 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Gradient Descent Converges to Flat Minima for Nonconvex Matrix Factorization
Feb 24, 2021
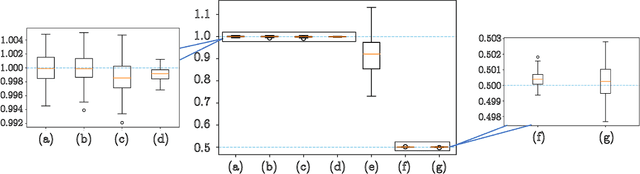
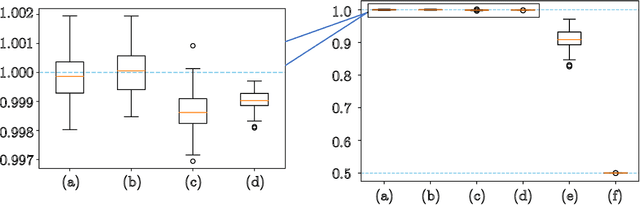
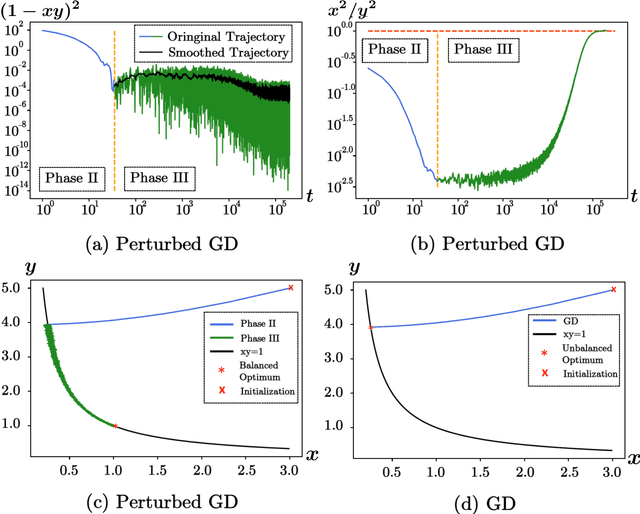
Numerous empirical evidences have corroborated the importance of noise in nonconvex optimization problems. The theory behind such empirical observations, however, is still largely unknown. This paper studies this fundamental problem through investigating the nonconvex rectangular matrix factorization problem, which has infinitely many global minima due to rotation and scaling invariance. Hence, gradient descent (GD) can converge to any optimum, depending on the initialization. In contrast, we show that a perturbed form of GD with an arbitrary initialization converges to a global optimum that is uniquely determined by the injected noise. Our result implies that the noise imposes implicit bias towards certain optima. Numerical experiments are provided to support our theory.
Bayesian Optimization of Risk Measures
Jul 16, 2020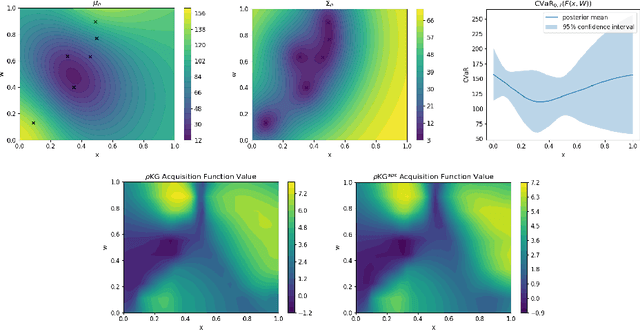
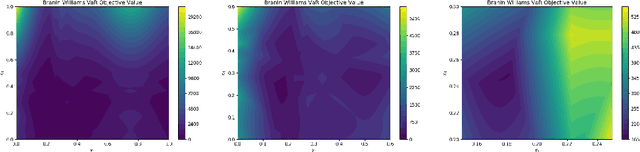
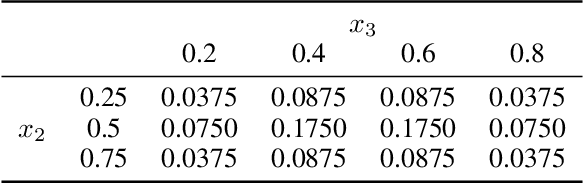
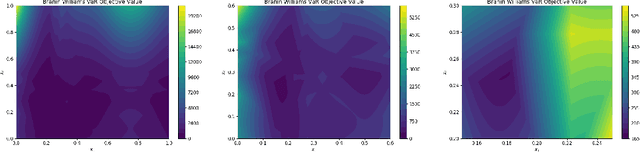
We consider Bayesian optimization of objective functions of the form $\rho[ F(x, W) ]$, where $F$ is a black-box expensive-to-evaluate function and $\rho$ denotes either the VaR or CVaR risk measure, computed with respect to the randomness induced by the environmental random variable $W$. Such problems arise in decision