 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSA-Graphs: A Privacy-Preserving Structural Dataset for Child Sexual Abuse Research
Apr 08, 2026Child Sexual Abuse Imagery (CSAI) classification is an important yet challenging problem for computer vision research due to the strict legal and ethical restrictions that prevent the public sharing of CSAI datasets. This limitation hinders reproducibility and slows progress in developing automated methods. In this work, we introduce CSA-Graphs, a privacy-preserving structural dataset. Instead of releasing the original images, we provide structural representations that remove explicit visual content while preserving contextual information. CSA-Graphs includes two complementary graph-based modalities: scene graphs describing object relationships and skeleton graphs encoding human pose. Experiments show that both representations retain useful information for classifying CSAI, and that combining them further improves performance. This dataset enables broader research on computer vision methods for child safety while respecting legal and ethical constraints.
Human-Centric Perception for Child Sexual Abuse Imagery
Apr 02, 2026Law enforcement agencies and non-gonvernmental organizations handling reports of Child Sexual Abuse Imagery (CSAI) are overwhelmed by large volumes of data, requiring the aid of automation tools. However, defining sexual abuse in images of children is inherently challenging, encompassing sexually explicit activities and hints of sexuality conveyed by the individual's pose, or their attire. CSAI classification methods often rely on black-box approaches, targeting broad and abstract concepts such as pornography. Thus, our work is an in-depth exploration of tasks from the literature on Human-Centric Perception, across the domains of safe images, adult pornography, and CSAI, focusing on targets that enable more objective and explainable pipelines for CSAI classification in the future. We introduce the Body-Keypoint-Part Dataset (BKPD), gathering images of people from varying age groups and sexual explicitness to approximate the domain of CSAI, along with manually curated hierarchically structured labels for skeletal keypoints and bounding boxes for person and body parts, including head, chest, hip, and hands. We propose two methods, namely BKP-Association and YOLO-BKP, for simultaneous pose estimation and detection, with targets associated per individual for a comprehensive decomposed representation of each person. Our methods are benchmarked on COCO-Keypoints and COCO-HumanParts, as well as our human-centric dataset, achieving competitive results with models that jointly perform all tasks. Cross-domain ablation studies on BKPD and a case study on RCPD highlight the challenges posed by sexually explicit domains. Our study addresses previously unexplored targets in the CSAI domain, paving the way for novel research opportunities.
Neglected Risks: The Disturbing Reality of Children's Images in Datasets and the Urgent Call for Accountability
Apr 20, 2025Including children's images in datasets has raised ethical concerns, particularly regarding privacy, consent, data protection, and accountability. These datasets, often built by scraping publicly available images from the Internet, can expose children to risks such as exploitation, profiling, and tracking. Despite the growing recognition of these issues, approaches for addressing them remain limited. We explore the ethical implications of using children's images in AI datasets and propose a pipeline to detect and remove such images. As a use case, we built the pipeline on a Vision-Language Model under the Visual Question Answering task and tested it on the #PraCegoVer dataset. We also evaluate the pipeline on a subset of 100,000 images from the Open Images V7 dataset to assess its effectiveness in detecting and removing images of children. The pipeline serves as a baseline for future research, providing a starting point for more comprehensive tools and methodologies. While we leverage existing models trained on potentially problematic data, our goal is to expose and address this issue. We do not advocate for training or deploying such models, but instead call for urgent community reflection and action to protect children's rights. Ultimately, we aim to encourage the research community to exercise - more than an additional - care in creating new datasets and to inspire the development of tools to protect the fundamental rights of vulnerable groups, particularly children.
YOLOv7 for Mosquito Breeding Grounds Detection and Tracking
Oct 16, 2023



With the looming threat of climate change, neglected tropical diseases such as dengue, zika, and chikungunya have the potential to become an even greater global concern. Remote sensing technologies can aid in controlling the spread of Aedes Aegypti, the transmission vector of such diseases, by automating the detection and mapping of mosquito breeding sites, such that local entities can properly intervene. In this work, we leverage YOLOv7, a state-of-the-art and computationally efficient detection approach, to localize and track mosquito foci in videos captured by unmanned aerial vehicles. We experiment on a dataset released to the public as part of the ICIP 2023 grand challenge entitled Automatic Detection of Mosquito Breeding Grounds. We show that YOLOv7 can be directly applied to detect larger foci categories such as pools, tires, and water tanks and that a cheap and straightforward aggregation of frame-by-frame detection can incorporate time consistency into the tracking process.
