 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Deformation-Aware Local Features by Learning to Deform
Nov 20, 2021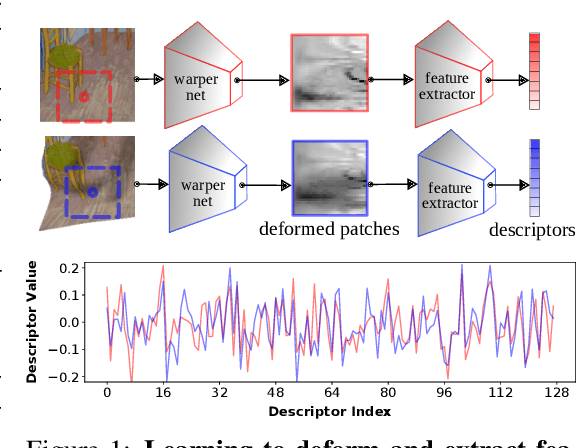
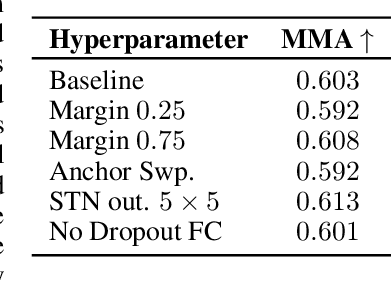

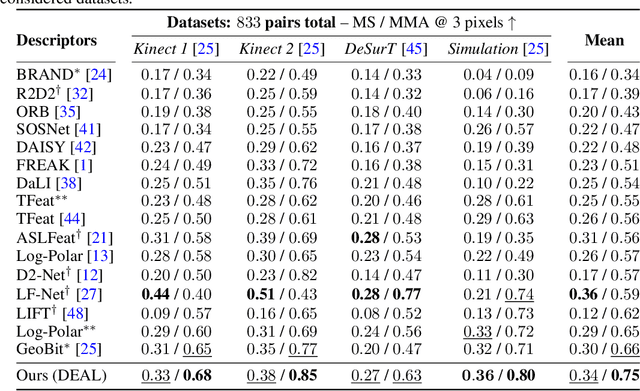
Despite the advances in extracting local features achieved by handcrafted and learning-based descriptors, they are still limited by the lack of invariance to non-rigid transformations. In this paper, we present a new approach to compute features from still images that are robust to non-rigid deformations to circumvent the problem of matching deformable surfaces and objects. Our deformation-aware local descriptor, named DEAL, leverages a polar sampling and a spatial transformer warping to provide invariance to rotation, scale, and image deformations. We train the model architecture end-to-end by applying isometric non-rigid deformations to objects in a simulated environment as guidance to provide highly discriminative local features. The experiments show that our method outperforms state-of-the-art handcrafted, learning-based image, and RGB-D descriptors in different datasets with both real and realistic synthetic deformable objects in still images. The source code and trained model of the descriptor are publicly available at https://www.verlab.dcc.ufmg.br/descriptors/neurips2021.
Creating and Reenacting Controllable 3D Humans with Differentiable Rendering
Oct 22, 2021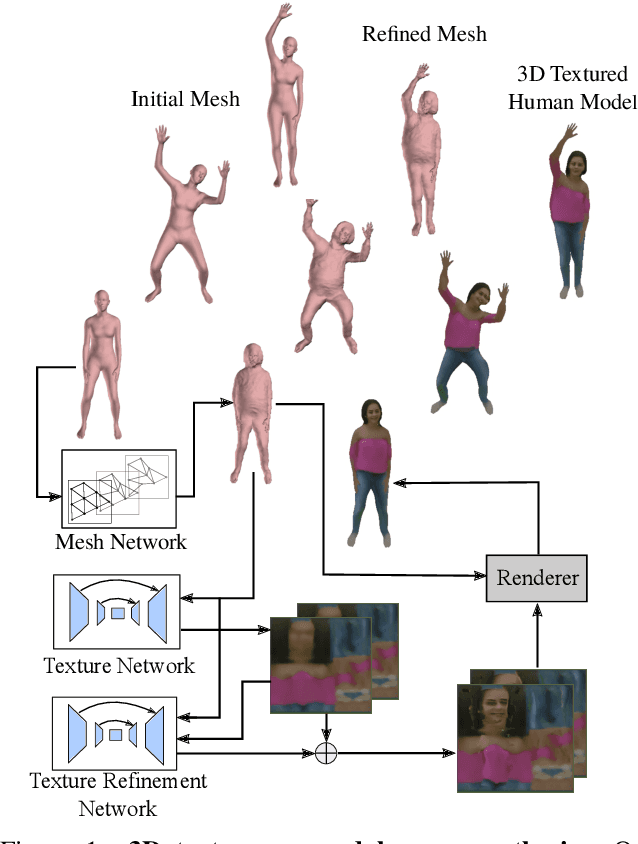
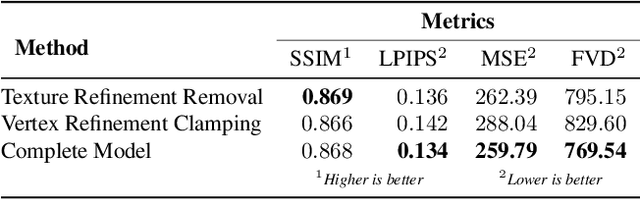
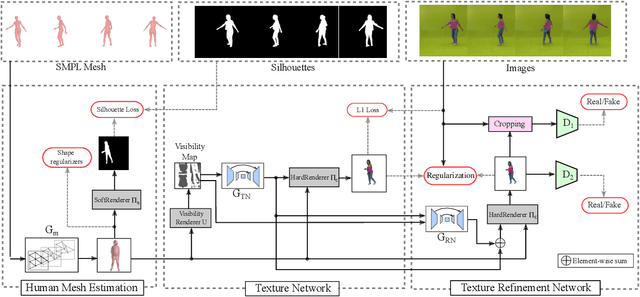

This paper proposes a new end-to-end neural rendering architecture to transfer appearance and reenact human actors. Our method leverages a carefully designed graph convolutional network (GCN) to model the human body manifold structure, jointly with differentiable rendering, to synthesize new videos of people in different contexts from where they were initially recorded. Unlike recent appearance transferring methods, our approach can reconstruct a fully controllable 3D texture-mapped model of a person, while taking into account the