 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Spatial Invariance for Scalable Unsupervised Object Tracking
Nov 20, 2019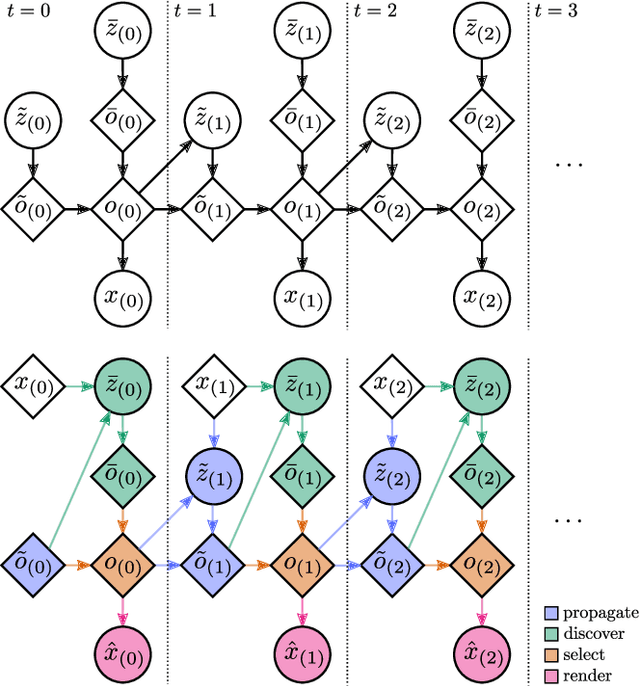
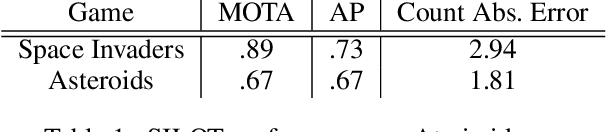
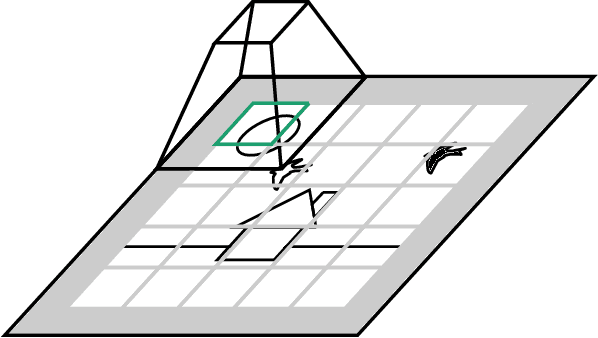
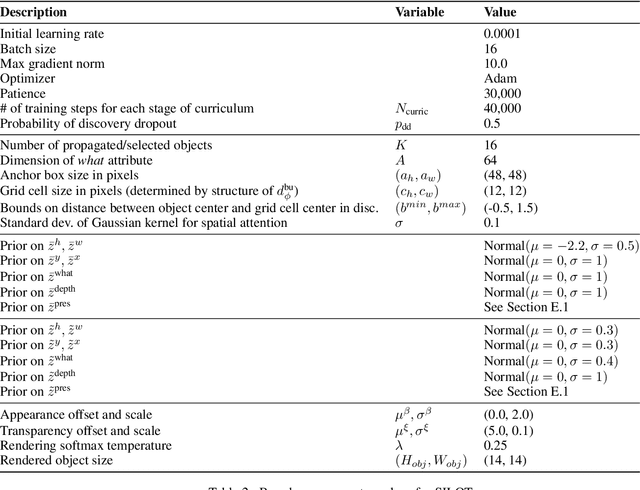
The ability to detect and track objects in the visual world is a crucial skill for any intelligent agent, as it is a necessary precursor to any object-level reasoning process. Moreover, it is important that agents learn to track objects without supervision (i.e. without access to annotated training videos) since this will allow agents to begin operating in new environments with minimal human assistance. The task of learning to discover and track objects in videos, which we call \textit{unsupervised object tracking}, has grown in prominence in recent years; however, most architectures that address it still struggle to deal with large scenes containing many objects. In the current work, we propose an architecture that scales well to the large-scene, many-object setting by employing spatially invariant computations (convolutions and spatial attention) and representations (a spatially local object specification scheme). In a series of experiments, we demonstrate a number of attractive features of our architecture; most notably, that it outperforms competing methods at tracking objects in cluttered scenes with many objects, and that it can generalize well to videos that are larger and/or contain more objects than videos encountered during training.
