artifacts and maintain a living repository of LLM-based software vulnerability detection studies.
Leveraging Machine Learning Models to Predict the Outcome of Digital Medical Triage Interviews
Apr 16, 2025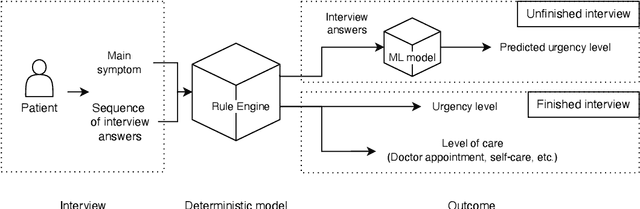
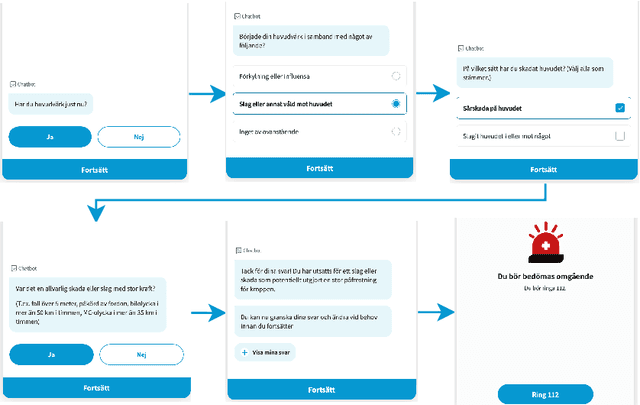
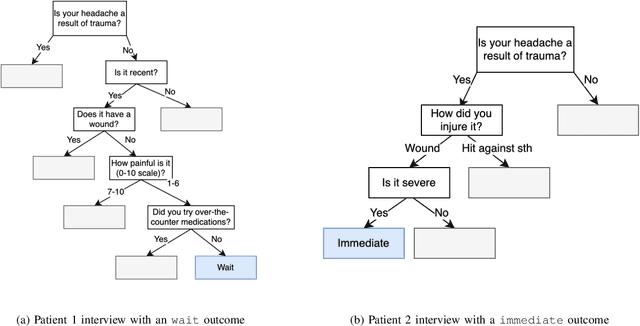
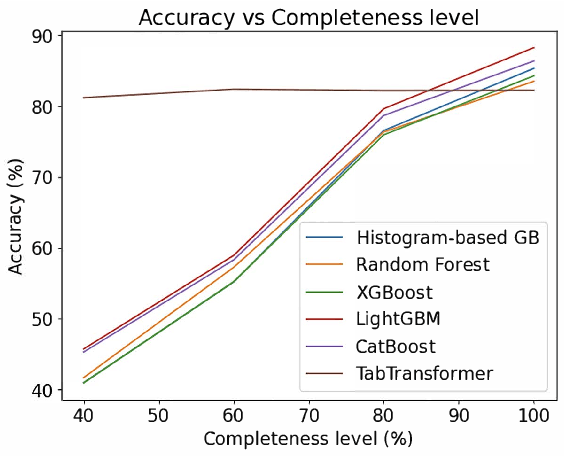
Many existing digital triage systems are questionnaire-based, guiding patients to appropriate care levels based on information (e.g., symptoms, medical history, and urgency) provided by the patients answering questionnaires. Such a system often uses a deterministic model with predefined rules to determine care levels. It faces challenges with incomplete triage interviews since it can only assist patients who finish the process. In this study, we explore the use of machine learning (ML) to predict outcomes of unfinished interviews, aiming to enhance patient care and service quality. Predicting triage outcomes from incomplete data is crucial for patient safety and healthcare efficiency. Our findings show that decision-tree models, particularly LGBMClassifier and CatBoostClassifier, achieve over 80\% accuracy in predicting outcomes from complete interviews while having a linear correlation between the prediction accuracy and interview completeness degree. For example, LGBMClassifier achieves 88,2\% prediction accuracy for interviews with 100\% completeness, 79,6\% accuracy for interviews with 80\% completeness, 58,9\% accuracy for 60\% completeness, and 45,7\% accuracy for 40\% completeness. The TabTransformer model demonstrated exceptional accuracy of over 80\% for all degrees of completeness but required extensive training time, indicating a need for more powerful computational resources. The study highlights the linear correlation between interview completeness and predictive power of the decision-tree models.
CFiCS: Graph-Based Classification of Common Factors and Microcounseling Skills
Mar 28, 2025



Common factors and microcounseling skills are critical to the effectiveness of psychotherapy. Understanding and measuring these elements provides valuable insights into therapeutic processes and outcomes. However, automatic identification of these change principles from textual data remains challenging due to the nuanced and context-dependent nature of therapeutic dialogue. This paper introduces CFiCS, a hierarchical classification framework integrating graph machine learning with pretrained contextual embeddings. We represent common factors, intervention concepts, and microcounseling skills as a heterogeneous graph, where textual information from ClinicalBERT enriches each node. This structure captures both the hierarchical relationships (e.g., skill-level nodes linking to broad factors) and the semantic properties of therapeutic concepts. By leveraging graph neural networks, CFiCS learns inductive node embeddings that generalize to unseen text samples lacking explicit connections. Our results demonstrate that integrating ClinicalBERT node features and graph structure significantly improves classification performance, especially in fine-grained skill prediction. CFiCS achieves substantial gains in both micro and macro F1 scores across all tasks compared to baselines, including random forests, BERT-based multi-task models, and graph-based methods.
NeRF and Gaussian Splatting SLAM in the Wild
Dec 04, 2024Navigating outdoor environments with visual Simultaneous Localization and Mapping (SLAM) systems poses significant challenges due to dynamic scenes, lighting variations, and seasonal changes, requiring robust solutions. While traditional SLAM methods struggle with adaptability, deep learning-based approaches and emerging neural radiance fields as well as Gaussian Splatting-based SLAM methods, offer promising alternatives. However, these methods have primarily been evaluated in controlled indoor environments with stable conditions, leaving a gap in understanding their performance in unstructured and variable outdoor settings. This study addresses this gap by evaluating these methods in natural outdoor environments, focusing on camera tracking accuracy, robustness to environmental factors, and computational efficiency, highlighting distinct trade-offs. Extensive evaluations demonstrate that neural SLAM methods achieve superior robustness, particularly under challenging conditions such as low light, but at a high computational cost. At the same time, traditional methods perform the best across seasons but are highly sensitive to variations in lighting conditions. The code of the benchmark is publicly available at https://github.com/iis-esslingen/nerf-3dgs-benchmark.