manifold structure from body shape and texture appearance in the view synthesis. Specifically, our approach models mesh deformations with a three-stage GCN trained in a self-supervised manner on rendered silhouettes of the human body. It also infers texture appearance with a convolutional network in the texture domain, which is trained in an adversarial regime to reconstruct human texture from rendered images of actors in different poses. Experiments on different videos show that our method successfully infers specific body deformations and avoid creating texture artifacts while achieving the best values for appearance in terms of Structural Similarity (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), Mean Squared Error (MSE), and Fr\'echet Video Distance (FVD). By taking advantages of both differentiable rendering and the 3D parametric model, our method is fully controllable, which allows controlling the human synthesis from both pose and rendering parameters. The source code is available at https://www.verlab.dcc.ufmg.br/retargeting-motion/wacv2022.
On Development and Evaluation of Retargeting Human Motion and Appearance in Monocular Videos
Mar 29, 2021
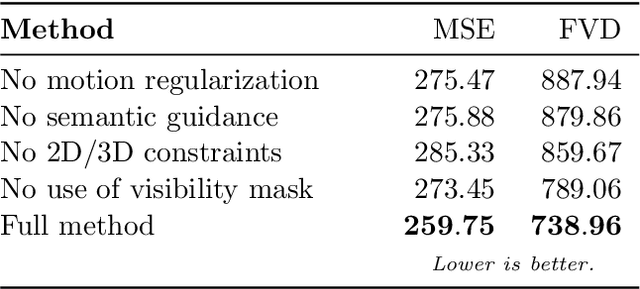
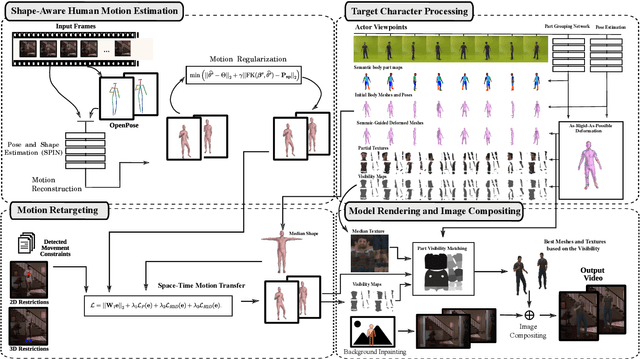
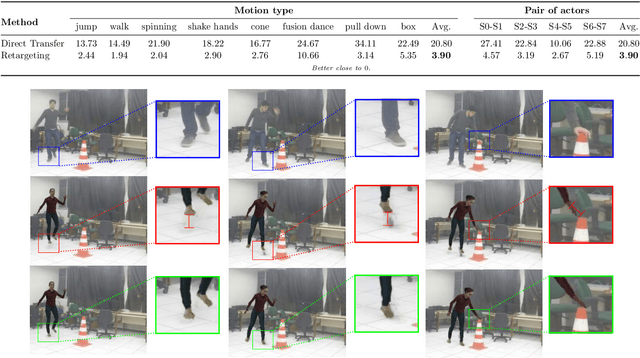
Transferring human motion and appearance between videos of human actors remains one of the key challenges in Computer Vision. Despite the advances from recent image-to-image translation approaches, there are several transferring contexts where most end-to-end learning-based retargeting methods still perform poorly. Transferring human appearance from one actor to another is only ensured when a strict setup has been complied, which is generally built considering their training regime's specificities. The contribution of this paper is two-fold: first, we propose a novel and high-performant approach based on a hybrid image-based rendering technique that exhibits competitive visual retargeting quality compared to state-of-the-art neural rendering approaches. The formulation leverages user