 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmre Çakır
Multi-task Regularization Based on Infrequent Classes for Audio Captioning
Jul 09, 2020
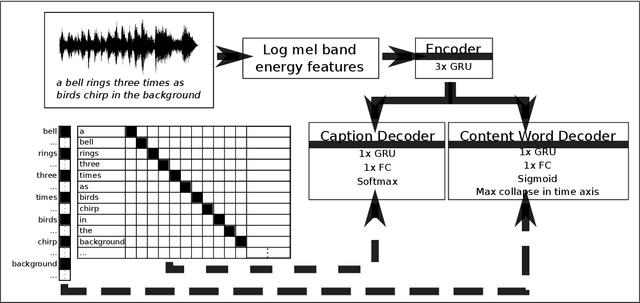
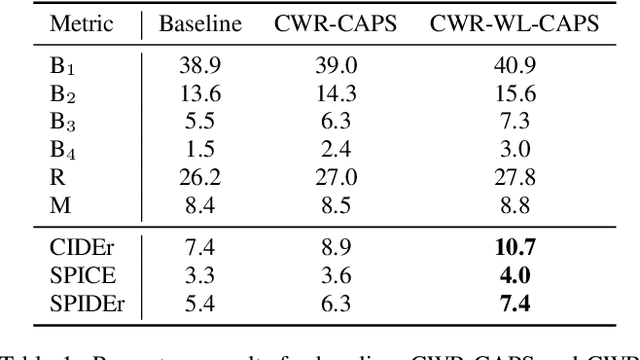
Audio captioning is a multi-modal task, focusing on using natural language for describing the contents of general audio. Most audio captioning methods are based on deep neural networks, employing an encoder-decoder scheme and a dataset with audio clips and corresponding natural language descriptions (i.e. captions). A significant challenge for audio captioning is the distribution of words in the captions: some words are very frequent but acoustically non-informative, i.e. the function words (e.g. "a", "the"), and other words are infrequent but informative, i.e. the content words (e.g. adjectives, nouns). In this paper we propose two methods to mitigate this class imbalance problem. First, in an autoencoder setting for audio captioning, we weigh each word's contribution to the training loss inversely proportional to its number of occurrences in the whole dataset. Secondly, in addition to multi-class, word-level audio captioning task, we define a multi-label side task based on clip-level content word detection by training a separate decoder. We use the loss from the second task to regularize the jointly trained encoder for the audio captioning task. We evaluate our method using Clotho, a recently published, wide-scale audio captioning dataset, and our results show an increase of 37\% relative improvement with SPIDEr metric over the baseline method.
End-to-End Polyphonic Sound Event Detection Using Convolutional Recurrent Neural Networks with Learned Time-Frequency Representation Input
May 09, 2018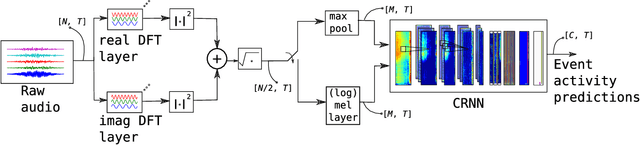
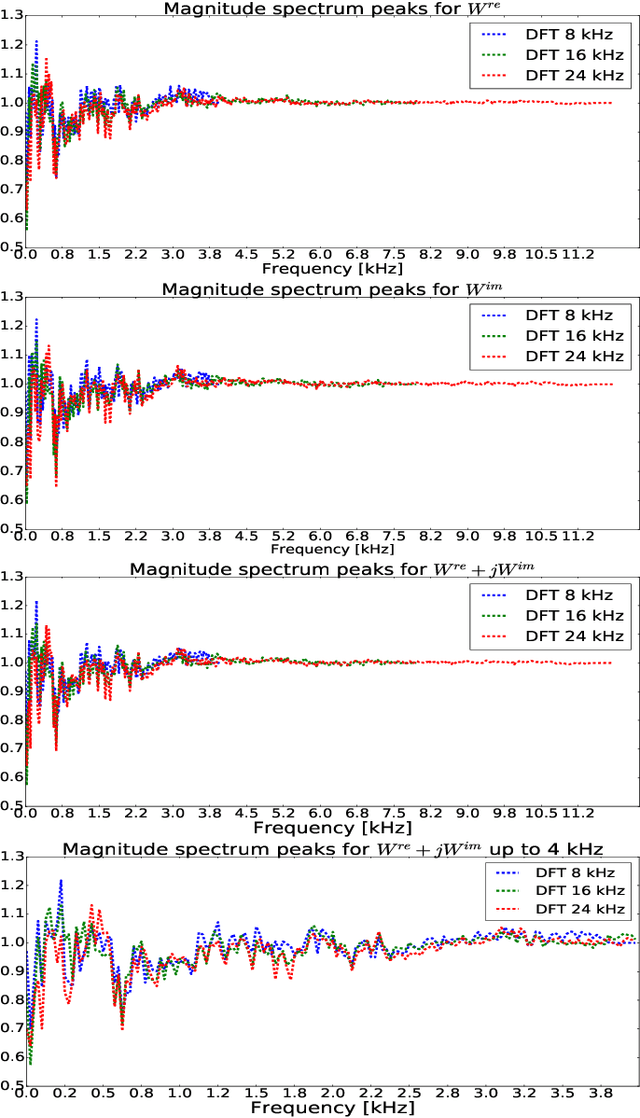