Self-supervised Learning of Distance Functions for Goal-Conditioned Reinforcement Learning
Jul 05, 2019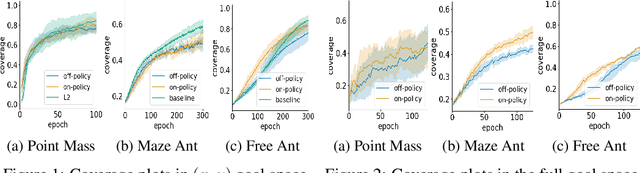
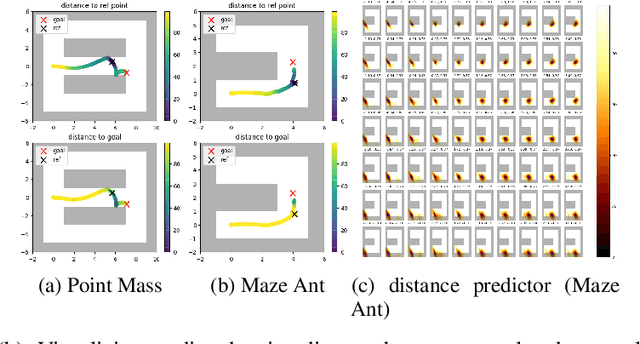
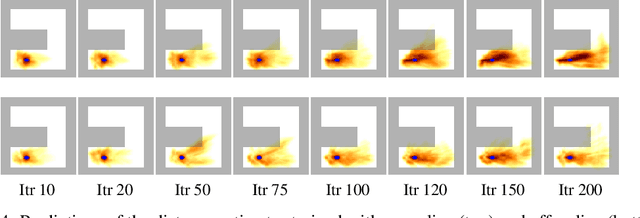
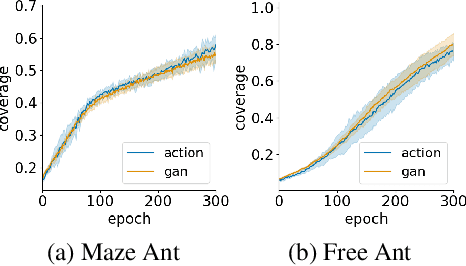
Goal-conditioned policies are used in order to break down complex reinforcement learning (RL) problems by using subgoals, which can be defined either in state space or in a latent feature space. This can increase the efficiency of learning by using a curriculum, and also enables simultaneous learning and generalization across goals. A crucial requirement of goal-conditioned policies is to be able to determine whether the goal has been achieved. Having a notion of distance to a goal is thus a crucial component of this approach. However, it is not straightforward to come up with an appropriate distance, and in some tasks, the goal space may not even be known a priori. In this work we learn a distance-to-goal estimate which is computed in terms of the number of actions that would need to be carried out in a self-supervised approach. Our method solves complex tasks without prior domain knowledge in the online setting in three different scenarios in the context of goal-conditioned policies a) the goal space is the same as the state space b) the goal space is given but an appropriate distance is unknown and c) the state space is accessible, but only a subset of the state space represents desired goals, and this subset is known a priori. We also propose a goal-generation mechanism as a secondary contribution.
BanditSum: Extractive Summarization as a Contextual Bandit
Sep 25, 2018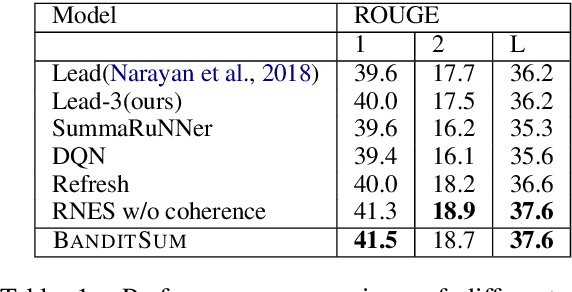
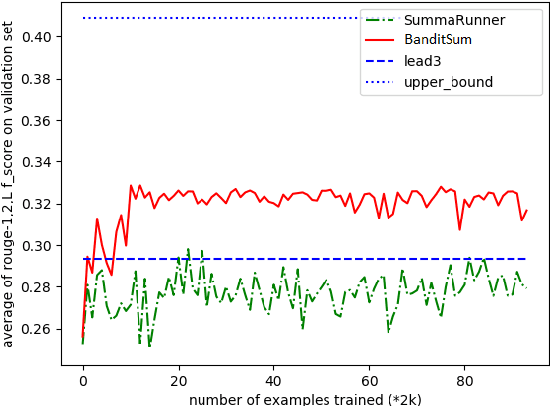
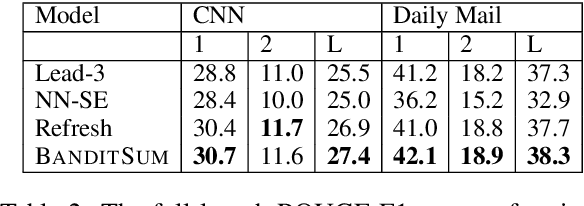
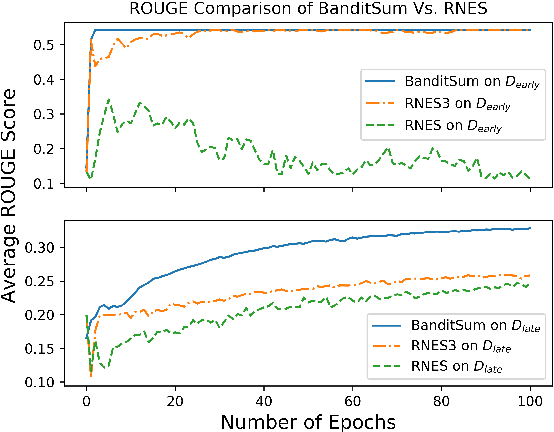
In this work, we propose a novel method for training neural networks to perform single-document extractive summarization without heuristically-generated extractive labels. We call our approach BanditSum as it treats extractive summarization as a contextual bandit (CB) problem, where the model receives a document to summarize (the context), and chooses a sequence of sentences to include in the summary (the action). A policy gradient reinforcement learning algorithm is used to train the model to select sequences of sentences that maximize ROUGE score. We perform a series of experiments demonstrating that BanditSum is able to achieve ROUGE scores that are better than or comparable to the state-of-the-art for extractive summarization, and converges using significantly fewer update steps than competing approaches. In addition, we show empirically that BanditSum performs significantly better than competing approaches when good summary sentences appear late in the source document.
Sequential Coordination of Deep Models for Learning Visual Arithmetic
Sep 13, 2018

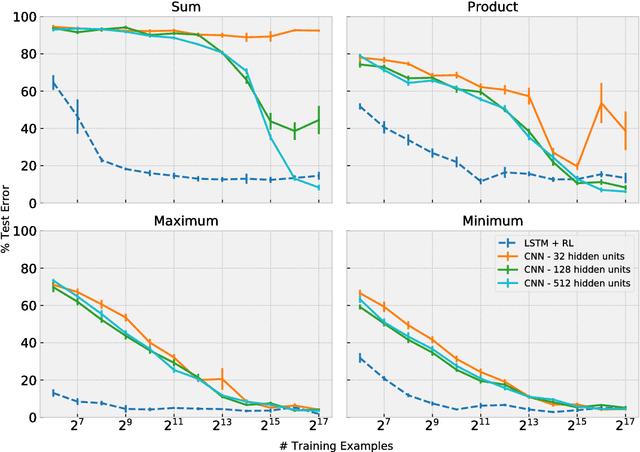
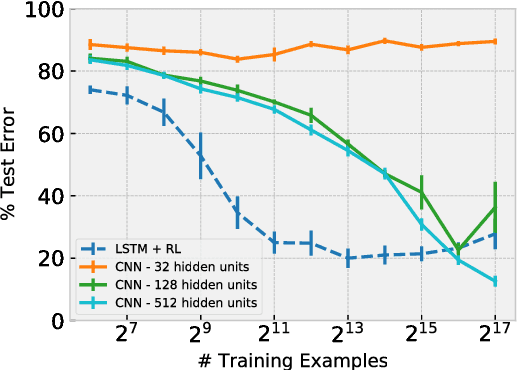
Achieving machine intelligence requires a smooth integration of perception and reasoning, yet models developed to date tend to specialize in one or the other; sophisticated manipulation of symbols acquired from rich perceptual spaces has so far proved elusive. Consider a visual arithmetic task, where the goal is to carry out simple arithmetical algorithms on digits presented under natural conditions (e.g. hand-written, placed randomly). We propose a two-tiered architecture for tackling this problem. The lower tier consists of a heterogeneous collection of information processing modules, which can include pre-trained deep neural networks for locating and extracting characters from the image, as well as modules performing symbolic transformations on the representations extracted by perception. The higher tier consists of a controller, trained using reinforcement learning, which coordinates the modules in order to solve the high-level task. For instance, the controller may learn in what contexts to execute the perceptual networks and what symbolic transformations to apply to their outputs. The resulting model is able to solve a variety of tasks in the visual arithmetic domain, and has several advantages over standard, architecturally homogeneous feedforward networks including improved sample efficiency.