 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTune: A Research Platform for Distributed Model Selection and Training
Jul 13, 2018


Modern machine learning algorithms are increasingly computationally demanding, requiring specialized hardware and distributed computation to achieve high performance in a reasonable time frame. Many hyperparameter search algorithms have been proposed for improving the efficiency of model selection, however their adaptation to the distributed compute environment is often ad-hoc. We propose Tune, a unified framework for model selection and training that provides a narrow-waist interface between training scripts and search algorithms. We show that this interface meets the requirements for a broad range of hyperparameter search algorithms, allows straightforward scaling of search to large clusters, and simplifies algorithm implementation. We demonstrate the implementation of several state-of-the-art hyperparameter search algorithms in Tune. Tune is available at http://ray.readthedocs.io/en/latest/tune.html.
RLlib: Abstractions for Distributed Reinforcement Learning
Jun 29, 2018

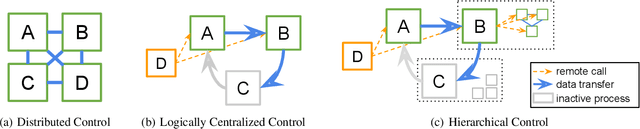

Reinforcement learning (RL) algorithms involve the deep nesting of highly irregular computation patterns, each of which typically exhibits opportunities for distributed computation. We argue for distributing RL components in a composable way by adapting algorithms for top-down hierarchical control, thereby encapsulating parallelism and resource requirements within short-running compute tasks. We demonstrate the benefits of this principle through RLlib: a library that provides scalable software primitives for RL. These primitives enable a broad range of algorithms to be implemented with high performance, scalability, and substantial code reuse. RLlib is available at https://rllib.io/.