Sound event detection systems typically consist of two stages: extracting hand-crafted features from the raw audio waveform, and learning a mapping between these features and the target sound events using a classifier. Recently, the focus of sound event detection research has been mostly shifted to the latter stage using standard features such as mel spectrogram as the input for classifiers such as deep neural networks. In this work, we utilize end-to-end approach and propose to combine these two stages in a single deep neural network classifier. The feature extraction over the raw waveform is conducted by a feedforward layer block, whose parameters are initialized to extract the time-frequency representations. The feature extraction parameters are updated during training, resulting with a representation that is optimized for the specific task. This feature extraction block is followed by (and jointly trained with) a convolutional recurrent network, which has recently given state-of-the-art results in many sound recognition tasks. The proposed system does not outperform a convolutional recurrent network with fixed hand-crafted features. The final magnitude spectrum characteristics of the feature extraction block parameters indicate that the most relevant information for the given task is contained in 0 - 3 kHz frequency range, and this is also supported by the empirical results on the SED performance.
Stacked Convolutional and Recurrent Neural Networks for Bird Audio Detection
Jun 07, 2017
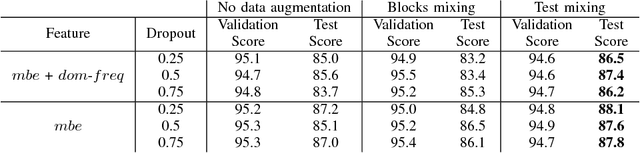
This paper studies the detection of bird calls in audio segments using stacked convolutional and recurrent neural networks. Data augmentation by blocks mixing and domain adaptation using a novel method of test mixing are proposed and evaluated in regard to making the method robust to unseen data. The contributions of two kinds of acoustic features (dominant frequency and log mel-band energy) and their combinations are studied in the context of bird audio detection. Our best achieved AUC measure on five cross-validations of the development data is 95.5% and 88.1% on the unseen evaluation data.