body shape into the retargeting while considering physical constraints of the motion in 3D and the 2D image domain. We also present a new video retargeting benchmark dataset composed of different videos with annotated human motions to evaluate the task of synthesizing people's videos, which can be used as a common base to improve tracking the progress in the field. The dataset and its evaluation protocols are designed to evaluate retargeting methods in more general and challenging conditions. Our method is validated in several experiments, comprising publicly available videos of actors with different shapes, motion types and camera setups. The dataset and retargeting code are publicly available to the community at: https://www.verlab.dcc.ufmg.br/retargeting-motion.
Learning to dance: A graph convolutional adversarial network to generate realistic dance motions from audio
Nov 30, 2020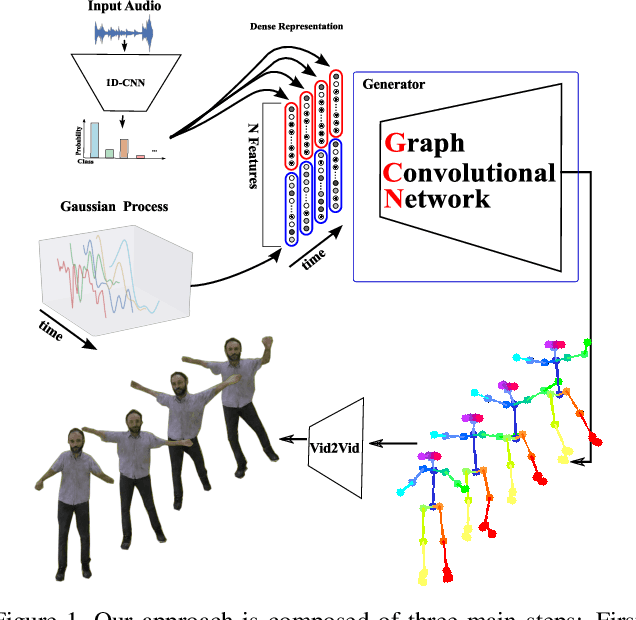
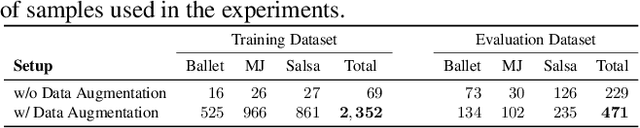
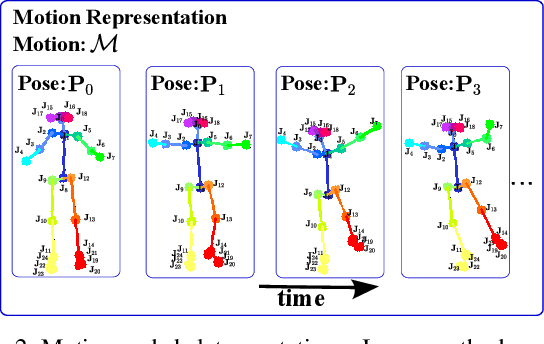
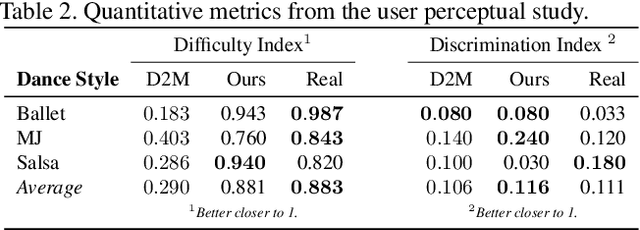
Synthesizing human motion through learning techniques is becoming an increasingly popular approach to alleviating the requirement of new data capture to produce animations. Learning to move naturally from music, i.e., to dance, is one of the more complex motions humans often perform effortlessly. Each dance movement is unique, yet such movements maintain the core characteristics of the dance style. Most approaches addressing this problem with classical convolutional and recursive neural models undergo training and variability issues due to the non-Euclidean geometry of the motion manifold structure.In this paper, we design a novel method based on graph convolutional networks to tackle the problem of automatic dance generation from audio information. Our method uses an adversarial learning scheme conditioned on the input music audios to create natural motions preserving the key movements of different music styles. We evaluate our method with three quantitative metrics of generative methods and a user study. The results