making under uncertainty, such as in portfolio optimization and robust systems design. We propose a family of novel Bayesian optimization algorithms that exploit the structure of the objective function to substantially improve sampling efficiency. Instead of modeling the objective function directly as is typical in Bayesian optimization, these algorithms model $F$ as a Gaussian process, and use the implied posterior on the objective function to decide which points to evaluate. We demonstrate the effectiveness of our approach in a variety of numerical experiments.
Towards Understanding the Importance of Shortcut Connections in Residual Networks
Sep 11, 2019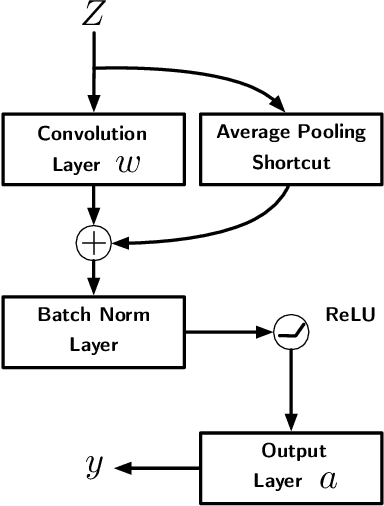

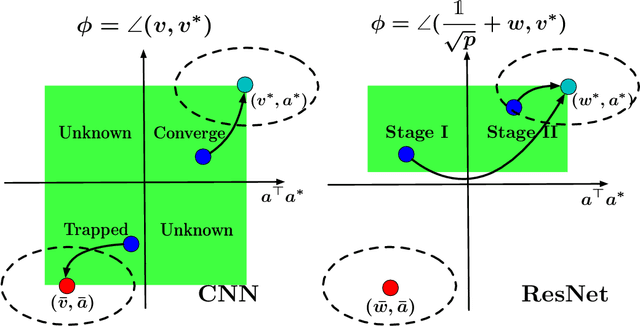
Residual Network (ResNet) is undoubtedly a milestone in deep learning. ResNet is equipped with shortcut connections between layers, and exhibits efficient training using simple first order algorithms. Despite of the great empirical success, the reason behind is far from being well understood. In this paper, we study a two-layer non-overlapping convolutional ResNet. Training such a network requires solving a non-convex optimization problem with a spurious local optimum. We show, however, that gradient descent combined with proper normalization, avoids being trapped by the spurious local optimum, and converges to a global optimum in polynomial time, when the weight of the first layer is initialized at 0, and that of the second layer is initialized arbitrarily in a ball. Numerical experiments are provided to support our theory.
