 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Ranking Pursuit
Jul 02, 2013
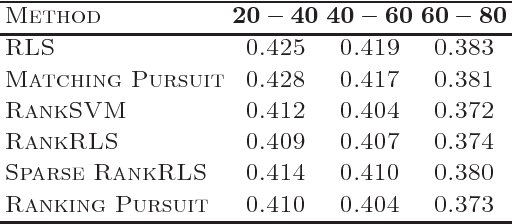

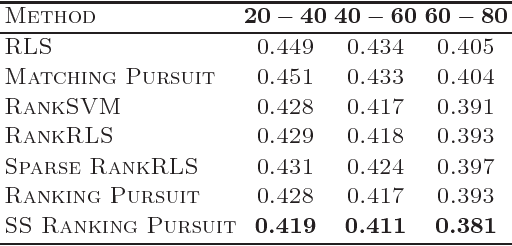
We propose a novel sparse preference learning/ranking algorithm. Our algorithm approximates the true utility function by a weighted sum of basis functions using the squared loss on pairs of data points, and is a generalization of the kernel matching pursuit method. It can operate both in a supervised and a semi-supervised setting and allows efficient search for multiple, near-optimal solutions. Furthermore, we describe the extension of the algorithm suitable for combined ranking and regression tasks. In our experiments we demonstrate that the proposed algorithm outperforms several state-of-the-art learning methods when taking into account unlabeled data and performs comparably in a supervised learning scenario, while providing sparser solutions.
Premise Selection for Mathematics by Corpus Analysis and Kernel Methods
Apr 12, 2012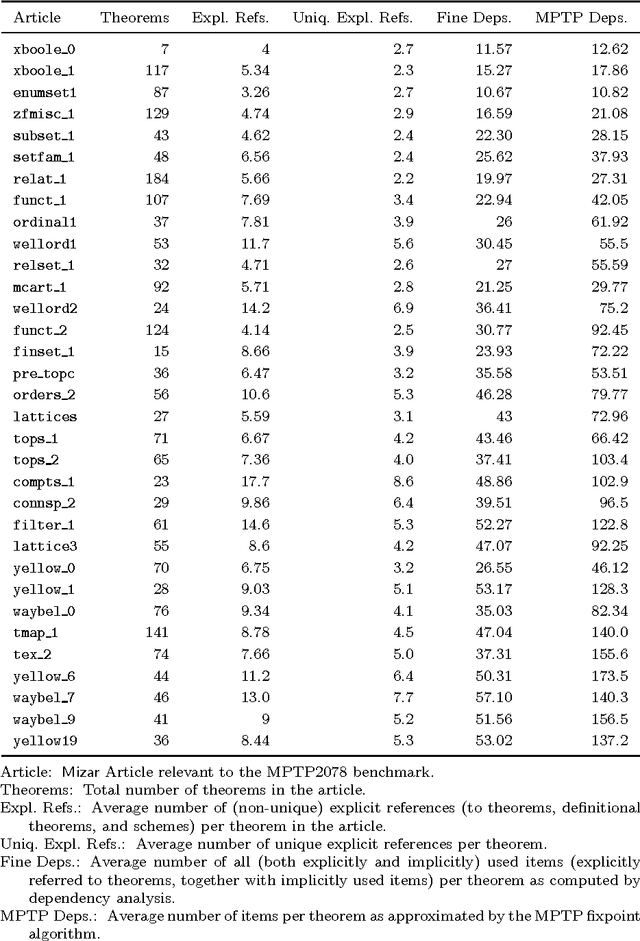
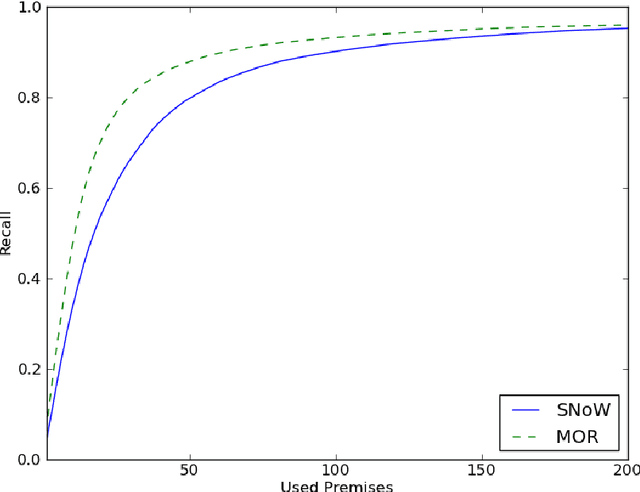

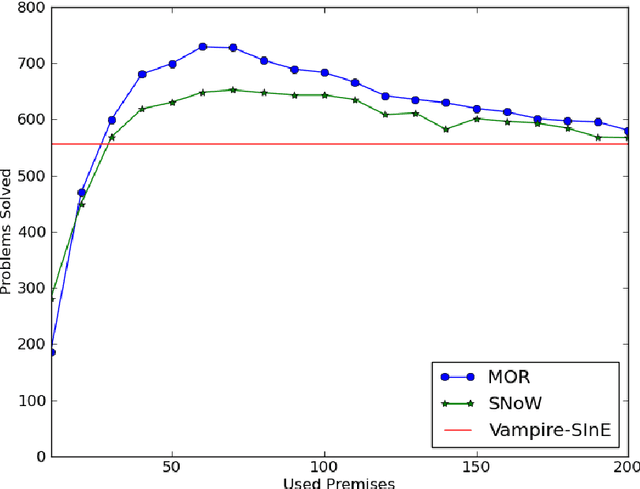
Smart premise selection is essential when using automated reasoning as a tool for large-theory formal proof development. A good method for premise selection in complex mathematical libraries is the application of machine learning to large corpora of proofs. This work develops learning-based premise selection in two ways. First, a newly available minimal dependency analysis of existing high-level formal mathematical proofs is used to build a large knowledge base of proof dependencies, providing precise data for ATP-based re-verification and for training premise selection algorithms. Second, a new machine learning algorithm for premise selection based on kernel methods is proposed and implemented. To evaluate the impact of both techniques, a benchmark consisting of 2078 large-theory mathematical problems is constructed,extending the older MPTP Challenge benchmark. The combined effect of the techniques results in a 50% improvement on the benchmark over the Vampire/SInE state-of-the-art system for automated reasoning in large theories.