suggest that the proposed GCN model outperforms the state-of-the-art dance generation method conditioned on music in different experiments. Moreover, our graph-convolutional approach is simpler, easier to be trained, and capable of generating more realistic motion styles regarding qualitative and different quantitative metrics. It also presented a visual movement perceptual quality comparable to real motion data.
Extending Maps with Semantic and Contextual Object Information for Robot Navigation: a Learning-Based Framework using Visual and Depth Cues
Mar 13, 2020
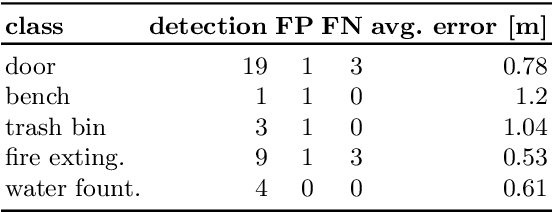
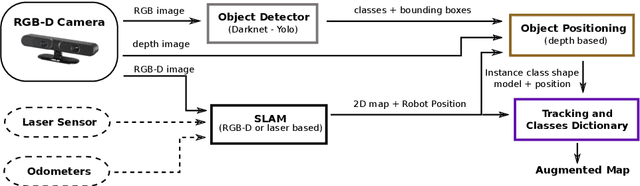
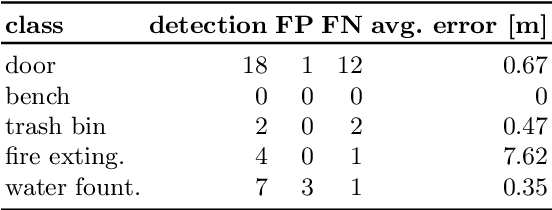
This paper addresses the problem of building augmented metric representations of scenes with semantic information from RGB-D images. We propose a complete framework to create an enhanced map representation of the environment with object-level information to be used in several applications such as human-robot interaction, assistive robotics, visual navigation, or in manipulation tasks. Our formulation leverages a CNN-based object detector (Yolo) with a 3D model-based segmentation technique to perform instance semantic segmentation, and to localize, identify, and track different classes of objects in the scene. The tracking and positioning of semantic classes is done with a dictionary of Kalman filters in order to combine sensor measurements over time and then providing more accurate maps. The formulation is designed to identify and to disregard dynamic objects in order to obtain a medium-term invariant map representation. The proposed method was evaluated with collected and publicly available RGB-D data sequences acquired in different indoor scenes. Experimental results show the potential of the technique to produce augmented semantic maps containing several objects (notably doors). We also provide to the community a dataset composed of annotated object classes (doors, fire extinguishers, benches, water fountains) and their positioning, as well as the source code as ROS packages.
Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
Jan 21, 2020
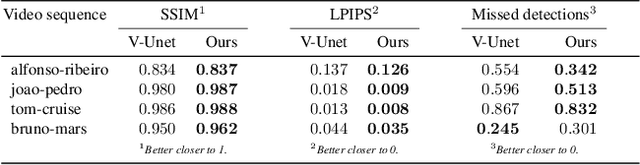

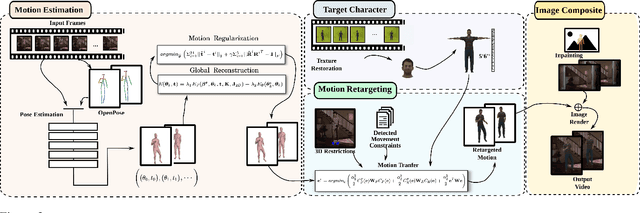
Creating plausible virtual actors from images of real actors remains one of the key challenges in computer vision and computer graphics. Marker-less human motion estimation and shape modeling from images in the wild bring this challenge to the fore. Although the recent advances on view synthesis and image-to-image translation, currently available formulations are limited to transfer solely style and do not take into account the character's motion and shape, which are by nature intermingled to produce plausible human forms. In this paper, we propose a unifying formulation for transferring appearance and retargeting human motion from monocular videos that regards all these aspects. Our method synthesizes new videos of people in a different context where they were initially recorded. Differently from recent appearance transferring methods, our approach takes into account body shape, appearance, and motion constraints. The evaluation is performed with several experiments using publicly available real videos containing hard conditions. Our method is able to transfer both human motion and appearance outperforming state-of-the-art methods, while preserving specific features of the motion that must be maintained (e.g., feet touching the floor, hands touching a particular object) and holding the best visual quality and appearance metrics such as Structural Similarity (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS).
Personalizing Fast-Forward Videos Based on Visual and Textual Features from Social Network
Dec 29, 2019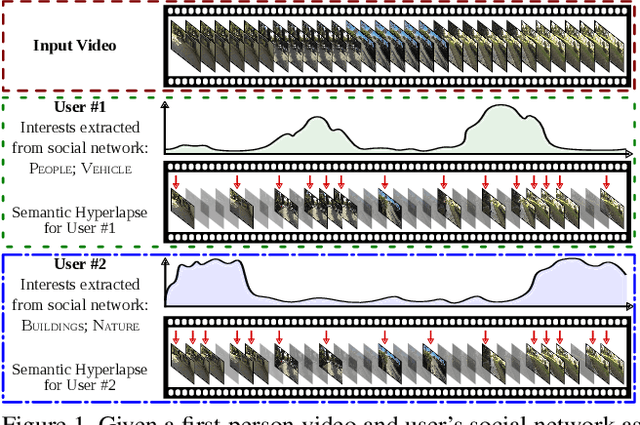
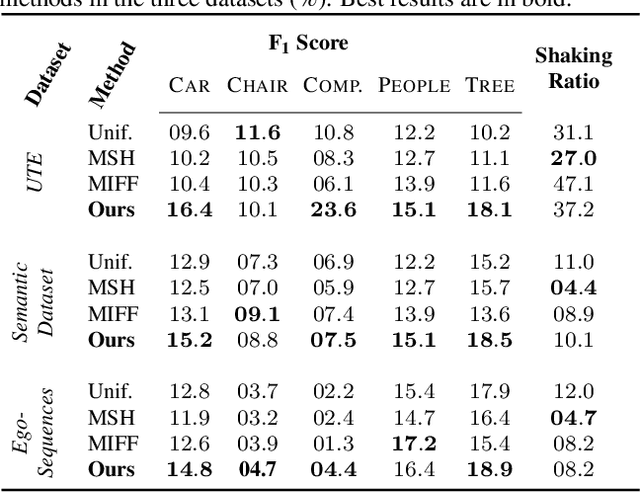
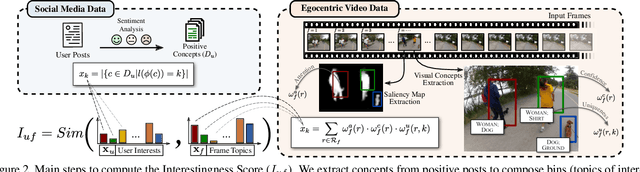
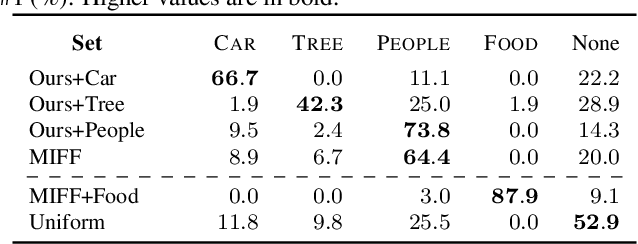
The growth of Social Networks has fueled the habit of people logging their day-to-day activities, and long First-Person Videos (FPVs) are one of the main tools in this new habit. Semantic-aware fast-forward methods are able to decrease the watch time and select meaningful moments, which is key to increase the chances of these videos being watched. However, these methods can not handle semantics in terms of personalization. In this work, we present a new approach to automatically creating personalized fast-forward videos for FPVs. Our approach explores the availability of text-centric data from the user's social networks such as status updates to infer her/his topics of interest and assigns scores to the input frames according to her/his preferences. Extensive experiments are conducted on three different datasets with simulated and real-world users as input, achieving an average F1 score of up to 12.8 percentage points higher than the best competitors. We also present a user study to demonstrate the effectiveness of our method.
