 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-Selective Normalization for Label-Shift Robust Test-Time Adaptation
Feb 07, 2024



Deep neural networks have useful applications in many different tasks, however their performance can be severely affected by changes in the data distribution. For example, in the biomedical field, their performance can be affected by changes in the data (different machines, populations) between training and test datasets. To ensure robustness and generalization to real-world scenarios, test-time adaptation has been recently studied as an approach to adjust models to a new data distribution during inference. Test-time batch normalization is a simple and popular method that achieved compelling performance on domain shift benchmarks. It is implemented by recalculating batch normalization statistics on test batches. Prior work has focused on analysis with test data that has the same label distribution as the training data. However, in many practical applications this technique is vulnerable to label distribution shifts, sometimes producing catastrophic failure. This presents a risk in applying test time adaptation methods in deployment. We propose to tackle this challenge by only selectively adapting channels in a deep network, minimizing drastic adaptation that is sensitive to label shifts. Our selection scheme is based on two principles that we empirically motivate: (1) later layers of networks are more sensitive to label shift (2) individual features can be sensitive to specific classes. We apply the proposed technique to three classification tasks, including CIFAR10-C, Imagenet-C, and diagnosis of fatty liver, where we explore both covariate and label distribution shifts. We find that our method allows to bring the benefits of TTA while significantly reducing the risk of failure common in other methods, while being robust to choice in hyperparameters.
Model Breadcrumbs: Scaling Multi-Task Model Merging with Sparse Masks
Dec 11, 2023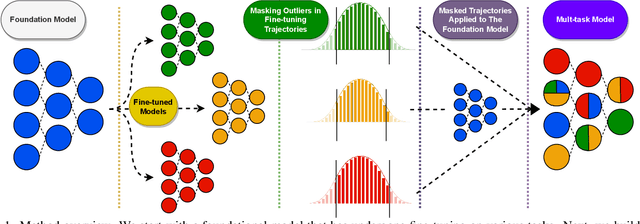

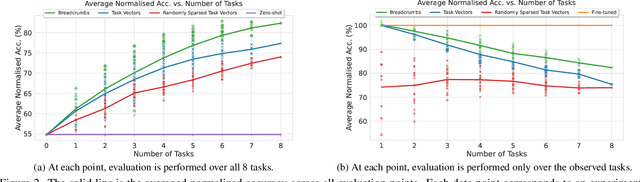
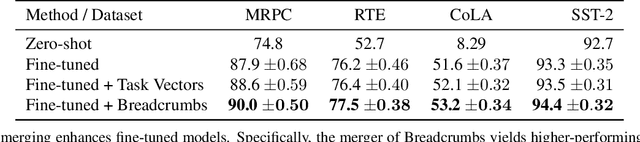
The rapid development of AI systems has been greatly influenced by the emergence of foundation models. A common approach for targeted problems involves fine-tuning these pre-trained foundation models for specific target tasks, resulting in a rapid spread of models fine-tuned across a diverse array of tasks. This work focuses on the problem of merging multiple fine-tunings of the same foundation model derived from a spectrum of auxiliary tasks. We introduce a new simple method, Model Breadcrumbs, which consists of a sparsely defined set of weights that carve out a trajectory within the weight space of a pre-trained model, enhancing task performance when traversed. These breadcrumbs are constructed by subtracting the weights from a pre-trained model before and after fine-tuning, followed by a sparsification process that eliminates weight outliers and negligible perturbations. Our experiments demonstrate the effectiveness of Model Breadcrumbs to simultaneously improve performance across multiple tasks. This contribution aligns with the evolving paradigm of updatable machine learning, reminiscent of the collaborative principles underlying open-source software development, fostering a community-driven effort to reliably update machine learning models. Our method is shown to be more efficient and unlike previous proposals does not require hyperparameter tuning for each new task added. Through extensive experimentation involving various models, tasks, and modalities we establish that integrating Model Breadcrumbs offers a simple, efficient, and highly effective approach for constructing multi-task models and facilitating updates to foundation models.
Can We Learn Communication-Efficient Optimizers?
Dec 02, 2023