Towards Understanding the Importance of Noise in Training Neural Networks
Sep 07, 2019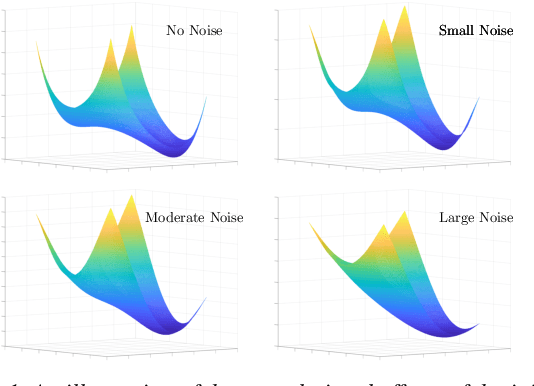
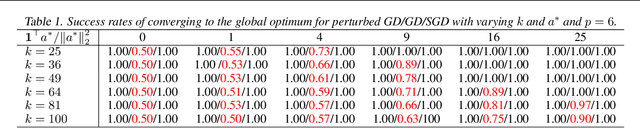
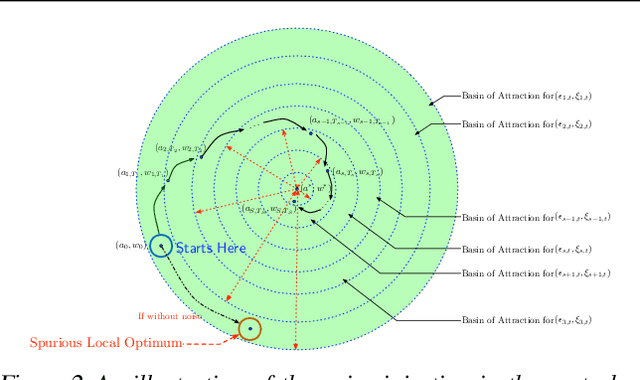
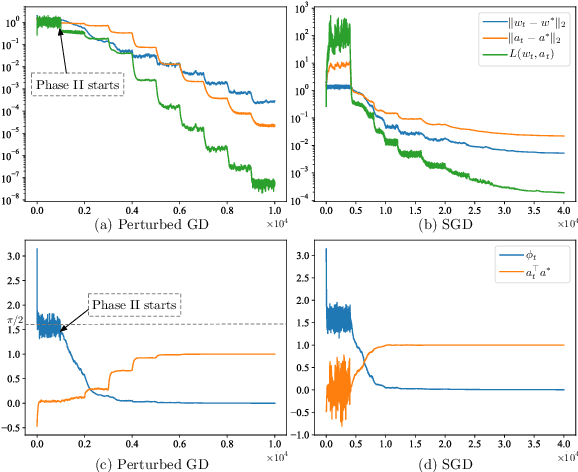
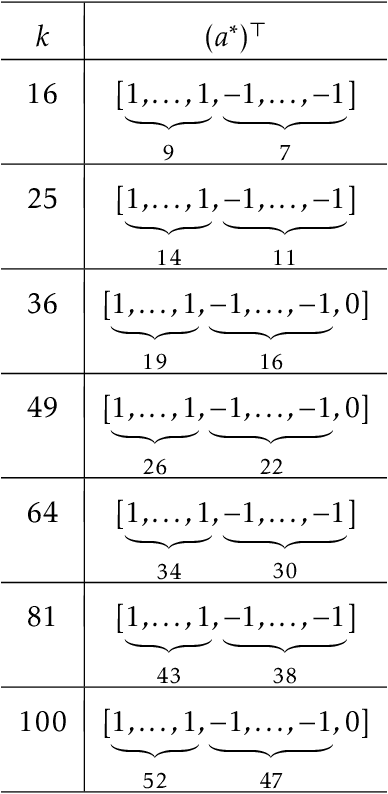
Numerous empirical evidence has corroborated that the noise plays a crucial rule in effective and efficient training of neural networks. The theory behind, however, is still largely unknown. This paper studies this fundamental problem through training a simple two-layer convolutional neural network model. Although training such a network requires solving a nonconvex optimization problem with a spurious local optimum and a global optimum, we prove that perturbed gradient descent and perturbed mini-batch stochastic gradient algorithms in conjunction with noise annealing is guaranteed to converge to a global optimum in polynomial time with arbitrary initialization. This implies that the noise enables the algorithm to efficiently escape from the spurious local optimum. Numerical experiments are provided to support our theory.