Seeing without Looking: Analysis Pipeline for Child Sexual Abuse Datasets
Apr 29, 2022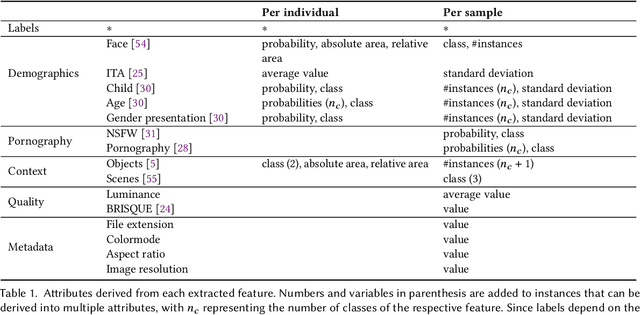
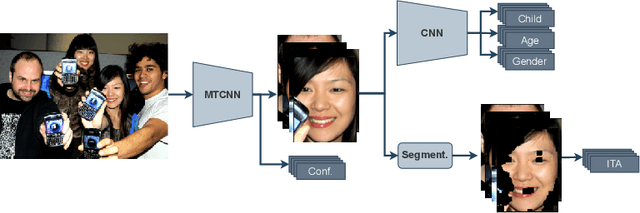
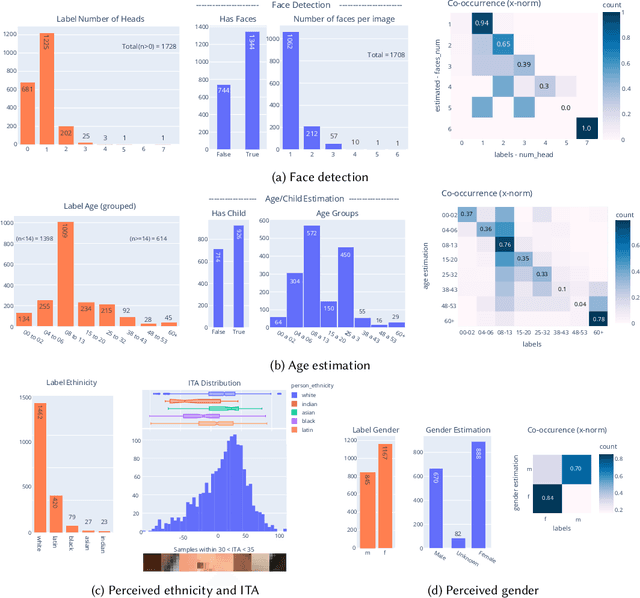
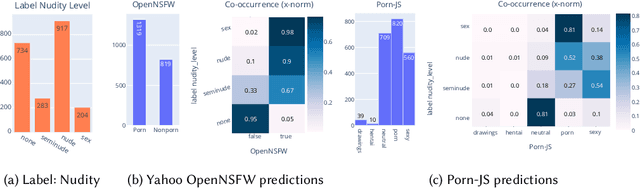
The online sharing and viewing of Child Sexual Abuse Material (CSAM) are growing fast, such that human experts can no longer handle the manual inspection. However, the automatic classification of CSAM is a challenging field of research, largely due to the inaccessibility of target data that is - and should forever be - private and in sole possession of law enforcement agencies. To aid researchers in drawing insights from unseen data and safely providing further understanding of CSAM images, we propose an analysis template that goes beyond the statistics of the dataset and respective labels. It focuses on the extraction of automatic signals, provided both by pre-trained machine learning models, e.g., object categories and pornography detection, as well as image metrics such as luminance and sharpness. Only aggregated statistics of sparse signals are provided to guarantee the anonymity of children and adolescents victimized. The pipeline allows filtering the data by applying thresholds to each specified signal and provides the distribution of such signals within the subset, correlations between signals, as well as a bias evaluation. We demonstrated our proposal on the Region-based annotated Child Pornography Dataset (RCPD), one of the few CSAM benchmarks in the literature, composed of over 2000 samples among regular and CSAM images, produced in partnership with Brazil's Federal Police. Although noisy and limited in several senses, we argue that automatic signals can highlight important aspects of the overall distribution of data, which is valuable for databases that can not be disclosed. Our goal is to safely publicize the characteristics of CSAM datasets, encouraging researchers to join the field and perhaps other institutions to provide similar reports on their benchmarks.
A Robust Indoor Scene Recognition Method based on Sparse Representation
Aug 24, 2017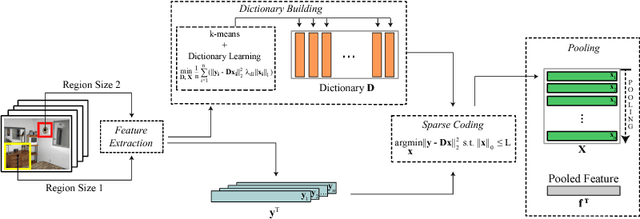
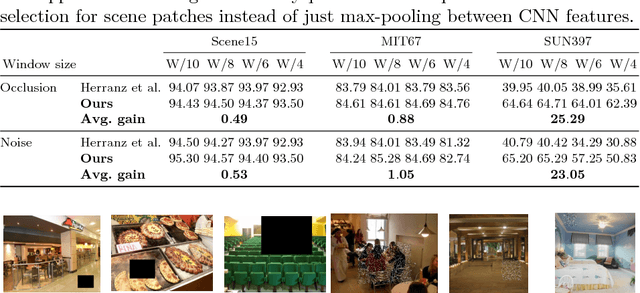

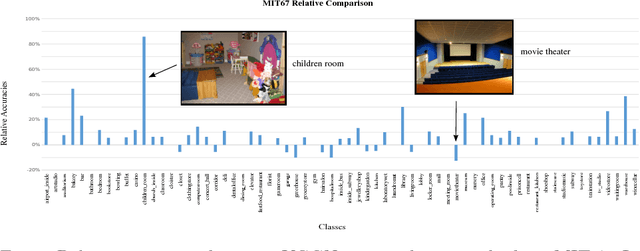
In this paper, we present a robust method for scene recognition, which leverages Convolutional Neural Networks (CNNs) features and Sparse Coding setting by creating a new representation of indoor scenes. Although CNNs highly benefited the fields of computer vision and pattern recognition, convolutional layers adjust weights on a global-approach, which might lead to losing important local details such as objects and small structures. Our proposed scene representation relies on both: global features that mostly refers to environment's structure, and local features that are sparsely combined to capture characteristics of common objects of a given scene. This new representation is based on fragments of the scene and leverages features extracted by CNNs. The experimental evaluation shows that the resulting representation outperforms previous scene recognition methods on Scene15 and MIT67 datasets, and performs competitively on SUN397, while being highly robust to perturbations in the input image such as noise and occlusion.