Convolutional Recurrent Neural Networks for Polyphonic Sound Event Detection
Feb 21, 2017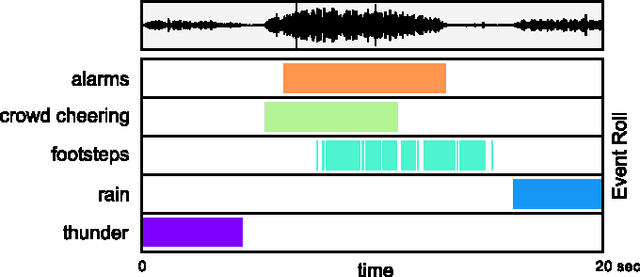
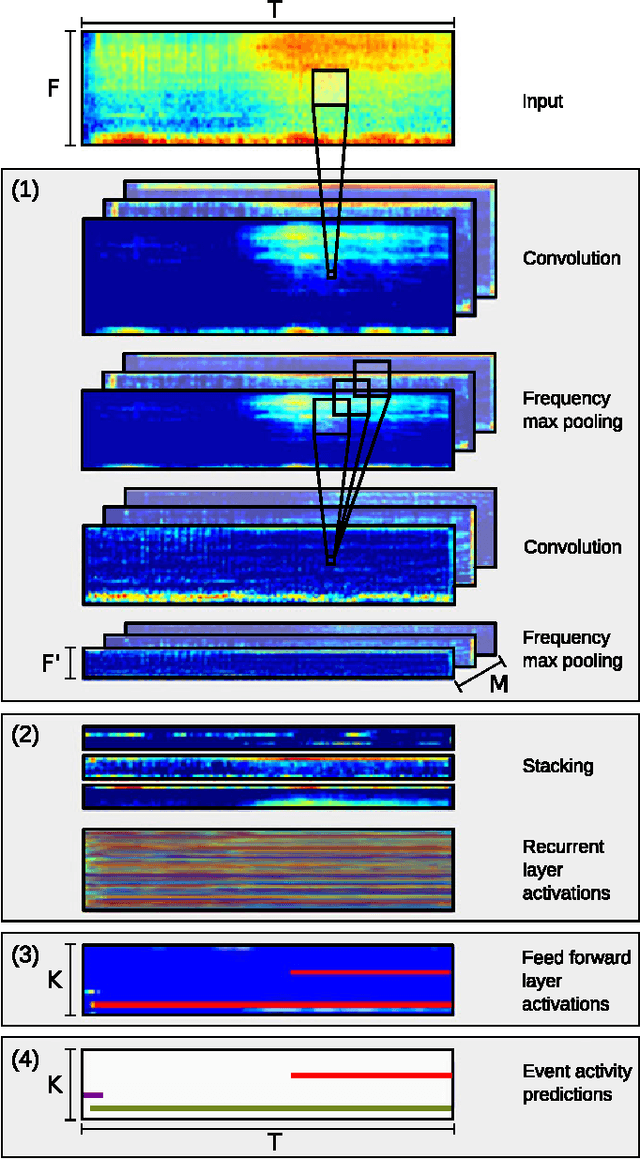
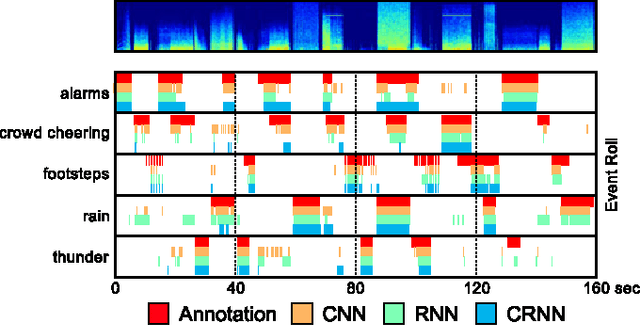
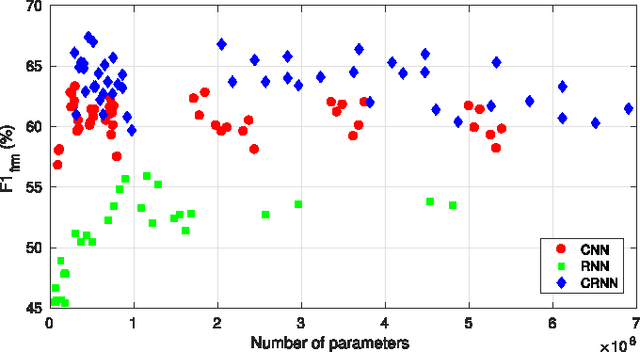
Sound events often occur in unstructured environments where they exhibit wide variations in their frequency content and temporal structure. Convolutional neural networks (CNN) are able to extract higher level features that are invariant to local spectral and temporal variations. Recurrent neural networks (RNNs) are powerful in learning the longer term temporal context in the audio signals. CNNs and RNNs as classifiers have recently shown improved performances over established methods in various sound recognition tasks. We combine these two approaches in a Convolutional Recurrent Neural Network (CRNN) and apply it on a polyphonic sound event detection task. We compare the performance of the proposed CRNN method with CNN, RNN, and other established methods, and observe a considerable improvement for four different datasets consisting of everyday sound events.