Communication-efficient variants of SGD, specifically local SGD, have received a great deal of interest in recent years. These approaches compute multiple gradient steps locally, that is on each worker, before averaging model parameters, helping relieve the critical communication bottleneck in distributed deep learning training. Although many variants of these approaches have been proposed, they can sometimes lag behind state-of-the-art adaptive optimizers for deep learning. In this work, we investigate if the recent progress in the emerging area of learned optimizers can potentially close this gap while remaining communication-efficient. Specifically, we meta-learn how to perform global updates given an update from local SGD iterations. Our results demonstrate that learned optimizers can substantially outperform local SGD and its sophisticated variants while maintaining their communication efficiency. Learned optimizers can even generalize to unseen and much larger datasets and architectures, including ImageNet and ViTs, and to unseen modalities such as language modeling. We therefore demonstrate the potential of learned optimizers for improving communication-efficient distributed learning.
DragD3D: Vertex-based Editing for Realistic Mesh Deformations using 2D Diffusion Priors
Oct 06, 2023Direct mesh editing and deformation are key components in the geometric modeling and animation pipeline. Direct mesh editing methods are typically framed as optimization problems combining user-specified vertex constraints with a regularizer that determines the position of the rest of the vertices. The choice of the regularizer is key to the realism and authenticity of the final result. Physics and geometry-based regularizers are not aware of the global context and semantics of the object, and the more recent deep learning priors are limited to a specific class of 3D object deformations. In this work, our main contribution is a local mesh editing method called DragD3D for global context-aware realistic deformation through direct manipulation of a few vertices. DragD3D is not restricted to any class of objects. It achieves this by combining the classic geometric ARAP (as rigid as possible) regularizer with 2D priors obtained from a large-scale diffusion model. Specifically, we render the objects from multiple viewpoints through a differentiable renderer and use the recently introduced DDS loss which scores the faithfulness of the rendered image to one from a diffusion model. DragD3D combines the approximate gradients of the DDS with gradients from the ARAP loss to modify the mesh vertices via neural Jacobian field, while also satisfying vertex constraints. We show that our deformations are realistic and aware of the global context of the objects, and provide better results than just using geometric regularizers.
Continual Pre-Training of Large Language Models: How to (re)warm your model?
Aug 08, 2023



Large language models (LLMs) are routinely pre-trained on billions of tokens, only to restart the process over again once new data becomes available. A much cheaper and more efficient solution would be to enable the continual pre-training of these models, i.e. updating pre-trained models with new data instead of re-training them from scratch. However, the distribution shift induced by novel data typically results in degraded performance on past data. Taking a step towards efficient continual pre-training, in this work, we examine the effect of different warm-up strategies. Our hypothesis is that the learning rate must be re-increased to improve compute efficiency when training on a new dataset. We study the warmup phase of models pre-trained on the Pile (upstream data, 300B tokens) as we continue to pre-train on SlimPajama (downstream data, 297B tokens), following a linear warmup and cosine decay schedule. We conduct all experiments on the Pythia 410M language model architecture and evaluate performance through validation perplexity. We experiment with different pre-training checkpoints, various maximum learning rates, and various warmup lengths. Our results show that while rewarming models first increases the loss on upstream and downstream data, in the longer run it improves the downstream performance, outperforming models trained from scratch$\unicode{x2013}$even for a large downstream dataset.
$\textbf{A}^2\textbf{CiD}^2$: Accelerating Asynchronous Communication in Decentralized Deep Learning
Jun 14, 2023