A Two-Step Learning Method For Detecting Landmarks on Faces From Different Domains
Sep 12, 2018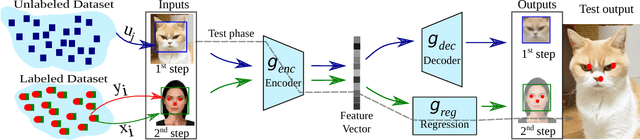

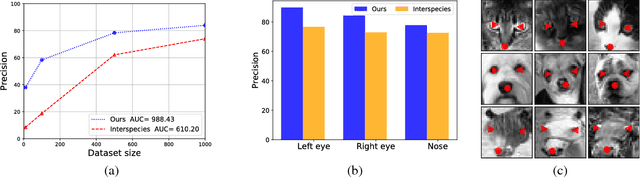
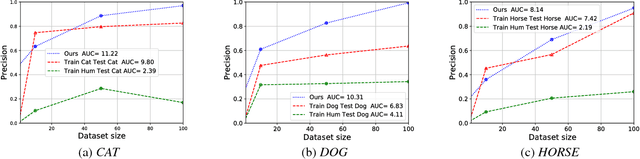
The detection of fiducial points on faces has significantly been favored by the rapid progress in the field of machine learning, in particular in the convolution networks. However, the accuracy of most of the detectors strongly depends on an enormous amount of annotated data. In this work, we present a domain adaptation approach based on a two-step learning to detect fiducial points on human and animal faces. We evaluate our method on three different datasets composed of different animal faces (cats, dogs, and horses). The experiments show that our method performs better than state of the art and can use few annotated data to leverage the detection of landmarks reducing the demand for large volume of annotated data.
Fast forwarding Egocentric Videos by Listening and Watching
Jun 12, 2018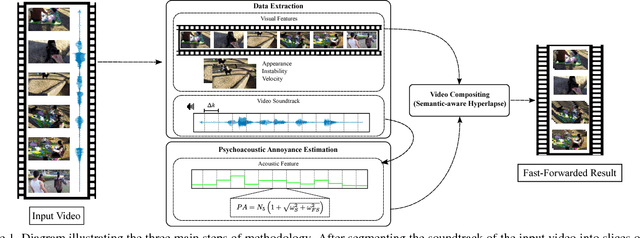
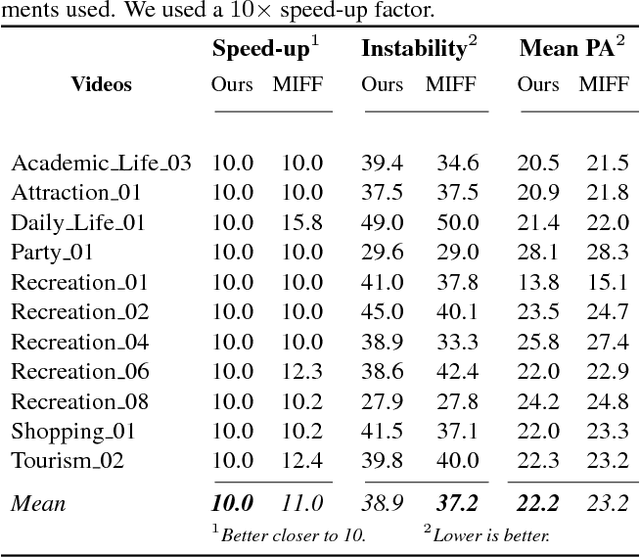
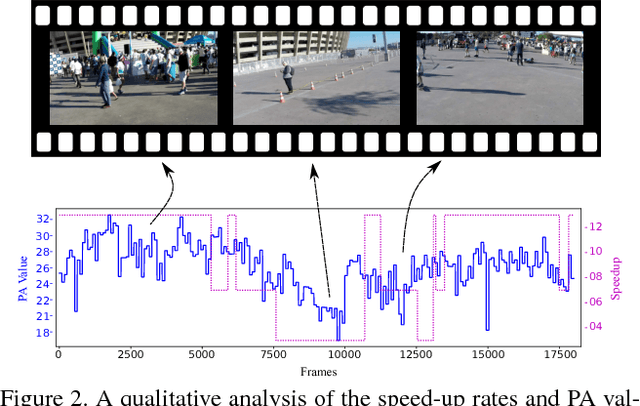
The remarkable technological advance in well-equipped wearable devices is pushing an increasing production of long first-person videos. However, since most of these videos have long and tedious parts, they are forgotten or never seen. Despite a large number of techniques proposed to fast-forward these videos by highlighting relevant moments, most of them are image based only. Most of these techniques disregard other relevant sensors present in the current devices such as high-definition microphones. In