 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence as Strange Intelligence: Against Linear Models of Intelligence
Feb 04, 2026We endorse and expand upon Susan Schneider's critique of the linear model of AI progress and introduce two novel concepts: "familiar intelligence" and "strange intelligence". AI intelligence is likely to be strange intelligence, defying familiar patterns of ability and inability, combining superhuman capacities in some domains with subhuman performance in other domains, and even within domains sometimes combining superhuman insight with surprising errors that few humans would make. We develop and defend a nonlinear model of intelligence on which "general intelligence" is not a unified capacity but instead the ability to achieve a broad range of goals in a broad range of environments, in a manner that defies nonarbitrary reduction to a single linear quantity. We conclude with implications for adversarial testing approaches to evaluating AI capacities. If AI is strange intelligence, we should expect that even the most capable systems will sometimes fail in seemingly obvious tasks. On a nonlinear model of AI intelligence, such errors on their own do not demonstrate a system's lack of outstanding general intelligence. Conversely, excellent performance on one type of task, such as an IQ test, cannot warrant assumptions of broad capacities beyond that task domain.
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
Aug 22, 2023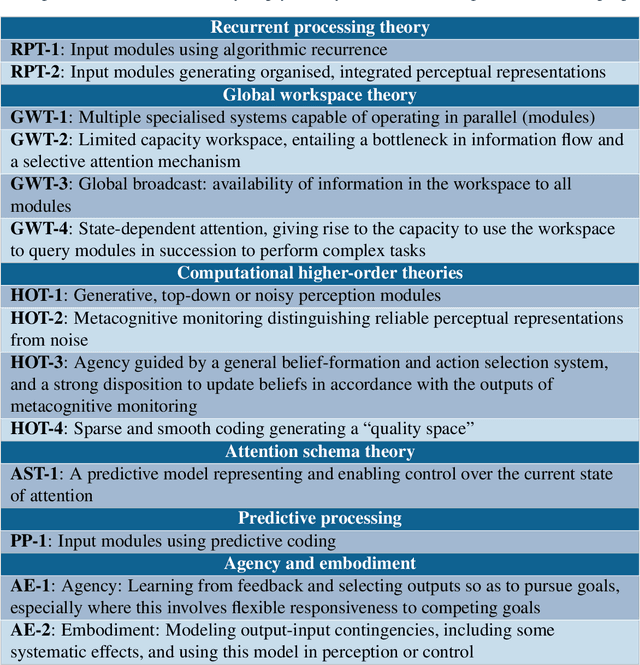
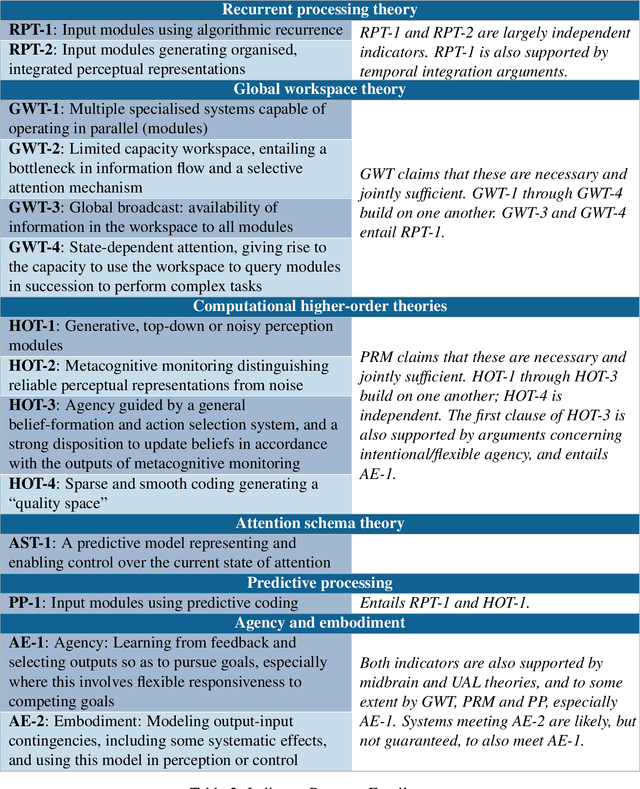
Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern. This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness. We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher-order theories, predictive processing, and attention schema theory. From these theories we derive "indicator properties" of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties. We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.
Creating a Large Language Model of a Philosopher
Feb 02, 2023Can large language models be trained to produce philosophical texts that are difficult to distinguish from texts produced by human philosophers? To address this question, we fine-tuned OpenAI's GPT-3 with the works of philosopher Daniel C. Dennett as additional training data. To explore the Dennett model, we asked the real Dennett ten philosophical questions and then posed the same questions to the language model, collecting four responses for each question without cherry-picking. We recruited 425 participants to distinguish Dennett's answer from the four machine-generated answers. Experts on Dennett's work (N = 25) succeeded 51% of the time, above the chance rate of 20% but short of our hypothesized rate of 80% correct. For two of the ten questions, the language model produced at least one answer that experts selected more frequently than Dennett's own answer. Philosophy blog readers (N = 302) performed similarly to the experts, while ordinary research participants (N = 98) were near chance distinguishing GPT-3's responses from those of an "actual human philosopher".