Distributed training of Deep Learning models has been critical to many recent successes in the field. Current standard methods primarily rely on synchronous centralized algorithms which induce major communication bottlenecks and limit their usability to High-Performance Computing (HPC) environments with strong connectivity. Decentralized asynchronous algorithms are emerging as a potential alternative but their practical applicability still lags. In this work, we focus on peerto-peer asynchronous methods due to their flexibility and parallelization potentials. In order to mitigate the increase in bandwidth they require at large scale and in poorly connected contexts, we introduce a principled asynchronous, randomized, gossip-based algorithm which works thanks to a continuous momentum named $\textbf{A}^2\textbf{CiD}^2$. In addition to inducing a significant communication acceleration at no cost other than doubling the parameters, minimal adaptation is required to incorporate $\textbf{A}^2\textbf{CiD}^2$ to other asynchronous approaches. We demonstrate its efficiency theoretically and numerically. Empirically on the ring graph, adding $\textbf{A}^2\textbf{CiD}^2$ has the same effect as doubling the communication rate. In particular, we show consistent improvement on the ImageNet dataset using up to 64 asynchronous workers (A100 GPUs) and various communication network topologies.
Adversarial Attacks on the Interpretation of Neuron Activation Maximization
Jun 12, 2023The internal functional behavior of trained Deep Neural Networks is notoriously difficult to interpret. Activation-maximization approaches are one set of techniques used to interpret and analyze trained deep-learning models. These consist in finding inputs that maximally activate a given neuron or feature map. These inputs can be selected from a data set or obtained by optimization. However, interpretability methods may be subject to being deceived. In this work, we consider the concept of an adversary manipulating a model for the purpose of deceiving the interpretation. We propose an optimization framework for performing this manipulation and demonstrate a number of ways that popular activation-maximization interpretation techniques associated with CNNs can be manipulated to change the interpretations, shedding light on the reliability of these methods.
Can Forward Gradient Match Backpropagation?
Jun 12, 2023Forward Gradients - the idea of using directional derivatives in forward differentiation mode - have recently been shown to be utilizable for neural network training while avoiding problems generally associated with backpropagation gradient computation, such as locking and memorization requirements. The cost is the requirement to guess the step direction, which is hard in high dimensions. While current solutions rely on weighted averages over isotropic guess vector distributions, we propose to strongly bias our gradient guesses in directions that are much more promising, such as feedback obtained from small, local auxiliary networks. For a standard computer vision neural network, we conduct a rigorous study systematically covering a variety of combinations of gradient targets and gradient guesses, including those previously presented in the literature. We find that using gradients obtained from a local loss as a candidate direction drastically improves on random noise in Forward Gradient methods.
Guiding The Last Layer in Federated Learning with Pre-Trained Models
Jun 06, 2023



Federated Learning (FL) is an emerging paradigm that allows a model to be trained across a number of participants without sharing data. Recent works have begun to consider the effects of using pre-trained models as an initialization point for existing FL algorithms; however, these approaches ignore the vast body of efficient transfer learning literature from the centralized learning setting. Here we revisit the problem of FL from a pre-trained model considered in prior work and expand it to a set of computer vision transfer learning problems. We first observe that simply fitting a linear classification head can be efficient and effective in many cases. We then show that in the FL setting, fitting a classifier using the Nearest Class Means (NCM) can be done exactly and orders of magnitude more efficiently than existing proposals, while obtaining strong performance. Finally, we demonstrate that using a two-phase approach of obtaining the classifier and then fine-tuning the model can yield rapid convergence and improved generalization in the federated setting. We demonstrate the potential our method has to reduce communication and compute costs while achieving better model performance.
Re-Weighted Softmax Cross-Entropy to Control Forgetting in Federated Learning
Apr 11, 2023In Federated Learning, a global model is learned by aggregating model updates computed at a set of independent client nodes, to reduce communication costs multiple gradient steps are performed at each node prior to aggregation. A key challenge in this setting is data heterogeneity across clients resulting in differing local objectives which can lead clients to overly minimize their own local objective, diverging from the global solution. We demonstrate that individual client models experience a catastrophic forgetting with respect to data from other clients and propose an efficient approach that modifies the cross-entropy objective on a per-client basis by re-weighting the softmax logits prior to computing the loss. This approach shields classes outside a client's label set from abrupt representation change and we empirically demonstrate it can alleviate client forgetting and provide consistent improvements to standard federated learning algorithms. Our method is particularly beneficial under the most challenging federated learning settings where data heterogeneity is high and client participation in each round is low.