this work, we propose a new approach to fast-forward videos using psychoacoustic metrics extracted from the soundtrack. These metrics can be used to estimate the annoyance of a segment allowing our method to emphasize moments of sound pleasantness. The efficiency of our method is demonstrated through qualitative results and quantitative results as far as of speed-up and instability are concerned.
A Robust Indoor Scene Recognition Method based on Sparse Representation
Aug 24, 2017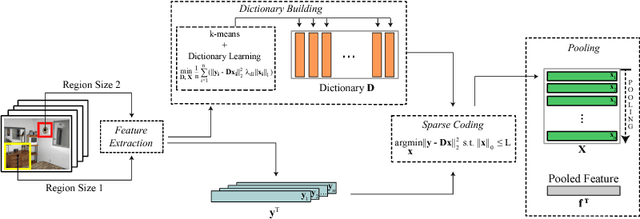
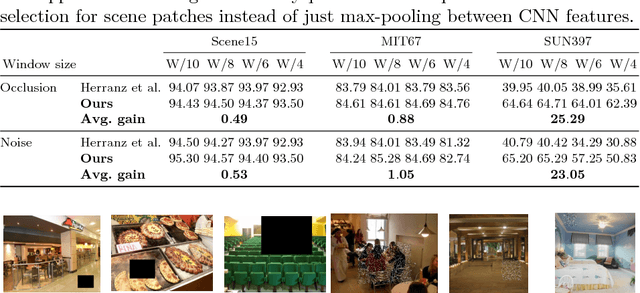

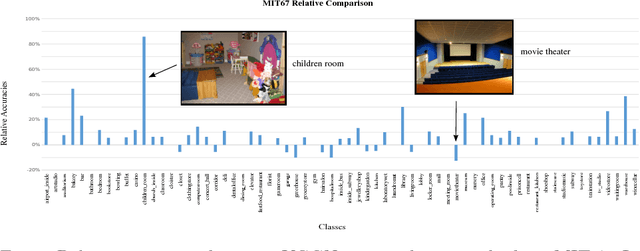
In this paper, we present a robust method for scene recognition, which leverages Convolutional Neural Networks (CNNs) features and Sparse Coding setting by creating a new representation of indoor scenes. Although CNNs highly benefited the fields of computer vision and pattern recognition, convolutional layers adjust weights on a global-approach, which might lead to losing important local details such as objects and small structures. Our proposed scene representation relies on both: global features that mostly refers to environment's structure, and local features that are sparsely combined to capture characteristics of common objects of a given scene. This new representation is based on fragments of the scene and leverages features extracted by CNNs. The experimental evaluation shows that the resulting representation outperforms previous scene recognition methods on Scene15 and MIT67 datasets, and performs competitively on SUN397, while being highly robust to perturbations in the input image such as noise and occlusion.