Toward Deeper Understanding of Nonconvex Stochastic Optimization with Momentum using Diffusion Approximations
Oct 01, 2018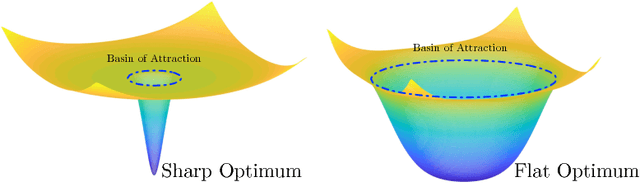

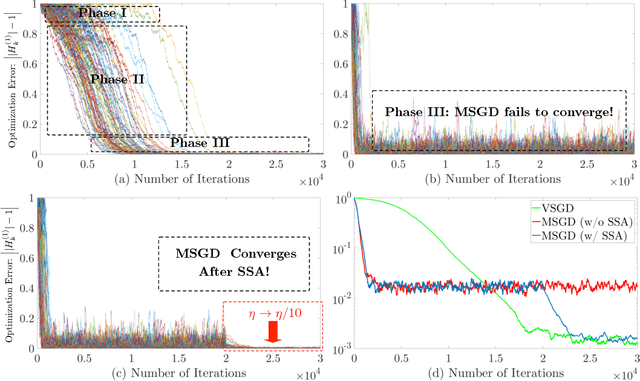

Momentum Stochastic Gradient Descent (MSGD) algorithm has been widely applied to many nonconvex optimization problems in machine learning. Popular examples include training deep neural networks, dimensionality reduction, and etc. Due to the lack of convexity and the extra momentum term, the optimization theory of MSGD is still largely unknown. In this paper, we study this fundamental optimization algorithm based on the so-called "strict saddle problem." By diffusion approximation type analysis, our study shows that the momentum helps escape from saddle points, but hurts the convergence within the neighborhood of optima (if without the step size annealing). Our theoretical discovery partially corroborates the empirical success of MSGD in training deep neural networks. Moreover, our analysis applies the martingale method and "Fixed-State-Chain" method from the stochastic approximation literature, which are of independent interest.
Towards Understanding Acceleration Tradeoff between Momentum and Asynchrony in Nonconvex Stochastic Optimization
Oct 01, 2018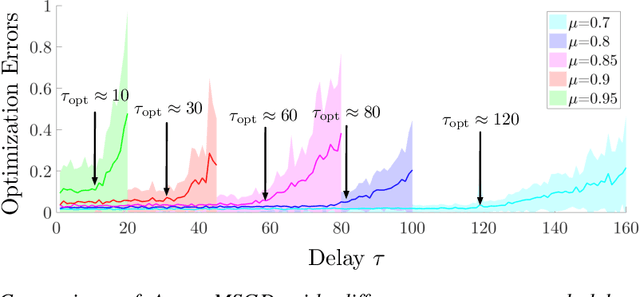
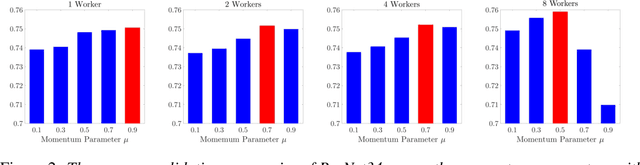
Asynchronous momentum stochastic gradient descent algorithms (Async-MSGD) is one of the most popular algorithms in distributed machine learning. However, its convergence properties for these complicated nonconvex problems is still largely unknown, because of the current technical limit. Therefore, in this paper, we propose to analyze the algorithm through a simpler but nontrivial nonconvex problem - streaming PCA, which helps us to understand Aync-MSGD better even for more general problems. Specifically, we establish the asymptotic rate of convergence of Async-MSGD for streaming PCA by diffusion approximation. Our results indicate a fundamental tradeoff between asynchrony and momentum: To ensure convergence and acceleration through asynchrony, we have to reduce the momentum (compared with Sync-MSGD). To the best of our knowledge, this is the first theoretical attempt on understanding Async-MSGD for distributed nonconvex stochastic optimization. Numerical experiments on both streaming PCA and training deep neural networks are provided to support our findings for Async-MSGD.